Download as PDF, PPTX




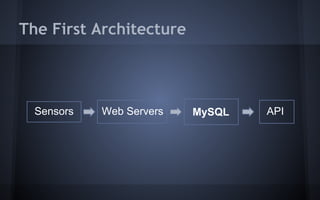


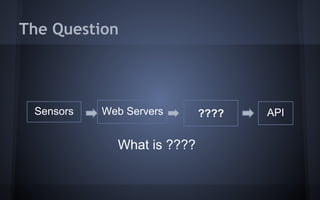





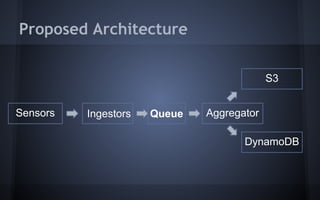





The document discusses distributed data systems for handling large amounts of sensor data. It describes the architecture of PressureNET, a system that gathers sensor data from smartphones. PressureNET faced scaling issues with its initial MySQL database. The document then proposes an architecture using ingestors to receive data, a queue for temporary storage, and an aggregator to process the data in batches and write it to durable storage like S3 and DynamoDB. This architecture leverages common patterns for scalably handling large and growing data streams.
















































































