Downloaded 16 times













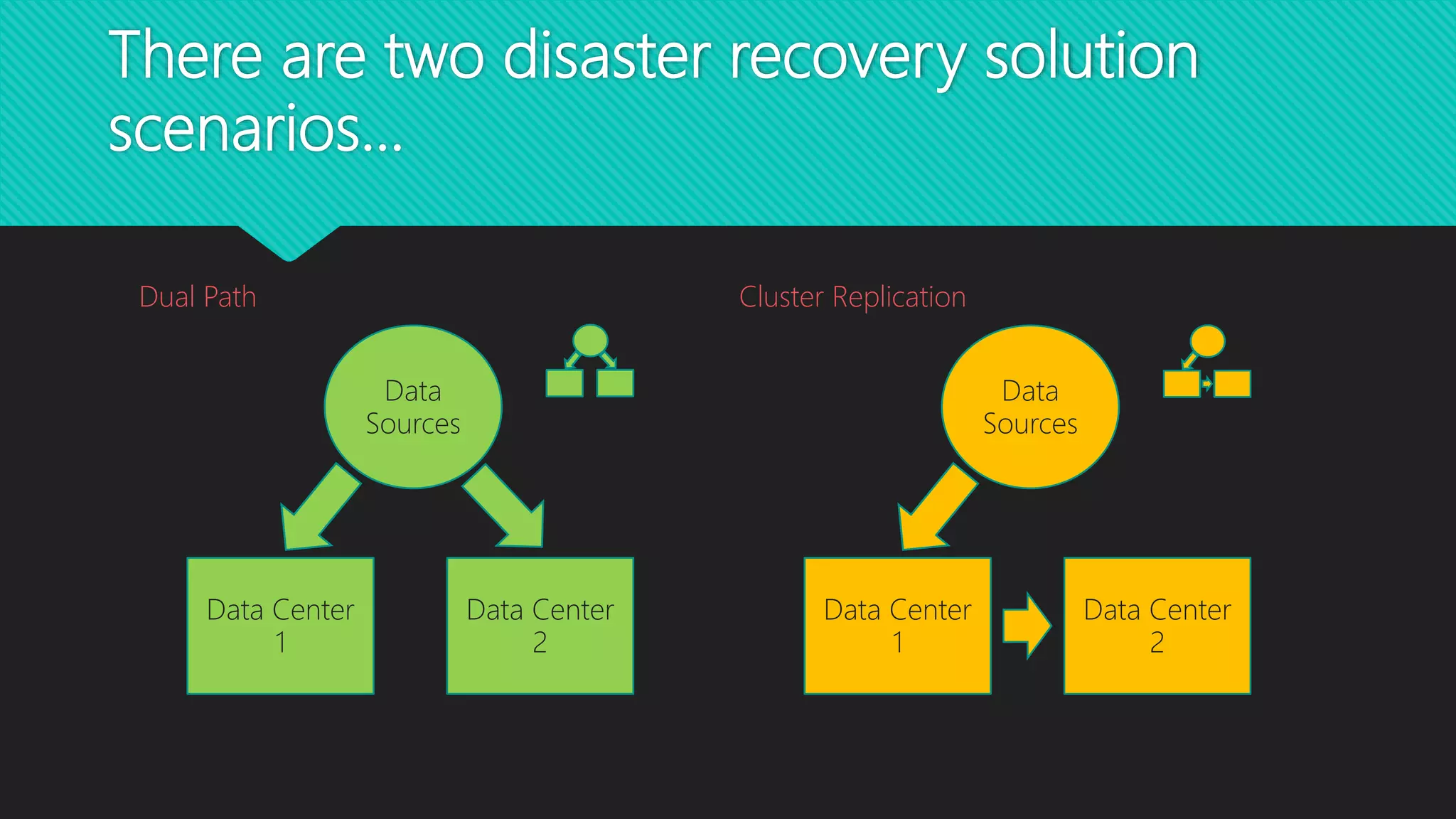

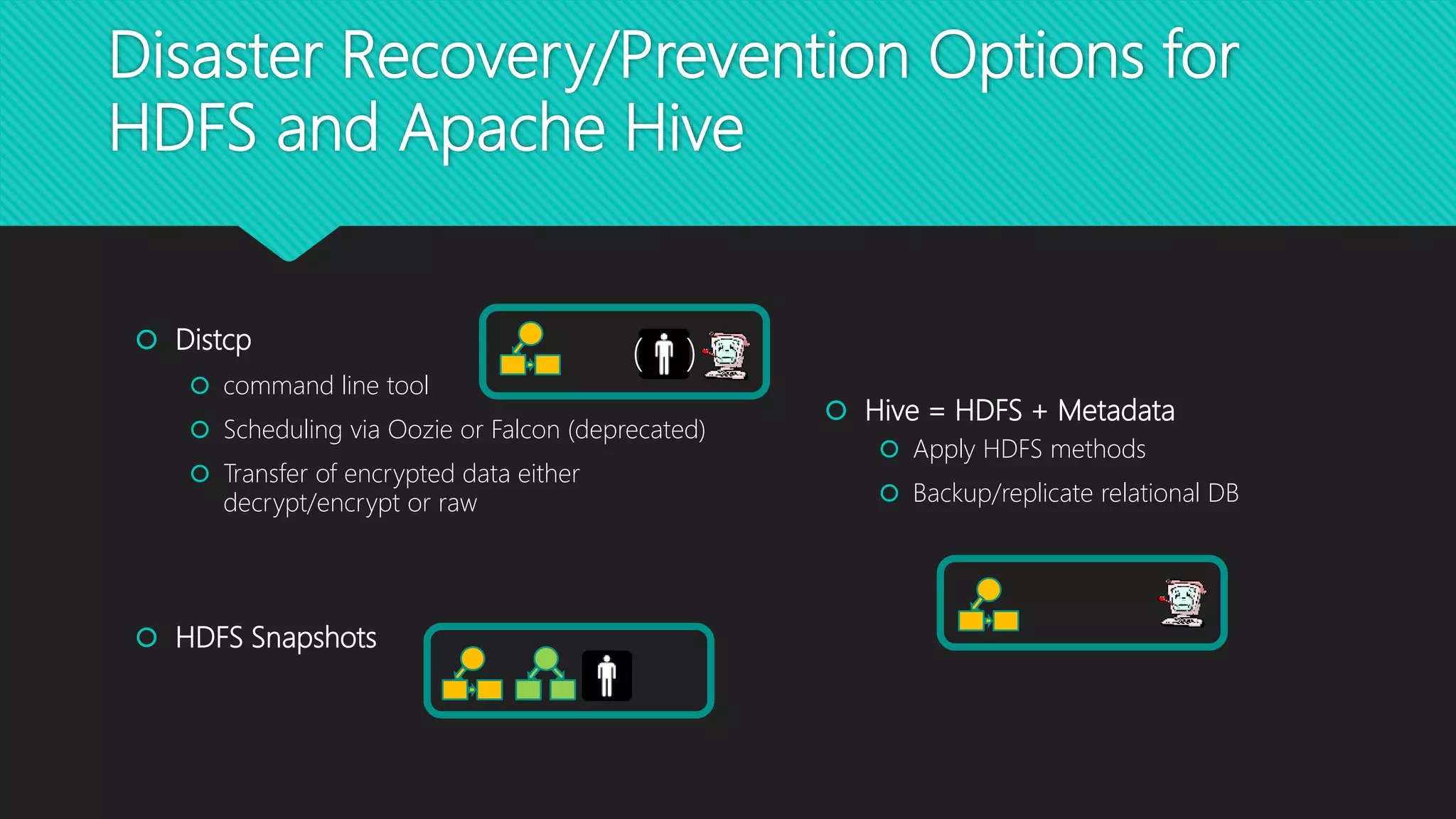





The 8th Hadoop User Group Vienna, organized by Stefan Dunkler, focused on disaster recovery in the Hadoop ecosystem and featured technical presentations on machine learning with Apache Kafka. The agenda included discussions on data loss prevention, backup strategies, and the setup of disaster recovery scenarios in different data centers. Key topics covered the importance of data replication, monitoring, and real-time solutions to ensure data safety and availability across Hadoop services.


































































