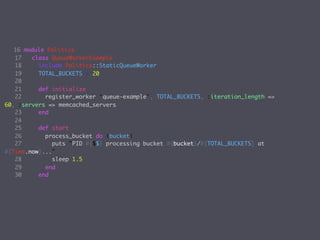
This document discusses patterns in distributed computing. It outlines some of the key hurdles in distributed systems like asynchrony, locality, failure, and Byzantine faults. It then summarizes common distributed algorithms like leader election, group membership, and consensus. It presents two Ruby libraries, TokenWorker and StaticQueueWorker, that implement leader election and work distribution patterns. It also briefly outlines the Paxos consensus algorithm but notes that a full implementation is very challenging. The document advocates for practical approaches over purely formal solutions and emphasizes starting with reasonable reliability requirements.






























































![Distributed Consensus: Making Impossible Possible [Revised]](https://cdn.slidesharecdn.com/ss_thumbnails/impossibleconsensus-161020212626-thumbnail.jpg?width=640&height=640&fit=bounds)





























