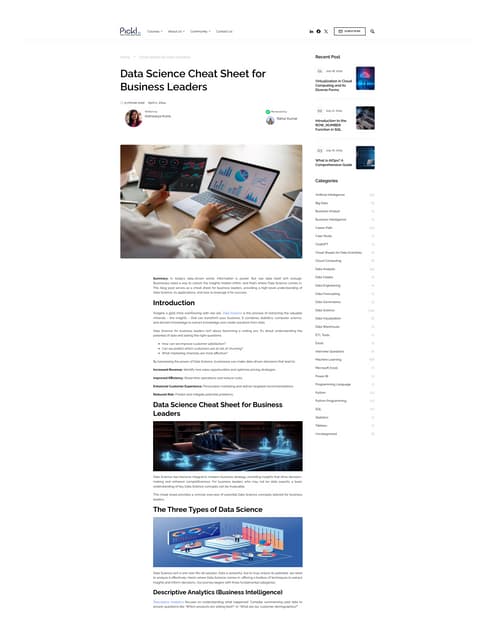
The document outlines data science methodology, focusing on big data characteristics known as the 5 V's: volume, velocity, variety, veracity, and value. It describes the data analytics life cycle, which includes six iterative phases: data discovery, data preparation and processing, model designing, model building, result communication, and operationalization. Additionally, it highlights the importance of identifying key business objectives and the necessary steps to handle and analyze data effectively.









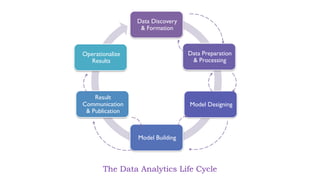






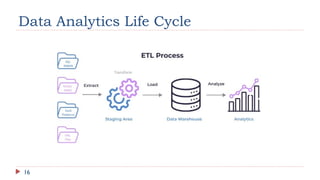

































![Data Analytics Life Cycle [EMC² - Data Science and Big data analytics]](https://cdn.slidesharecdn.com/ss_thumbnails/bdalifecycle-slideshare-211028070344-thumbnail.jpg?width=640&height=640&fit=bounds)