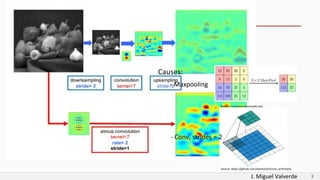
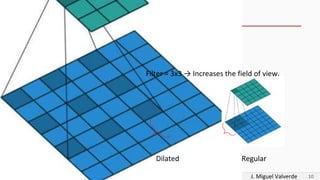
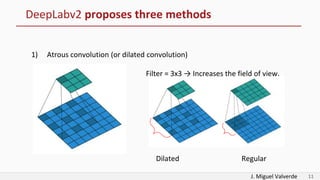
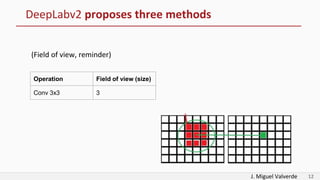
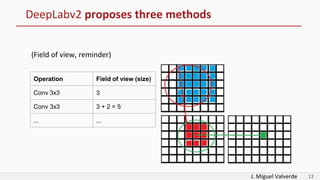
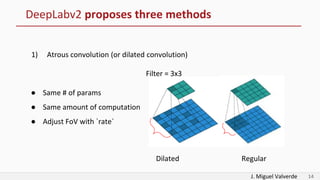
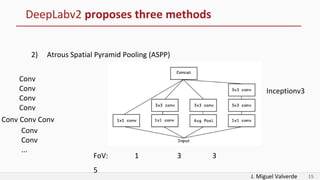
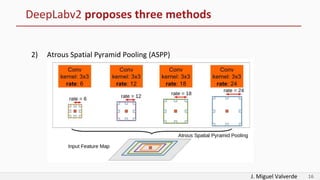
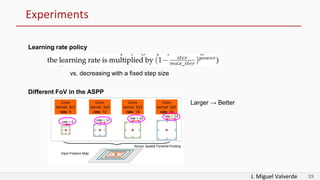
DeepLabv2 tackles three problems with semantic image segmentation: 1) reduced feature resolution from max pooling and convolutions with strides, 2) existence of multiple scale objects, and 3) reduced accuracy on borders. It proposes three methods to address these: 1) atrous convolution to increase field of view, 2) atrous spatial pyramid pooling with different rates, and 3) fully connected conditional random fields to refine segmentation predictions. The paper shows these methods improved segmentation accuracy compared to alternatives in experiments on PASCAL VOC.






























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)






