Download to read offline






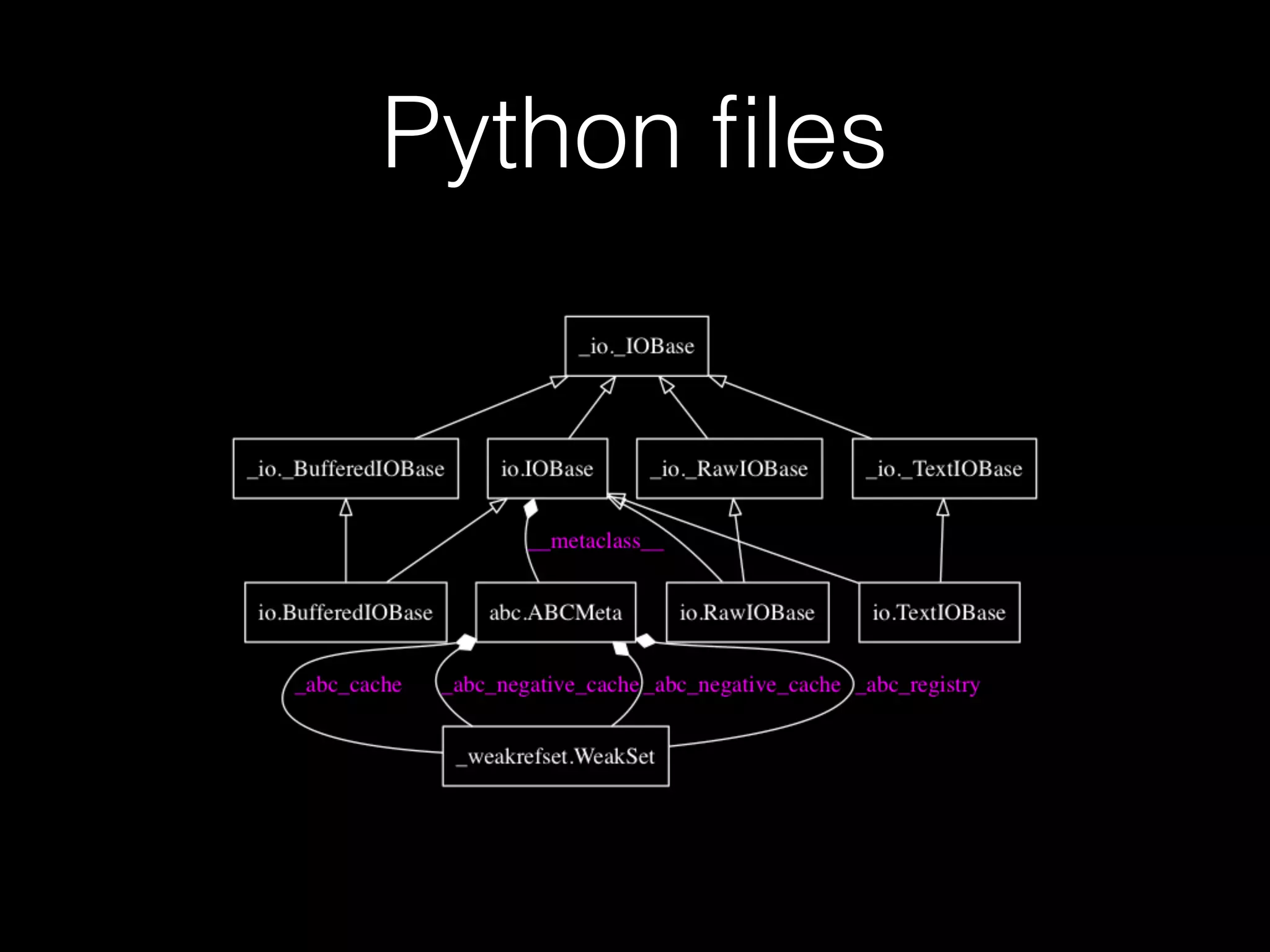
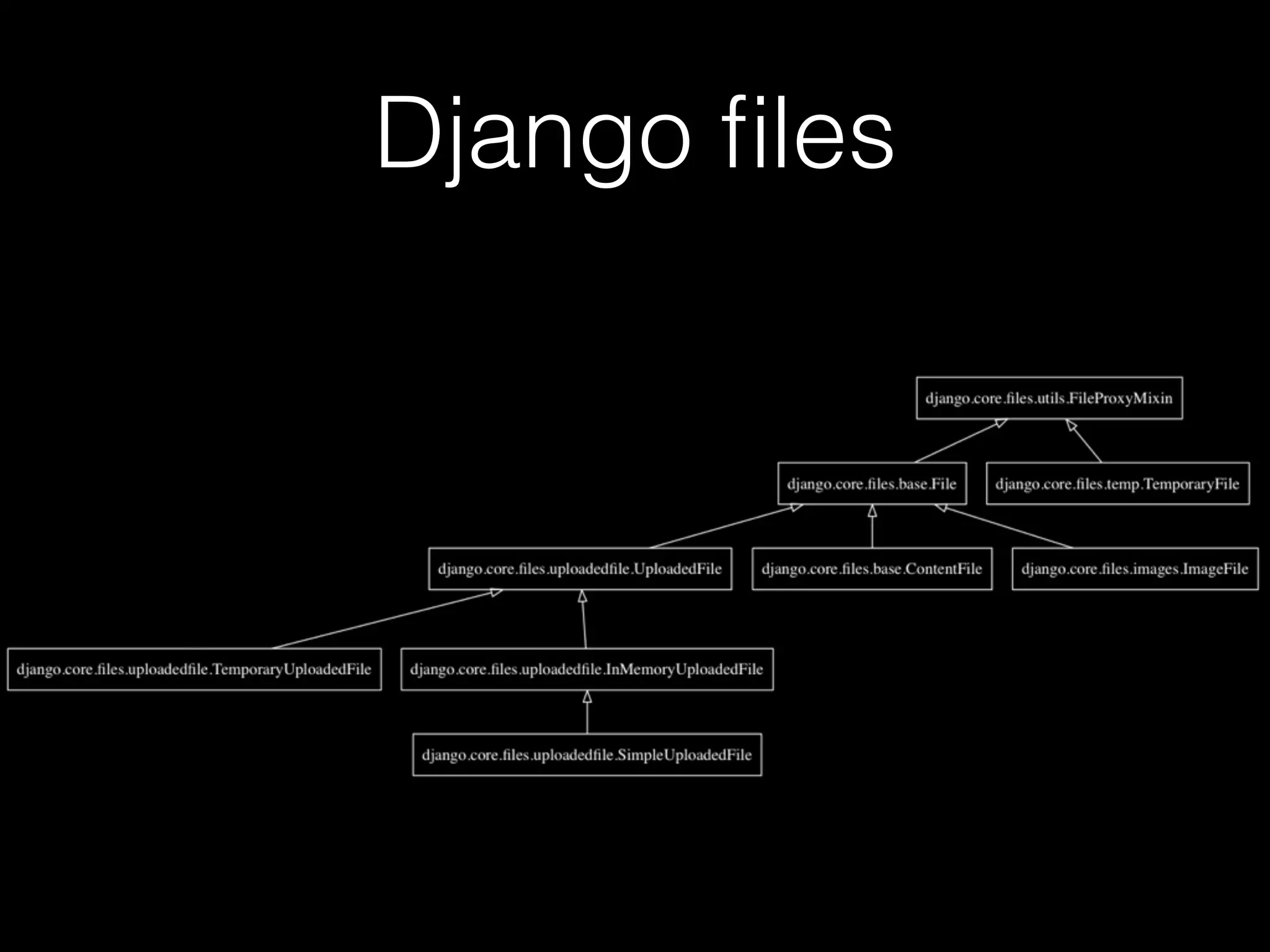




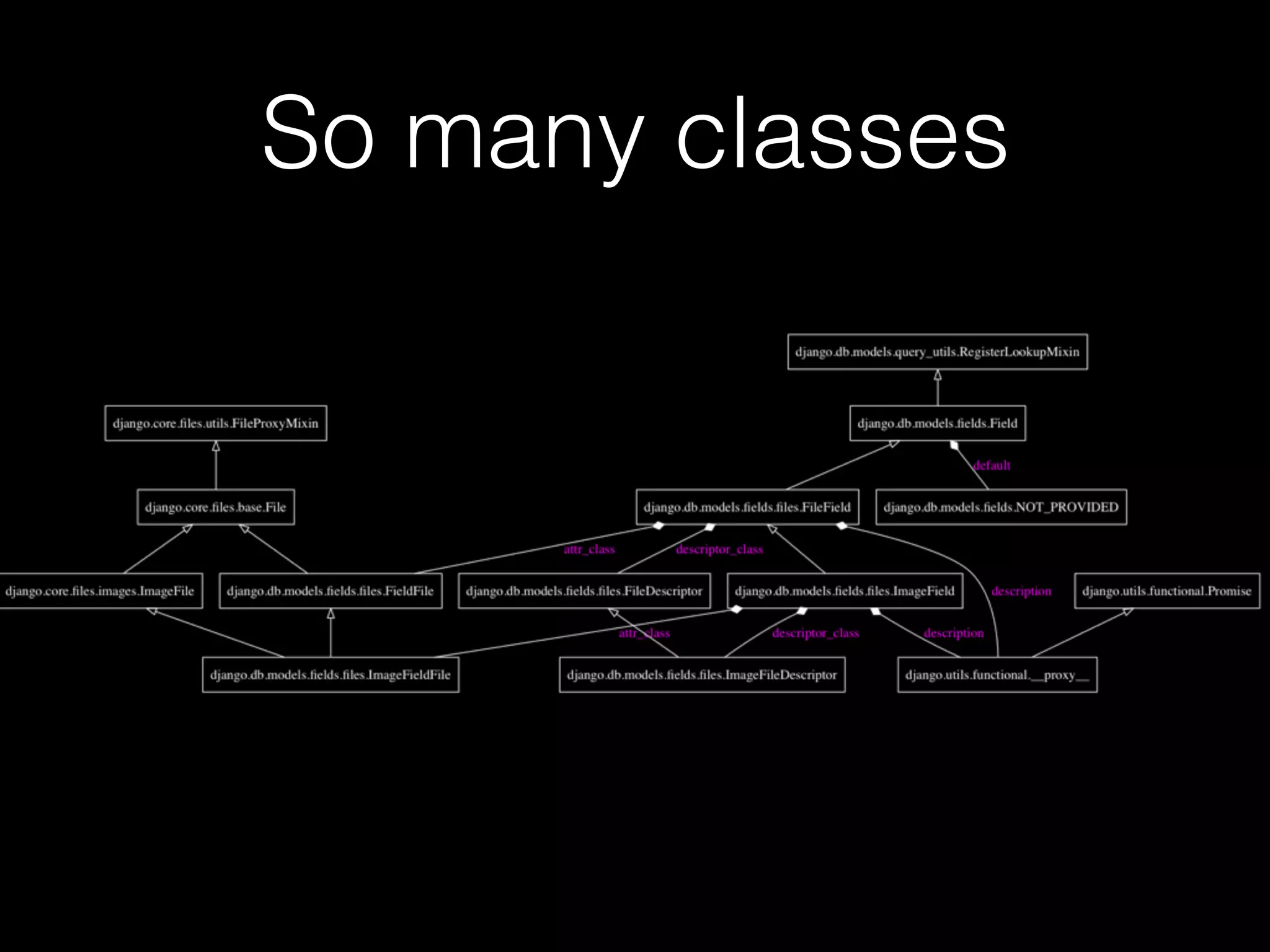
![forms.FileField
# forms-filefield.py
class FileForm(forms.Form):
uploaded = forms.FileField()
def upload(request):
if request.method == 'POST':
form = FileForm(request.POST, request.FILES)
if form.is_valid():
request.FILES['uploaded'] # do something!
return HttpResponseRedirect('/next/')
else:
form = FileForm()
return render_to_response(
'upload.html',
{'form': form},
)](https://image.slidesharecdn.com/filesduth1h-slidesonly-151117145412-lva1-app6892/75/Django-Files-A-Short-Talk-slides-only-14-2048.jpg)










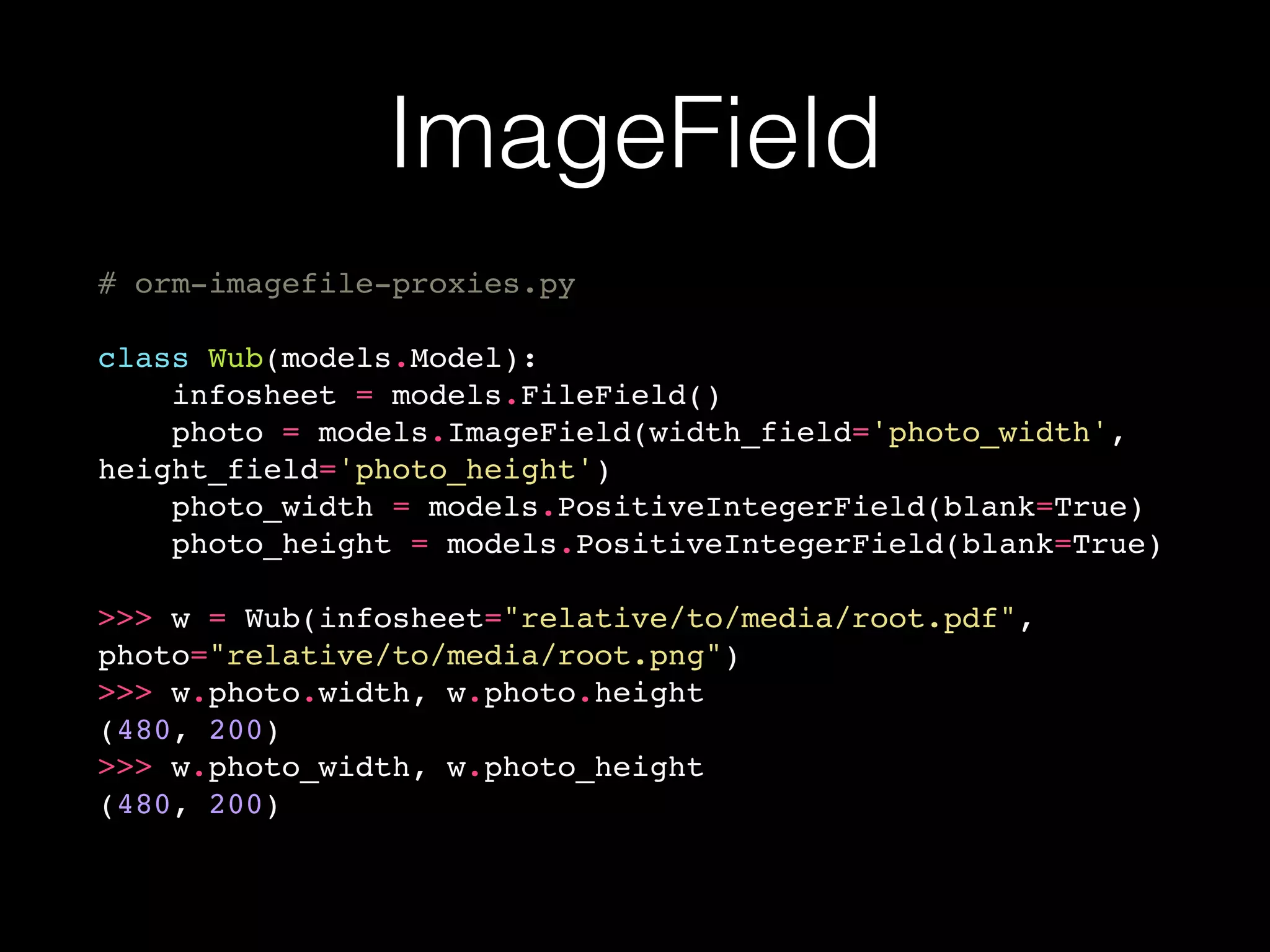
![In ModelForms
# modelforms-filefield.py
class Wub(models.Model):
infosheet = models.FileField()
class WubCreate(CreateView):
model = Wub
fields = ['infosheet']](https://image.slidesharecdn.com/filesduth1h-slidesonly-151117145412-lva1-app6892/75/Django-Files-A-Short-Talk-slides-only-25-2048.jpg)

![• #15817 ImageField having
[width|height]_field set sytematically compute
the image dimensions in ModelForm validation
process
• #18543 Non image file can be saved to
ImageField
• #19215 ImageField's “Currently” and “Clear”
Sometimes Don't Appear
• #21548 Add the ability to limit file extensions for
ImageField and FileField](https://image.slidesharecdn.com/filesduth1h-slidesonly-151117145412-lva1-app6892/75/Django-Files-A-Short-Talk-slides-only-27-2048.jpg)
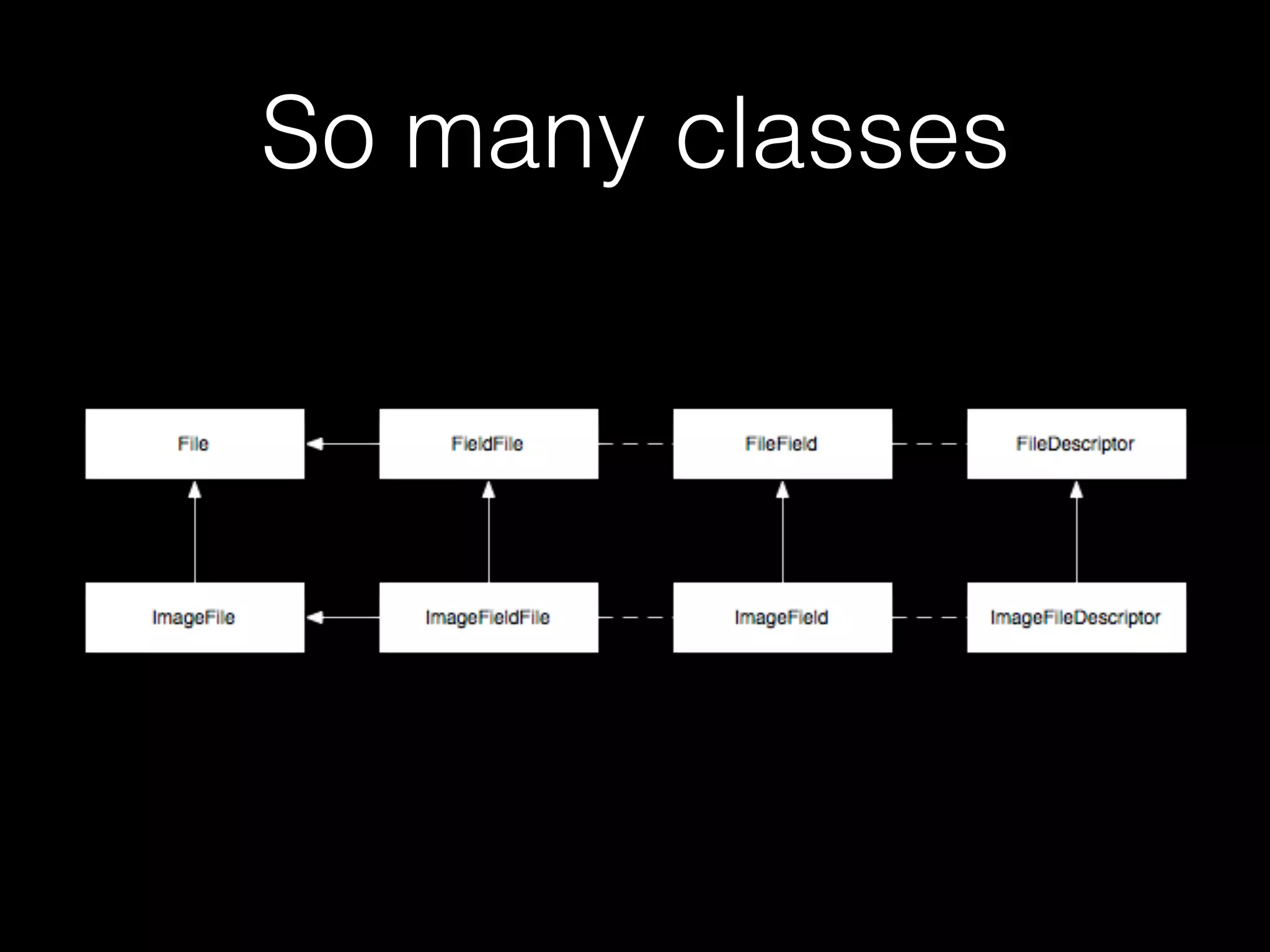

















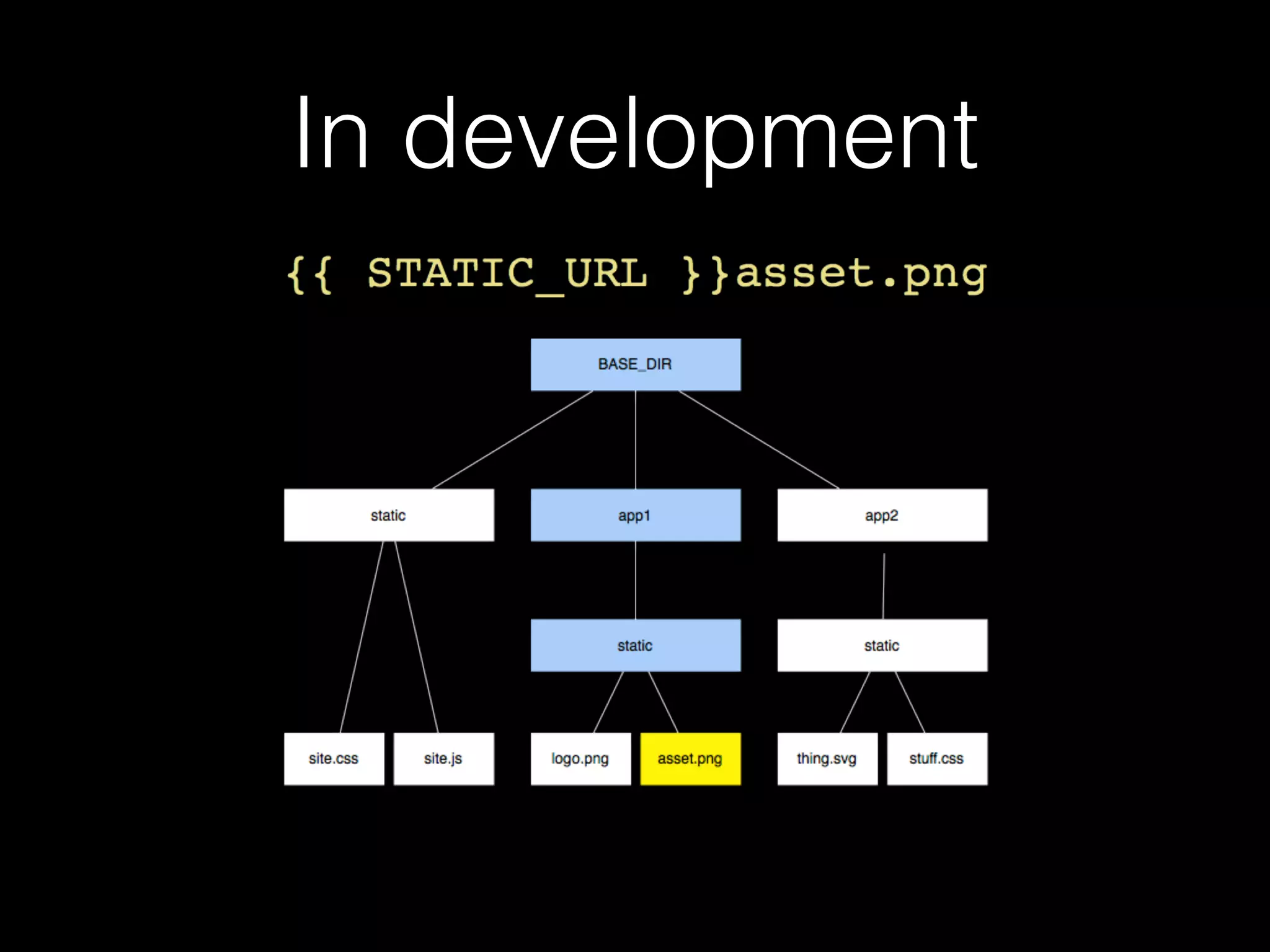
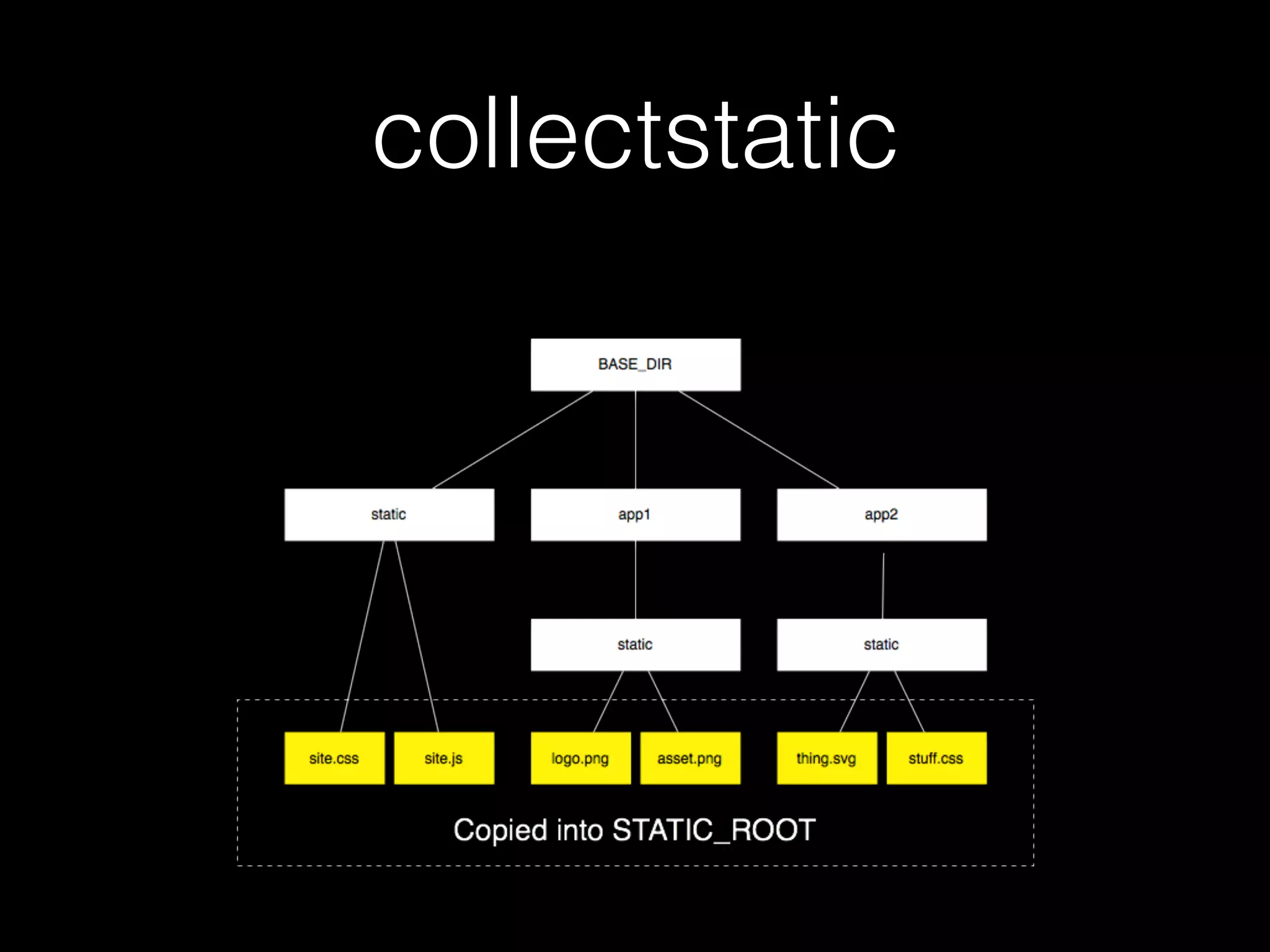






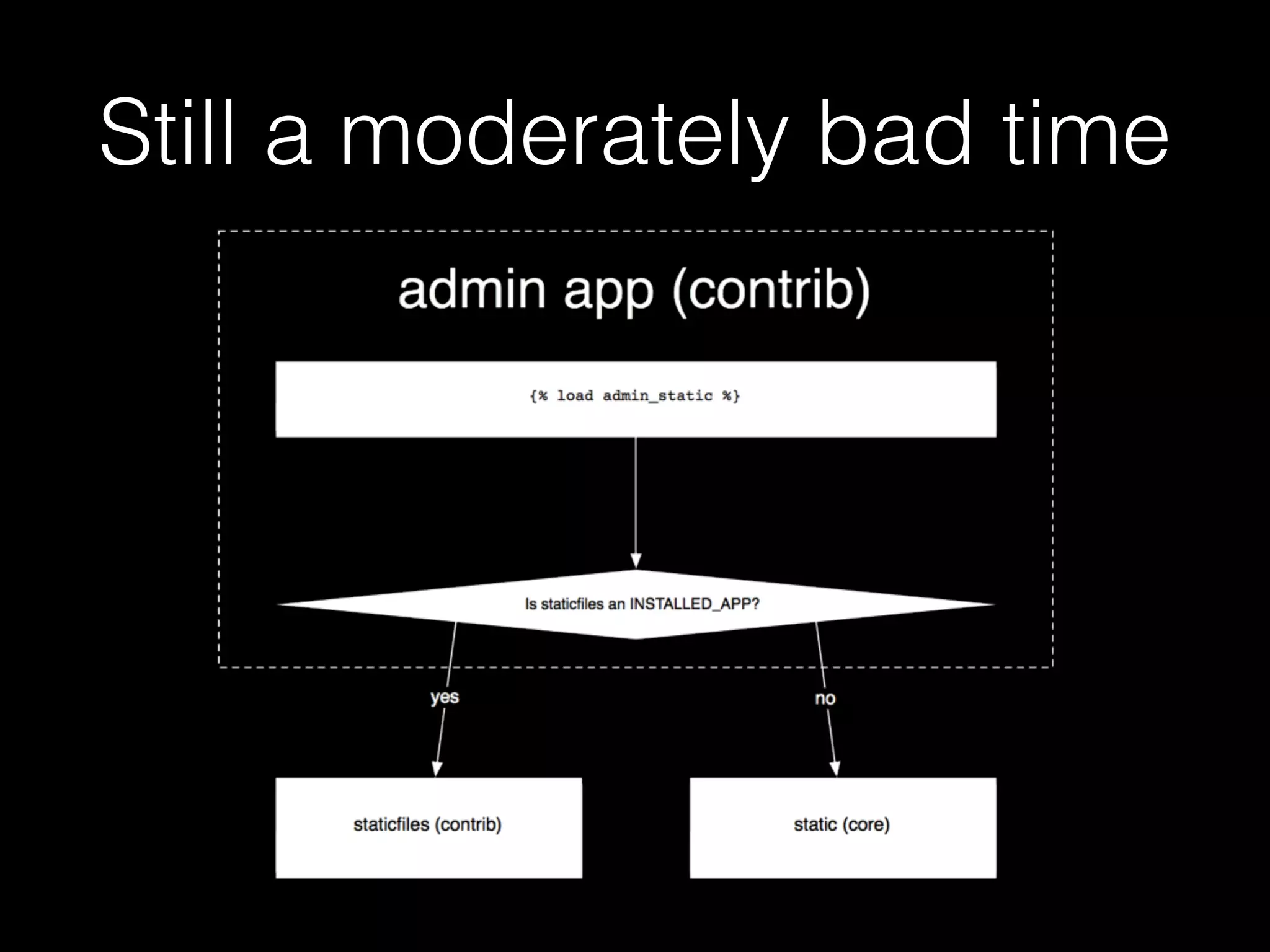












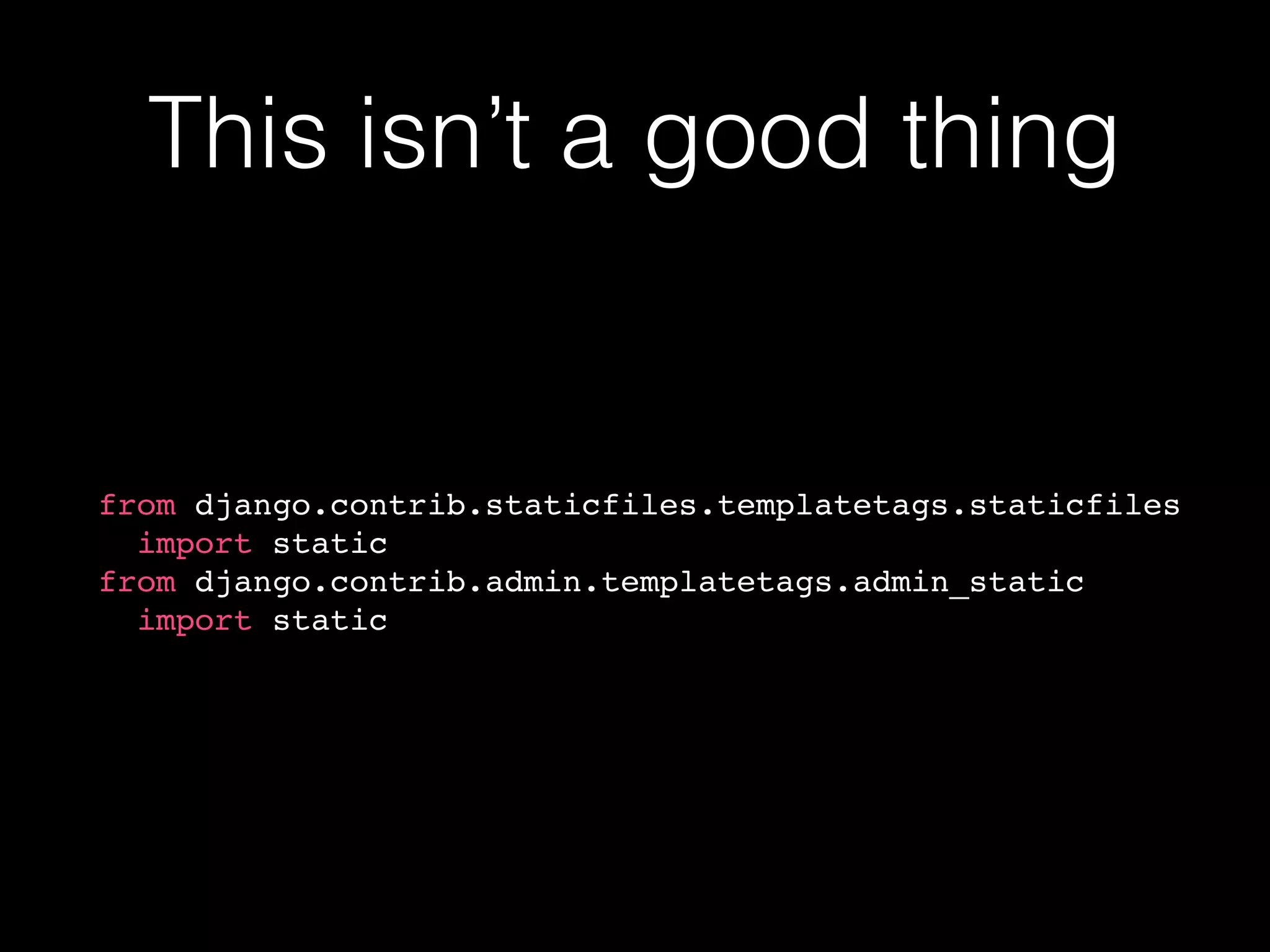
![This is a good thing
from django.contrib import admin
from django.contrib.staticfiles.templatetags.staticfiles
import static
class ArticleAdmin(admin.ModelAdmin):
# ...
class Media:
js = [
'//tinymce.cachefly.net/4.1/tinymce.min.js',
static('js/tinymce_setup.js'),
]](https://image.slidesharecdn.com/filesduth1h-slidesonly-151117145412-lva1-app6892/75/Django-Files-A-Short-Talk-slides-only-72-2048.jpg)





















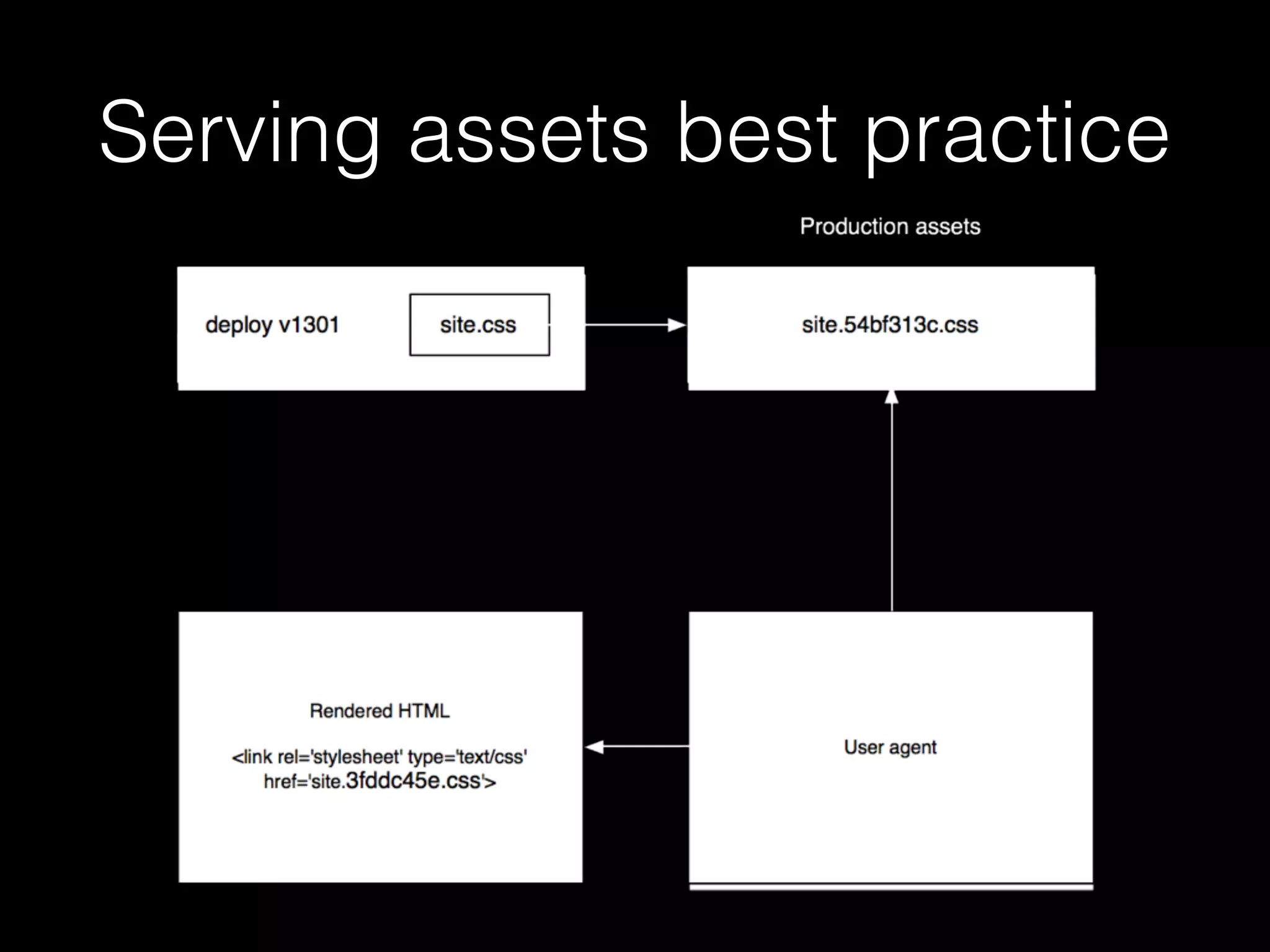
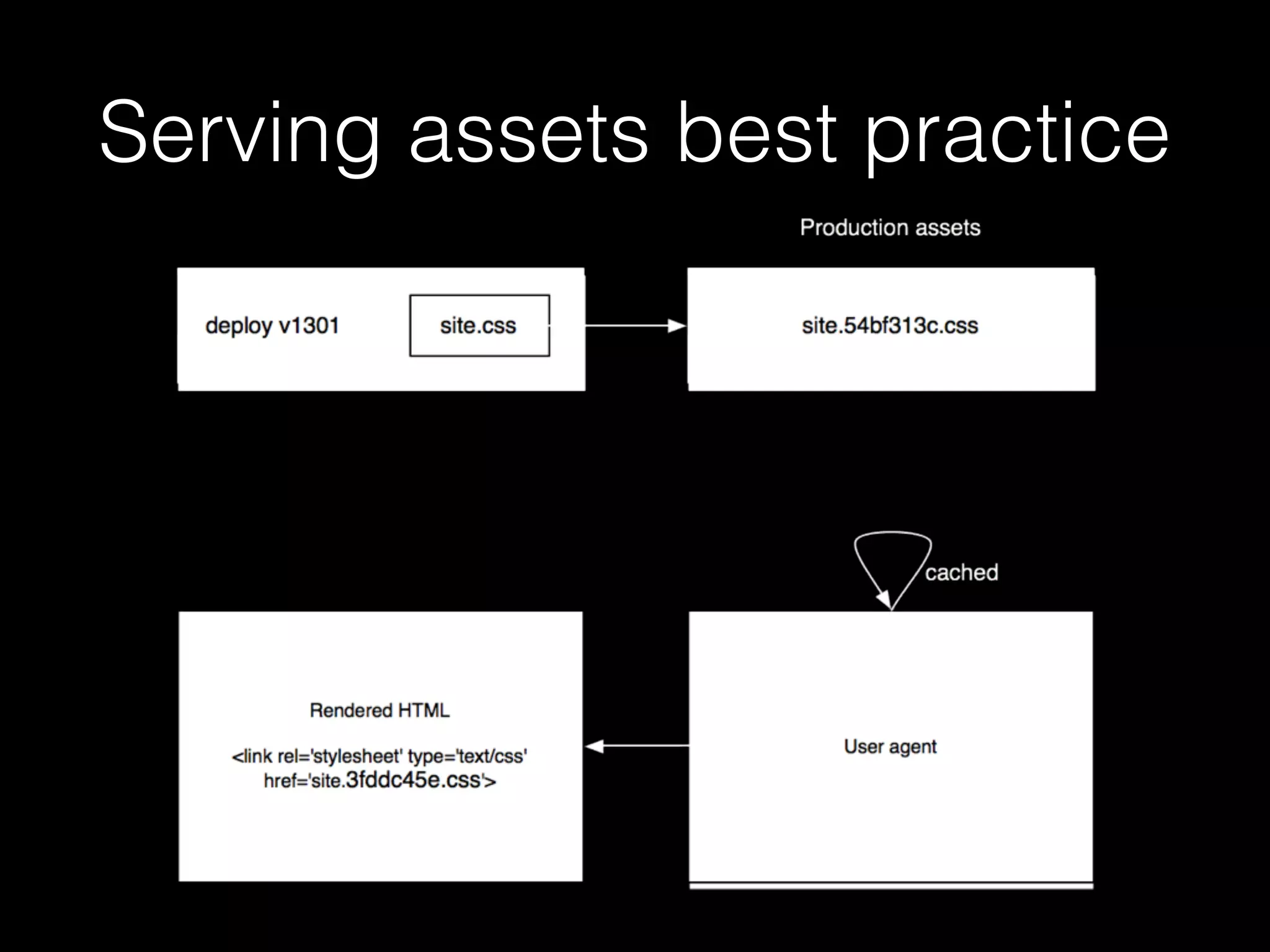
![gulp (node.js)
var gulp = require('gulp');
var sass = require('gulp-sass');
var sourcemaps = require('gulp-sourcemaps');
var rev = require('gulp-rev');
gulp.task('default', ['compile-scss']);
gulp.task('compile-scss', function() {
gulp.src('source/stylesheets/**/*.scss')
.pipe(sourcemaps.init())
.pipe(sass(
{indentedSyntax: false, errLogToConsole: true }
))
.pipe(sourcemaps.write())
.pipe(rev())
.pipe(gulp.dest('static'));
});](https://image.slidesharecdn.com/filesduth1h-slidesonly-151117145412-lva1-app6892/75/Django-Files-A-Short-Talk-slides-only-95-2048.jpg)
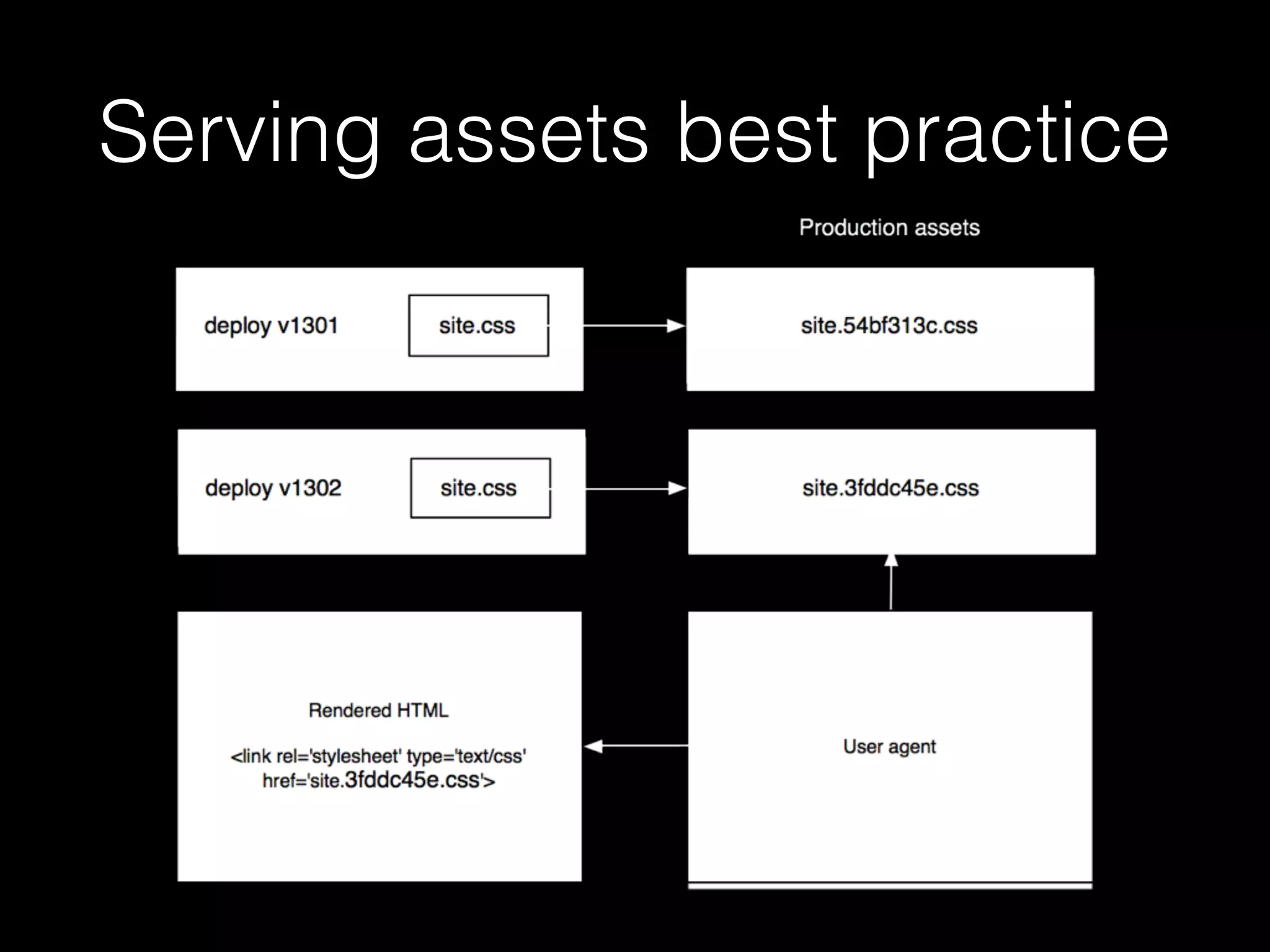
![gulp (node.js)
var gulp = require('gulp');
var sass = require('gulp-sass');
var sourcemaps = require('gulp-sourcemaps');
var rev = require('gulp-rev');
gulp.task('default', ['compile-scss']);
gulp.task('compile-scss', function() {
gulp.src('source/stylesheets/**/*.scss')
.pipe(sourcemaps.init())
.pipe(sass(
{indentedSyntax: false, errLogToConsole: true }
))
.pipe(sourcemaps.write())
.pipe(rev())
.pipe(gulp.dest('static'))
.pipe(rev.manifest())
.pipe(gulp.dest('static'));
});](https://image.slidesharecdn.com/filesduth1h-slidesonly-151117145412-lva1-app6892/75/Django-Files-A-Short-Talk-slides-only-96-2048.jpg)














This document provides information about files and file handling in Django. It discusses Django's FileField and ImageField model fields, how files are stored using different storage backends like FileSystemStorage and S3BotoStorage, working with files in forms and templates, static file management, and asset pipelines. It also lists several Django ticket issues related to files.















![[WLDN] Supercharging word press development in 2018](https://cdn.slidesharecdn.com/ss_thumbnails/superchargingwordpressdevelopmentin2018-180727084450-thumbnail.jpg?width=640&height=640&fit=bounds)





























































