1. はじめに
対話データ処理への関心
● SIGDIAL2015,Special Session, Multiing 2015
○ オンラインフォーラム、コールセンターの要約
● ACL2016, 3rd Workshp on Argument Mining
○ 議論データに関するWorkshop
○ 要約に関して2件の発表 [1, 2]
● COLING2016, Invited talk4
○ A Look at Computational Argumentation and Summarisation from a Text-Understanding Perspective
[1] Barker et al., "Summarizing Multi-Party Argumentative Conversations in Reader Comment on News", in Proc of 3rd Workshop on Argument Mining, 2016.
[2] Egan et al., Summarizng the points made in online politial deates", in Proc of 3rd Workshop on Argument Mining, 2016.
3. 対話要約特有の問題
対話要約における3つの問題 [17]
1.自動音声認識 (ASR) 誤りの問題
○ 音声認識のエラー
1. Disfluencyの問題
○ Filled Pauses (遊び言葉: uh, um, well ...)
○ Repetisions (繰り返し)
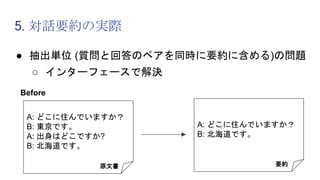
1. 抽出単位の問題
○ 質問と回答の一貫性
[17] Nenkova et al., "Automatic Summarization", Foundations and Trends in Information Retrieval, Vol 5, No 2-3, pp. 103-233, 2011.
24.
3. 対話要約特有の問題
1. 自動音声認識(ASR) 誤りの問題
○ 10% - 40%程度の音声認識誤り [18]
○ AMI Meeting Corpus [19] の例
■ 人手書き起こし
"You look quite funny at the moment, Tim."
■ ASRの結果
"Great can implement that I"
[18] Glass et al., "Recent progress in the MIT spoken lecture processing project", in Proceedings of the Annual Conference of the International Speech Communication
Association, pp. 2553–2556, 2007.
[19] http://groups.inf.ed.ac.uk/ami/corpus/
25.
3. 対話要約特有の問題
2. Disfluencyの問題(Filled Pauses and Repetitions)
○ Filled Pauses: uh, um, well ... などの遊び言葉
○ Repetitions: 同じ言葉が繰り返される
○ 全体の15 - 25%程度存在する [20]
○ 具体例
A: well I um I think we should discuss this you know with
her.
A’: I think we should discuss this with her.
[20] Zechner et al., "Summarization of spoken language - challenges, methods, and prospects,” Speech Technology Expert eZine, 2002.
26.
3. 対話要約特有の問題
2. Disfluencyの問題(Filled Pauses and Repetitions)
○ Disfluencyの削除だけで1つの研究分野 [21-23]
○ 特徴量の1つとして利用 [24]
■ Disfluencyが存在する文は重要であるという仮説
■ ROUGE値の向上は1%未満
[21] Johnson et al., “A TAG-based noisy-channel model of speech repairs,” ACL, 2004.
[22] Miller et al., “A syntactic time-series model for parsing fluent and disfluent speech,” in Proceedings of the International Conference on Computational Linguistic,
pp. 569–576, 2008.
[23] Stolcke et al., “Statistical language modeling for speech disfluencies,” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal
Processing, pp. 405–408, 1996.
[24] Zhu et al., “Summarization of spontaneous conversations,” in Proceedings of the Annual Conference of the International Speech Communication Association,
pp. 1531–1534, 2006.




![1. はじめに
対話データ処理への関心
● SIGDIAL2015, Special Session, Multiing 2015
○ オンラインフォーラム、コールセンターの要約
● ACL2016, 3rd Workshp on Argument Mining
○ 議論データに関するWorkshop
○ 要約に関して2件の発表 [1, 2]
● COLING2016, Invited talk4
○ A Look at Computational Argumentation and Summarisation from a Text-Understanding Perspective
[1] Barker et al., "Summarizing Multi-Party Argumentative Conversations in Reader Comment on News", in Proc of 3rd Workshop on Argument Mining, 2016.
[2] Egan et al., Summarizng the points made in online politial deates", in Proc of 3rd Workshop on Argument Mining, 2016.](https://image.slidesharecdn.com/random-170324043608/85/slide-5-320.jpg)

![2. 要約の代表的な手法
● 対話要約手法
○ 大部分の研究は非対話要約の手法を利用 [3]
→ 2章では、テキスト要約の代表的な手法を説明
● テキスト要約に関する分かりやすいスライド
○ 西川先生のスライド [4]
○ yamao357様のスライド [5]
[3] Nenkova et al., "Automatic Summarization", Foundations and Trends in Information Retrieval, Vol 5, No 2-3, pp. 103-233, 2011.
[4] http://www.slideshare.net/hitoshin/automatic-summarization
[5] https://rpubs.com/yamano357/27317](https://image.slidesharecdn.com/random-170324043608/85/slide-7-320.jpg)
![2. 要約の代表的な手法
要約の大分類 [4]
1. 要約の使い方
○ 指示的 / 報知的
1. 必要な情報の指定
○ クエリ依存 / クエリ非依存
1. 入力文書の数
○ 単一 / 複数
1. 要約を作る方法
○ 抽出型要約 / 生成型要約
● 指示的: 原文書を読むべきか判断する
ための要約
e.g. 新聞の見出し、スニペット
● 報知的: 原文書の代わりとする要約
e.g. ニュース番組の字幕](https://image.slidesharecdn.com/random-170324043608/85/slide-8-320.jpg)





![2. 要約の代表的な手法
網羅性を向上
● 最大被覆問題に落とし込む [6]
○ 同じ内容が繰り返し述べられても
スコアを増加させない
○ 上記の条件を満たすように目的関数、制約条件を設定
[6] 高村ら, "最大被覆問題とその変種による文書要約モデル", 人工知能学会論文誌, 2008.](https://image.slidesharecdn.com/random-170324043608/85/slide-14-320.jpg)
![2. 要約の代表的な手法
文短縮
● 文抽出と文短縮の同時モデル [7]
○ 各単語毎にスコアリング
○ 係り受け関係を保持したまま要約を作成
○ 係り受け関係は制約条件として記述
[7] 富田ら, "重要文抽出と文圧縮を組み合わせた新たな抽出的要約手法", 情報処理学会研究報告, 2009.](https://image.slidesharecdn.com/random-170324043608/85/slide-15-320.jpg)
![2. 要約の代表的な手法
談話構造の考慮
● 入れ子依存木の刈り込みによる要約生成 [8]
○ 係り受け関係、談話関係を保持したまま要約を作成
○ 一貫性を保ちつつ、要約長に柔軟な要約が生成可能
○ 制約条件として上記を記述
[8] 菊池ら, "入れ子依存木の刈り込みによる単一文書要約", 自然言語処理, 2015.](https://image.slidesharecdn.com/random-170324043608/85/slide-16-320.jpg)
![2. 要約の代表的な手法
ILPとして定式化している論文 [9-13]
[9] Automatic Summarization of Student Course Feedback, NAACL-HLT 2016.
[10]Generating Coherent Summaries of Scientific Articles Using Coherence Patterns,
EMNLP 2016.
[11] Exploring Text Links for Coherent Multi-Document Summarization, COLING
2016.
[12] Optimizing an Approximation of ROUGE – a Problem-Reduction Approach to
Extractive Multi-Document Summarization, ACL 2016.
[13] Learning-Based Single-Document Summarization with Compression and
Anaphoricity Constraints, ACL 2016.](https://image.slidesharecdn.com/random-170324043608/85/slide-17-320.jpg)
![2. 要約の代表的な手法
ILP以外の要約手法 1
● PageRankアルゴリズムの利用 [14]
○ 各文をノードとして表現
○ 各文の類似度をエッジの重みとして表現
○ HITSアルゴリズムにより各文の重要度を計算
[14] Erkan et al., "LexRank: Graph-based Lexical Centrality as Salience in Text Summarization", Journal of Artificial Intelligence Research, 2004.](https://image.slidesharecdn.com/random-170324043608/85/slide-18-320.jpg)
![2. 要約の代表的な手法
ILP以外の要約手法 2
● MMR (Maximal Marginal Relevance) [15]
○ スコアの高い文から順番に選択
○ 1文選ばれる毎に各文のスコアを更新
○ 既に選ばれている文と似ている文のスコアを小さく
→ 網羅性が向上
[15] Goldstein et al., "Multi-document Summarization by Sentence Extraction", in Proc of the 2000 NAALP-ANLP Workshop on Automatic Summarization , 2000.](https://image.slidesharecdn.com/random-170324043608/85/slide-19-320.jpg)

![2. 要約の代表的な手法
抽出型要約研究の焦点
● 網羅性
○ 原文書の重要な内容を網羅すること
● 一貫性
○ 原文書の談話構造 (論理構造) を保持すること
○ 文と文の大域的な関係を考慮
● トレンドは "網羅性" → "一貫性"
※網羅性に着目した研究もまだまだ現役 [16]
[16] Ren et al., "A Redundancy-Aware Sentence Regression Framework for Extractive Summarization", COLING, 2016.](https://image.slidesharecdn.com/random-170324043608/85/slide-21-320.jpg)

![3. 対話要約特有の問題
対話要約における3つの問題 [17]
1. 自動音声認識 (ASR) 誤りの問題
○ 音声認識のエラー
1. Disfluencyの問題
○ Filled Pauses (遊び言葉: uh, um, well ...)
○ Repetisions (繰り返し)
1. 抽出単位の問題
○ 質問と回答の一貫性
[17] Nenkova et al., "Automatic Summarization", Foundations and Trends in Information Retrieval, Vol 5, No 2-3, pp. 103-233, 2011.](https://image.slidesharecdn.com/random-170324043608/85/slide-23-320.jpg)
![3. 対話要約特有の問題
1. 自動音声認識 (ASR) 誤りの問題
○ 10% - 40%程度の音声認識誤り [18]
○ AMI Meeting Corpus [19] の例
■ 人手書き起こし
"You look quite funny at the moment, Tim."
■ ASRの結果
"Great can implement that I"
[18] Glass et al., "Recent progress in the MIT spoken lecture processing project", in Proceedings of the Annual Conference of the International Speech Communication
Association, pp. 2553–2556, 2007.
[19] http://groups.inf.ed.ac.uk/ami/corpus/](https://image.slidesharecdn.com/random-170324043608/85/slide-24-320.jpg)
![3. 対話要約特有の問題
2. Disfluencyの問題 (Filled Pauses and Repetitions)
○ Filled Pauses: uh, um, well ... などの遊び言葉
○ Repetitions: 同じ言葉が繰り返される
○ 全体の15 - 25%程度存在する [20]
○ 具体例
A: well I um I think we should discuss this you know with
her.
A’: I think we should discuss this with her.
[20] Zechner et al., "Summarization of spoken language - challenges, methods, and prospects,” Speech Technology Expert eZine, 2002.](https://image.slidesharecdn.com/random-170324043608/85/slide-25-320.jpg)
![3. 対話要約特有の問題
2. Disfluencyの問題 (Filled Pauses and Repetitions)
○ Disfluencyの削除だけで1つの研究分野 [21-23]
○ 特徴量の1つとして利用 [24]
■ Disfluencyが存在する文は重要であるという仮説
■ ROUGE値の向上は1%未満
[21] Johnson et al., “A TAG-based noisy-channel model of speech repairs,” ACL, 2004.
[22] Miller et al., “A syntactic time-series model for parsing fluent and disfluent speech,” in Proceedings of the International Conference on Computational Linguistic,
pp. 569–576, 2008.
[23] Stolcke et al., “Statistical language modeling for speech disfluencies,” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal
Processing, pp. 405–408, 1996.
[24] Zhu et al., “Summarization of spontaneous conversations,” in Proceedings of the Annual Conference of the International Speech Communication Association,
pp. 1531–1534, 2006.](https://image.slidesharecdn.com/random-170324043608/85/slide-26-320.jpg)

![3. 対話要約特有の問題
3. 抽出単位の問題 (質問と回答の一貫性)
○ ヒューリスティックルールで同定 [25]
■ 初めてこの問題について言及した論文
■ F1-scoreは0.5程度
○ 対話の談話解析 [26]
■ 対話ドメインにおける談話解析手法を提案
■ F1-scoreは0.5程度
[25] Zechner et al., “Increasing the coherence of spoken dialogue summaries by cross-speaker information linking,” NAACL Workshop on Automatic Summarization,
2001.
[26] Afantenos et al., “Discourse parsing for multi-party chat dialogues," EMNLP, 2015.](https://image.slidesharecdn.com/random-170324043608/85/slide-28-320.jpg)
![4. 評価方法
データセット
● AMI Meeting Corpus [19]
○ 会議のデータ
○ 人手の書き起こしや要約
○ Dialogue Act, Topic Segment などのアノテーション
○ 無料](https://image.slidesharecdn.com/random-170324043608/85/slide-29-320.jpg)
![4. 評価方法
データセット
● ICSI Meeting Corpus [27]
○ 会議のデータ
○ 人手の要約
○ 全75文書
○ 有料
[27] https://catalog.ldc.upenn.edu/LDC2004T04](https://image.slidesharecdn.com/random-170324043608/85/slide-30-320.jpg)