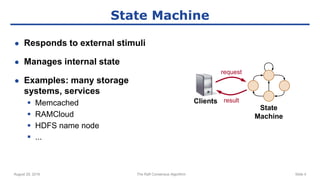
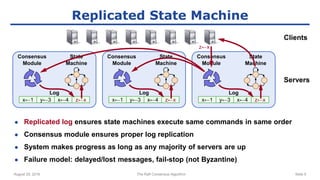
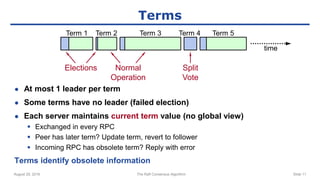
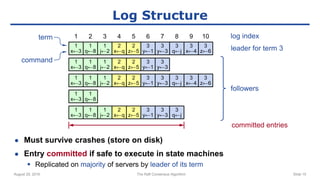
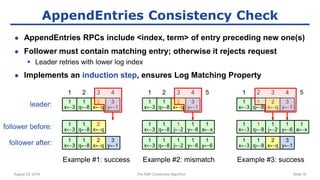
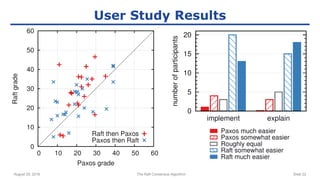
The raft consensus algorithm focuses on understandability, designed to enable groups of machines to work cohesively even amidst some failures, contrasting with the complex Paxos algorithm. Key components include leader election, log replication, and safety mechanisms to ensure consistent states across machines. User studies indicate that raft is generally easier to understand and implement than Paxos, leading to its wide adoption in various systems.









![August 29, 2016 The Raft Consensus Algorithm Slide 13
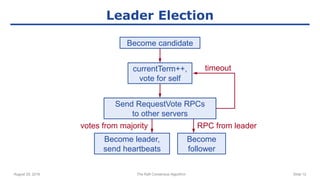
Election Correctness
● Safety: allow at most one winner per term
Each server gives only one vote per term (persist on disk)
Majority required to win election
● Liveness: some candidate must eventually win
Choose election timeouts randomly in [T, 2T] (e.g. 150-300 ms)
One server usually times out and wins election before others time out
Works well if T >> broadcast time
● Randomized approach simpler than ranking
Voted for
candidate A
B can’t also
get majority
Servers](https://image.slidesharecdn.com/uiuc2016-230410090433-b2944bab/85/uiuc2016-pdf-13-320.jpg)
















![[Yu cheng lin]cloud presentation - Raft](https://cdn.slidesharecdn.com/ss_thumbnails/yu-chenglincloudpresentation-raft-170817043111-thumbnail.jpg?width=640&height=640&fit=bounds)


















![Distributed Consensus: Making Impossible Possible [Revised]](https://cdn.slidesharecdn.com/ss_thumbnails/impossibleconsensus-161020212626-thumbnail.jpg?width=640&height=640&fit=bounds)
























