Download as PDF, PPTX




























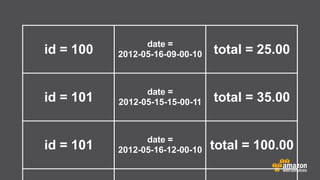
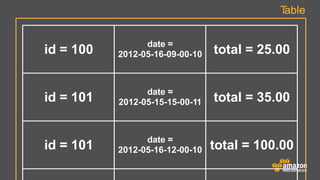




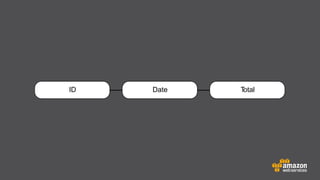
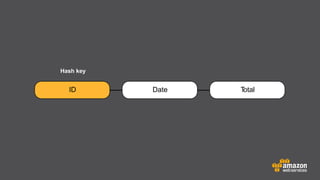
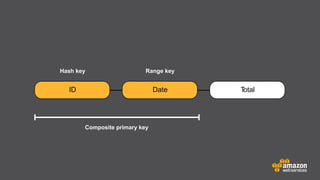
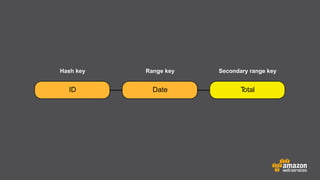

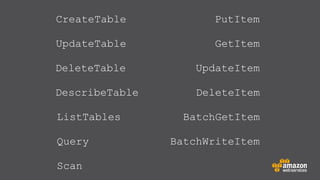












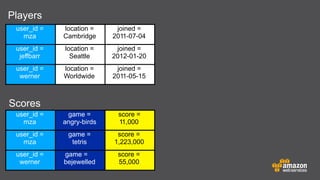

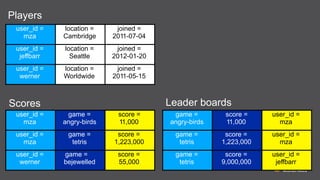









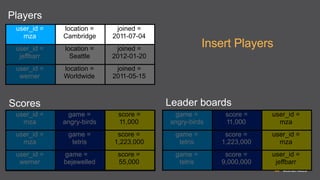

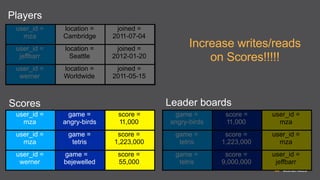
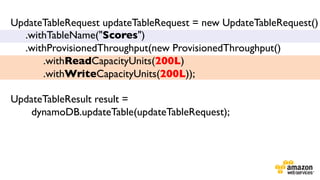





The document provides an extensive overview of Amazon DynamoDB, a managed NoSQL database service that offers seamless scalability, consistent performance, and a flexible data model without requiring a formal schema. It covers various aspects like data partitioning, provisioned throughput, and API interactions for creating and managing tables, as well as querying data. Additionally, it discusses pricing tiers, monitoring, and integration with other AWS services for optimal performance.


































































