The document discusses information extraction (IE) and machine translation (MT). It describes IE as extracting structured facts from unstructured text. Key IE tasks are named entity recognition, relation extraction, and event extraction. Sequence labeling approaches such as Markov models are commonly used for IE. The document also provides an overview of machine translation, describing how it has progressed from simple word substitution to using corpus statistics and neural networks to better handle translations.





























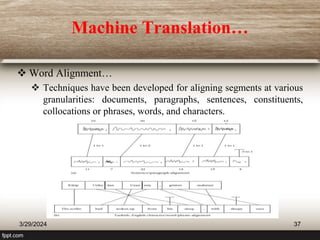
![Machine Translation…
Statistical Machine Translation (SMT)…
Statistical techniques for MT are now pervasive. Statistical
machine translation (SMT) takes a source sequence, S = [s1 s2 . . .
sK], and generates a target sequence, T∗ = [t1 t2 . . . tL], by
finding the most likely translation given by:
SMT is then concerned with making models for p(T|S) and
subsequently searching the space of all target strings to find the
optimal string given the source and the model.
3/29/2024 29](https://image.slidesharecdn.com/5-informationextractionieandmachinetranslationmt-240329183327-40429c08/85/5-Information-Extraction-IE-and-Machine-Translation-MT-ppt-29-320.jpg)