








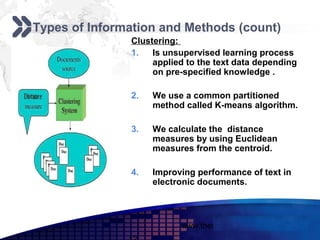








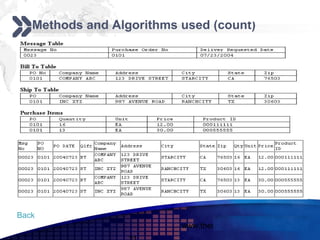







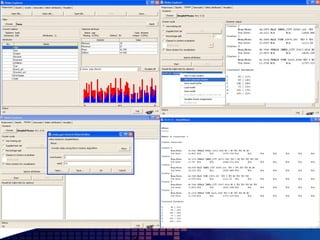
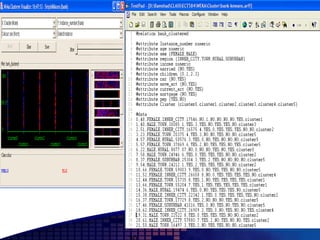





This document discusses text mining of documents in electronic data interchange (EDI) environments. It describes how EDI formats can be transformed and stored in databases, then text mining techniques like clustering can be applied. Specifically, it uses k-means clustering with Euclidean distance measures on a dataset of 2000 EDI documents categorized into 7 groups related to banking transactions. The goal is to discover patterns in the text that can help applications like identifying customer demographics and buying behaviors.




























































