











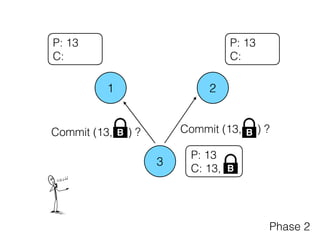
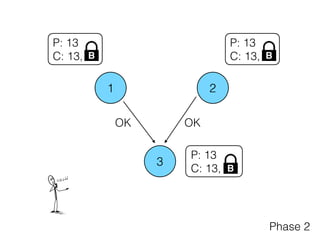
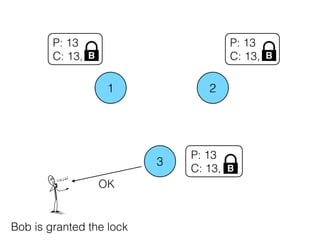

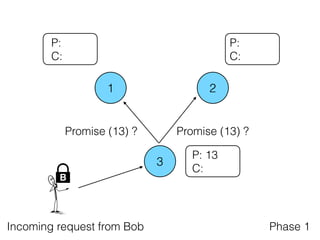
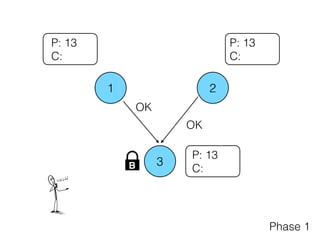
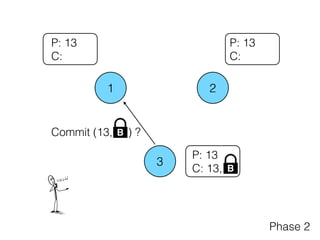
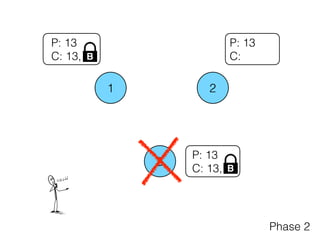
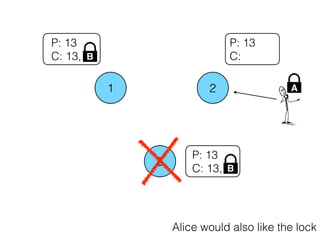
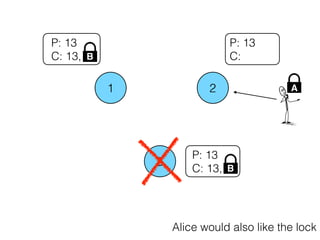
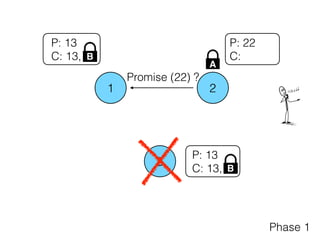
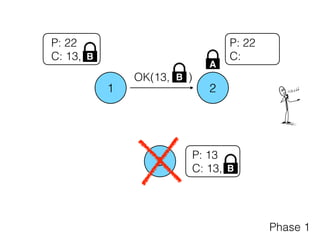

























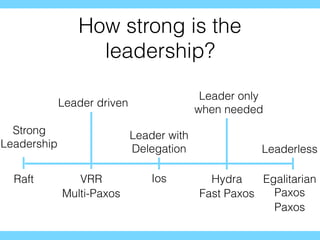





Distributed consensus algorithms allow different computer systems to agree on data values in an unreliable distributed network. The document summarizes the history and developments of consensus algorithms over three decades, including early impossibility results, Paxos, Multi-Paxos, Fast Paxos, Egalitarian Paxos, and Raft. It also discusses challenges in implementing consensus algorithms and potential future directions like Ios and Hydra that improve throughput and allow consensus across geographically distributed data centers.


![Distributed Consensus: Making Impossible Possible [Revised]](https://cdn.slidesharecdn.com/ss_thumbnails/impossibleconsensus-161020212626-thumbnail.jpg?width=640&height=640&fit=bounds)











































