














![Continue
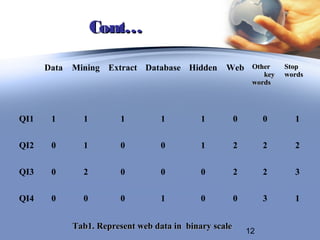
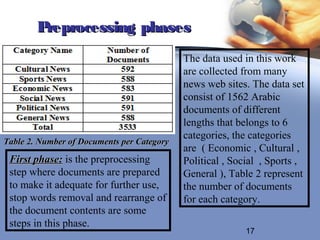
Second phase is the weighting assignment phase, it is defined as
the assignment of real number that relies between 0 and 1 to each
keyword and this number indicates the imperativeness of the
keyword inside the document.
Many methods have been developed and the most widely used model is the tf-idf
weighting factor. This weight of each keyword is computed by multiplying the
term factor (tf) with the inverse document factor (idf) where:
Fik = Occurrences of term tK in document Di.
tfik = fik/max (fil) normalized term frequency occurred in document.
dfk = documents which contain tk .
idfk= log (d/dfk) where d is the total number of documents and dfk is number of
document s that contains term tk.
wik = tfik * idfk for term weight, the computed w ik is a real number ɛ[0,1].
18](https://image.slidesharecdn.com/webmining-130207054109-phpapp02/85/Deep-Web-mining-18-320.jpg)













![References
[2] Alexandrov M., Gelbukh A. and Lozovo. (2001). Chi-square Classifier for
Document Categorization. 2nd International Conference on Intelligent Text
Processing and Computational Linguistics, Mexico City.
[37] Zakaria Suliman Zubi. 2010. Text mining documents in electronic data
interchange environment. In Proceedings of the 11th WSEAS international
conference on nural networks and 11th WSEAS international conference on
evolutionary computing and 11th WSEAS international conference on Fuzzy
systems (NN'10/EC'10/FS'10), Viorel Munteanu, Razvan Raducanu, Gheorghe
Dutica, Anca Croitoru, Valentina Emilia Balas, and Alina Gavrilut (Eds.).
World Scientific and Engineering Academy and Society (WSEAS), Stevens
Point, Wisconsin, USA, 76-88.
[38] Zakaria Suliman Zubi. 2009. Using some web content mining techniques for
Arabic text classification. In Proceedings of the 8th WSEAS international
conference on Data networks, communications, computers (DNCOCO'09), Manoj
Jha, Charles Long, Nikos Mastorakis, and Cornelia Aida Bulucea (Eds.). World
Scientific and Engineering Academy and Society (WSEAS), Stevens Point,
Wisconsin, USA, 73-84. 33](https://image.slidesharecdn.com/webmining-130207054109-phpapp02/85/Deep-Web-mining-33-320.jpg)



This document describes a study on text classification in the deep web. It discusses using classification methods like Naive Bayesian (CNB) and K-Nearest Neighbor (CK-NN) to classify web documents. The document outlines preprocessing steps like removing stop words and weighting terms. It also provides details on implementing CNB and CK-NN classifiers to classify Arabic documents into categories like economic, cultural, political etc. and compares the results of the two classifiers to select the most accurate one.




























































