Downloaded 135 times




















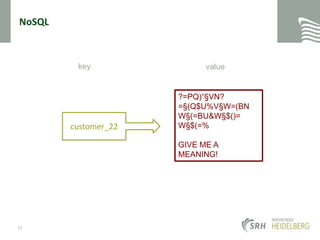

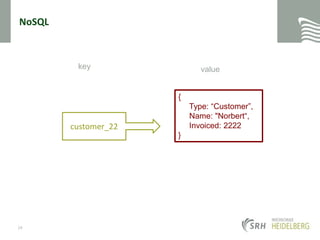
![NoSQLkeyvalue / documents{ Type: "Customer", Name: "Norbert", Invoiced: 2222 Messages: [ { Title: "Hello", Text: "World" }, { Title: "Second", Text: "message" } ] }customer_2225](https://image.slidesharecdn.com/dmdwextranosqlmongodb-110504202727-phpapp02/85/DMDW-Extra-Lesson-NoSql-and-MongoDB-25-320.jpg)












![CRUD – CreateHow training.scores was created:for(i=0; i<1000; i++) { ['quiz', 'essay', 'exam'].forEach(function(name) {var score = Math.floor(Math.random() * 50) + 50;db.scores.save({student: i, name: name, score: score}); }); }db.scores.count();39](https://image.slidesharecdn.com/dmdwextranosqlmongodb-110504202727-phpapp02/85/DMDW-Extra-Lesson-NoSql-and-MongoDB-39-320.jpg)


![CRUD – Updateuse digg; db.people.update({name: 'Smith'}, {'$set': {interests: []}});db.people.update({name: 'Smith'}, {'$push': {interests: ['chess']}});42](https://image.slidesharecdn.com/dmdwextranosqlmongodb-110504202727-phpapp02/85/DMDW-Extra-Lesson-NoSql-and-MongoDB-42-320.jpg)








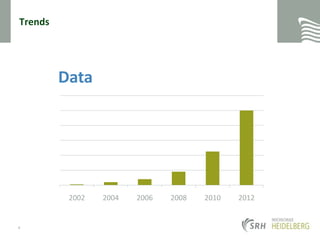
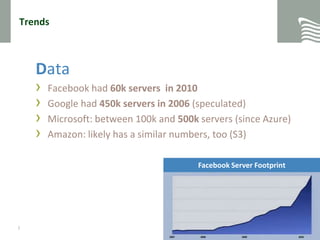
This document provides an overview of NoSQL and MongoDB. It discusses trends driving the adoption of NoSQL databases like increasing data sizes, more connectedness, and individualization. It covers the different types of NoSQL databases and MongoDB in particular. Key concepts discussed include the CAP theorem, MongoDB's document-oriented data model, and basic CRUD operations in MongoDB using the shell.



































































































