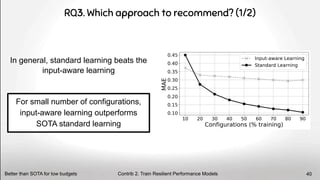
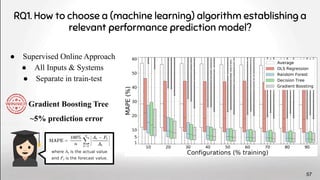
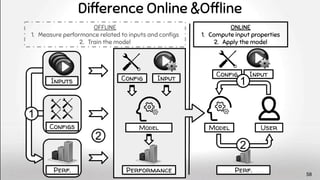
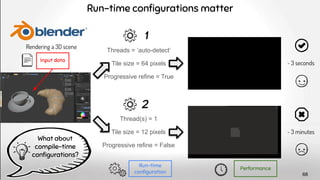
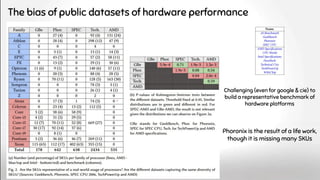
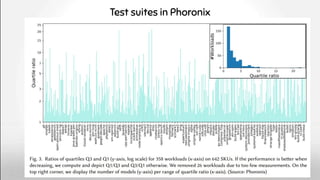
The document discusses deep software variability and its impact on the performance of configurable systems, detailing how numerous options and configurations can lead to distinct performance outcomes. It identifies challenges in interpreting the effects of configuration options and introduces the concept of deep variability, which poses risks to the generalization of performance models. The study further emphasizes the importance of understanding input sensitivity and proposes methodologies to train resilient performance models that account for these variabilities.


![2320
# atoms in
universe
231
# seconds in a
human life
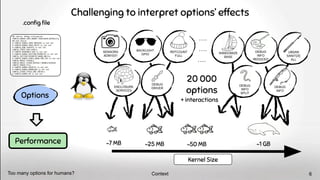
grep
11 options 20 000 options
48 options 119 options
A huge[2]
number of options & configurations
2x
possible
configurations
1 500 options
X
independent
boolean
options
Context
#options is already high & won’t decrease 5
[2] Tianyin Xu, Long Jin, Xuepeng Fan, Yuanyuan Zhou, Shankar Pasupathy, Rukma Talwadker,
Hey, you have given me too many knobs! Understanding and dealing with over-designed configuration in system software, FSE’15, Link](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-5-320.jpg)
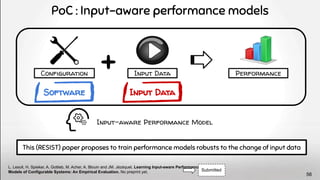
![Whole
Population of
Configurations
Predict
Performance
Sample
Configurations
Measure
Performance
Train Performance
Model [3]
Learning
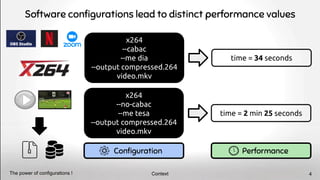
x264 --no-cabac --ref 1 …
compressed.264
video.mkv
x264 --cabac --ref 2 …
compressed.264
video.mkv
x264 --cabac --ref 7 …
compressed.264
video.mkv
Performance
Configurations
Machine
Learning
Configurations Performance
Configurations
Machine
Learning
Performance
24 seconds
57 seconds
39 seconds
[3] J. Guo, K. Czarnecki, S. Apel, N. Siegmund and A.
Wąsowski, Variability-aware performance prediction: A
statistical learning approach, ASE’13,
10.1109/ASE.2013.6693089
Sampling, Measuring,
Context
State-of-the-art Solution :
But not too many options for ML 7](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-7-320.jpg)

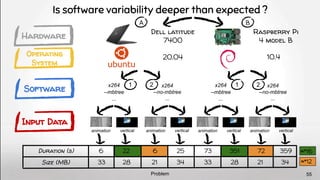
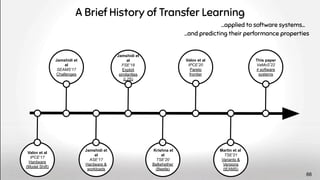
![Performance
?
?
?
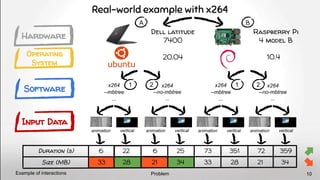
Performance also depends on the software stack
Hardware
Operating
System
Software
Input Data
Problem
Software layer is not enough 9
[4] Pooyan Jamshidi, Norbert Siegmund, Miguel Velez,
Christian Kästner, Akshay Patel, Yuvraj Agarwal,
Transfer Learning for Performance Modeling of
Configurable Systems: An Exploratory Analysis,
ASE’17, Link](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-9-320.jpg)
![Age # Cores GPU
Compil. Version
Version Option Distrib.
Size Length Res.
Run-time
Hardware
Operating
System
Software
Input Data
Introducing Deep Variability[5]
Deep Variability =
set of interactions between
the different elements of
software environment
Impacting performance
distributions
Threatens
the generalisation of
performance models
Bug
Perf. ↗
Perf. ↘
Problem
Introducing deep variability 11
[5] L. Lesoil, M.Acher, A.Blouin, and J-M. Jézéquel,
Deep software variability: Towards handling
cross-layer configuration,VaMoS'21, Link](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-11-320.jpg)
![Age # Cores GPU
Compil. Version
Version Option Distrib.
Size Length Res.
Run-time
Hardware
Operating
System
Software
Input Data
Deep Variability =
set of interactions between
the different elements of
software environment
Impacting performance
distributions
Threatens
the generalisation of
performance models
Bug
Perf. ↗
Perf. ↘
If performance distributions vary with software stacks,
performance models are obsolete when their environment change
Problem
Introducing deep variability 12
Introducing Deep Variability[5] [5] L. Lesoil, M.Acher, A.Blouin, and J-M. Jézéquel,
Deep software variability: Towards handling
cross-layer configuration,VaMoS'21, Link](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-12-320.jpg)



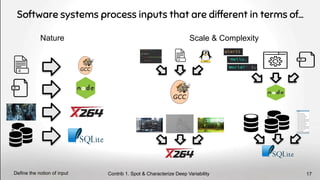
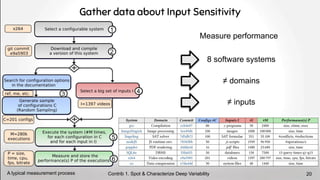
![On the Input Sensitivity[6]
of Configurable Systems
+
Input Video 1
+
Input Video 2
Software Input Data
Contrib 1. Spot & Characterize Deep Variability
≠ inputs ⇒ ≠ perf. distributions 18
[6] Yufei Ding, Jason Ansel, Kalyan Veeramachaneni, Xipeng Shen, Una-May O’Reilly, Saman Amarasinghe,
Autotuning algorithmic choice for input sensitivity. SIGPLAN Not.‘2015, Link](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-18-320.jpg)
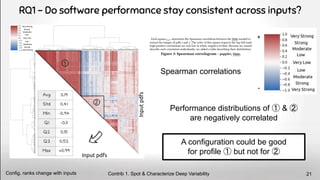

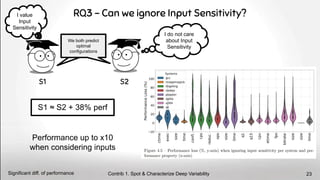


![Input Sensitivity threatens the concrete application of performance models
A model trained on one input will not be reusable on any other input
Conclusion
[7] Stefan Mühlbauer, Florian Sattler, Christian Kaltenecker, Johannes Dorn, Sven Apel, Norbert Siegmund,
Analyzing the Impact of Workloads on Modeling the Performance of Configurable Software Systems, ICSE’23, Link
Our results were also found by another team [7]
Contrib 1. Spot & Characterize Deep Variability
Inputs mess with perf. models 26](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-26-320.jpg)
![Concrete insights from our experiments
Concrete insights about deep var 28
Contrib 1. Spot & Characterize Deep Variability
[not pub] Hardware change perf. distributions linearly (few exceptions)
[A] OS parameter can affect software performance evolution
[B+C] OS version change the effect of OS options
[D+E] Compile-time options mostly interact in a linear way with run-time options
[D+E] Non-linear interactions between compile- & run-time are uncommon
[F] Choice of software can change the impact & effect of common options
[G] Inputs can interact in a non-linear way with run-time options
[G] These interactions are limited to some software & performance properties
[A] L. Lesoil, M. Acher, A. Blouin, J-M. Jézéquel, Beware of the
interactions of variability layers when reasoning about evolution of
mongodb, ICPE'22, Link
[B] H. Martin, M. Acher, JA. Pereira, L. Lesoil, J-M. Jezequel, DE.
Khelladi, Transfer learning across variants and versions : The case
of linux kernel size, TSE’21. Link
[C] M. Acher, H. Martin, JA. Pereira, L. Lesoil, A. Blouin, J-M. Jézéquel,
DE. Khelladi, O. Barais, Feature Subset Selection for Learning Huge
Configuration Spaces: The case of Linux Kernel Size, SPLC’22, Link
[D] X. Tërnava, M. Acher, L. Lesoil, A. Blouin, J-M. Jézéquel, Scratching
the surface of ./configure: Learning the effects of compile-time
options on binary size and gadgets, ICSR’22, Link
[E] L. Lesoil, M. Acher, X. Tërnava, A. Blouin, J-M. Jézéquel, The
interplay of compile-time and run-time options for performance
prediction, SPLC'21, Link
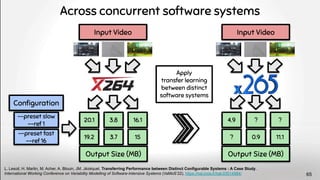
[F] L. Lesoil, H. Martin, M. Acher, A. Blouin and J-M. Jezequel,
Transferring performance between distinct configurable systems :
A case study, VaMoS'22, Link
[G] L. Lesoil, M. Acher, A. Blouin, J-M. Jézéquel, Input sensitivity on
the performance of configurable systems : An Empirical Study,
JSS'23, Link](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-28-320.jpg)
![Age # Cores GPU
Compil. Version
Version Option Distrib.
Size Length Res.
Run-time
Hardware
Operating
System
Software
Input Data
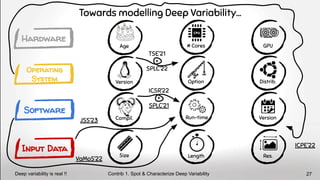
Towards modelling Deep Variability… with other researchers!
Contrib 1. Spot & Characterize Deep Variability
DV is also addressed in SOTA 29
[H] S. Mühlbauer, F. Sattler, C. Kaltenecker, J. Dorn,
S. Apel, N. Siegmund, Analyzing the Impact of
Workloads on Modeling the Performance of
Configurable Software Systems, ICSE’23, Link
[I] S. Mühlbauer, S. Apel, N. Siegmund,
Identifying Software Performance Changes
Across Variants and Versions, ASE’20, Link
[J] MS Iqbal, R. Krishna, MA Javidian, B. Ray,
P. Jamshidi, Unicorn: Reasoning about
Configurable System Performance through the
Lens of Causality, Eurosys’22, Link
–
[K] Marko Boras, Josip Balen, Kresimir Vdovjak,
Performance Evaluation of Linux Operating
Systems, ICSST’20, Link
[L] D. Cotroneo, R. Natella, R. Pietrantuono,
S. Russo, Software Aging Analysis
of the Linux Operating System, ISSRE’10, Link
[H] [I]
[J]
[L]
[K]](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-29-320.jpg)



![Current State-the-art solution : Transfer Learning
Source
Input
Perf
P.
target
?
training
prediction
source
?
Shifting function
Source Model
2
1
Source Model
Shifting function
Training
Test
1
Learn the ≠
between
source & target
2
Train a model
on the source
3
Apply ① and ②
on the test set
Model Shift[8]
3
Measuring, Learning
for each new input
Time- & resource-
consuming for users
Contrib 2. Train Resilient Performance Models
[8] Pavel Valov, Jean-Christophe Petkovich, Jianmei Guo, Sebastian Fischmeister and Czarnecki Krzysztof,
Transferring Performance Prediction Models Across Different Hardware Platforms, ICPE’17, Link
TL avoids deep variability 33
vertical
animation
Target
Input](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-33-320.jpg)
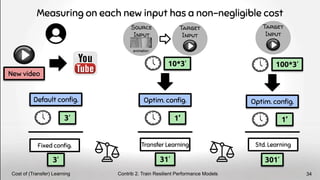
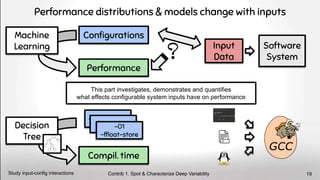
![How? Contextual performance models[9]
with input properties
Spatial = 2.78
Temporal = 0.18
Chunk = 4.42
Color = 0.19
8 Software Systems
+ Domain knowledge
360p
720p
Complexity
Category = Sports
Input Properties
Contrib 2. Train Resilient Performance Models
Include env. properties in training 35
[9] Paul Temple, Mathieu Acher, Jean-Marc Jézéquel, Olivier Barais.
Learning-Contextual Variability Models, IEEE Soft’17, Link](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-35-320.jpg)
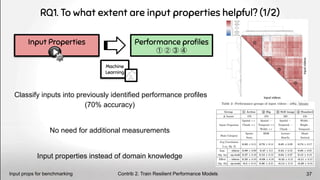
![RQ1. To what extent are input properties helpful? (2/2)
Transfer Learning
Since inputs matter, so does the
choice of the source input [10]
Source
Input
Target
Input
?
Contrib 2. Train Resilient Performance Models
Input props for TL source selection 38
4 different policies to select the
best input:
- uniform selection of input
- closest input properties
- closest performance distr.
- input of the same perf. profile
[10] Rahul Krishna, Vivek Nair, Pooyan Jamshidi and Tim Menzies, Whence to Learn?
Transferring Knowledge in Configurable Systems Using BEETLE, TSE’20, Link](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-38-320.jpg)
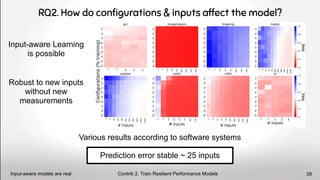





![Deep Variability-Aware Performance-Influence Models
Hardware
Operating
System
Software
Input Data
Built in 16 minutes
lscpu command cat /etc/*-release
version
compile-time options
run-time options
#LOCs for a .c file
resolution for a video
Linux version
Linux variant
distribution
#cores
L1/L2/L3 cache
street price
[11] Y. Wang, V. Lee, GY. Wei, D. Brooks, Predicting New Workload or
CPU Performance by Analyzing Public Datasets, TACO’19, Link
Perspectives
Let’s extend that to other layers ! 48
[9]](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-48-320.jpg)
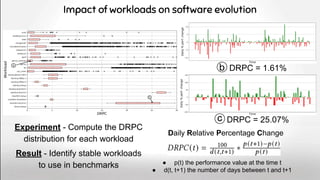
![Build a common benchmark to study Deep Variability
Hardware
Operating
System
Software
Input Data
[12] N. Siegmund, S. Kolesnikov, C. Kästner, S. Apel, D. Batory, M.
Rosenmüller, G. Saake, Predicting Performance via Automated
Feature-Interaction Detection, ICSE’12, Link
Perspectives
A common benchmark for DV 49
0.152.2854 0.155.2917
Weakness of this work:
only one layer at a time !
Share the computational effort
Agree on a common playground to test
deep variability](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-49-320.jpg)


![Joint evolution of mongoDB change points (top) and performance values (bottom)
Code
User #1 User #2
Thread Level = 512
Perf ↘ Perf ↗
Thread Level = 1
Dev
?
Across time
Interactions between
the runtime environment &
the evolution of the software
L. Lesoil, M. Acher, A. Blouin, JM Jézéquel, Beware of the Interactions of Variability Layers When Reasoning about Evolution of MongoDB,
International Conference on Performance Engineering (ICPE'22). https://hal.archives-ouvertes.fr/hal-03624309/
[1]
53](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-53-320.jpg)
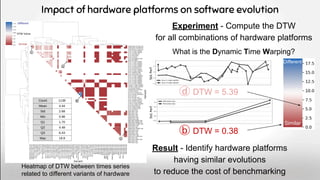
![Tend to confirm the negative results for
hardware of SOTA, e.g. [1]
Across hardware platforms
[1] P. Valov, JC. Petkovich, J. Guo, S. Fischmeister, K. Czarnecki, Transferring Performance Prediction Models Across Different
Hardware Platforms, International Conference on Performance Engineering (ICPE’17). https://dl.acm.org/doi/10.1145/3030207.3030216
Hardware
Software
Input Data
30 clusters of Grid’5000 with different
hardware models
fixed with the same operating system
8 videos
201 configs
Only weak interactions (aka linear)
between hardware and configurations
54](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-54-320.jpg)
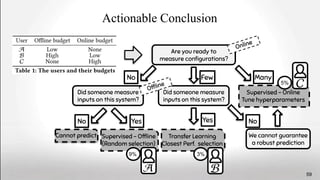
![git clone https://github.com/mirror/x264
./x264 --me tesa
Com
Dow d
Run
Use
./configure [--enable-asm] …
make
./configure --disable-asm …
make
./x264 --me umh ./x264 --me tesa ./x264 --me umh
10.6 seconds 3.4 seconds 81.5 seconds 25.9 seconds
At compile- and run-time
A B
1 1
2 2
L. Lesoil, M. Acher, X. Tërnava, A. Blouin and JM. Jézéquel, The Interplay of Compile-time and Run-time Options for Performance
Prediction, International Systems and Software Product Line Conference 2022 (SPLC ’21). https://hal.ird.fr/INRIA/hal-03286127
60](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-60-320.jpg)
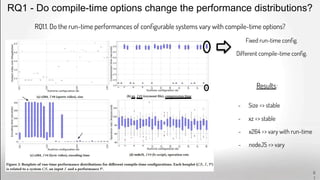

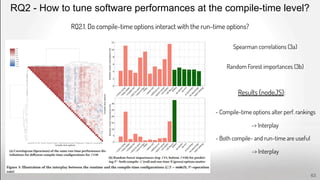


![Problem
Features do not have
the same name
--level --level-idc
The feature of one system
encapsulates one feature
of the other
--fullrange --range full
A feature
is not implemented X --rc-grain
A feature value
is not implemented
--me ‘star’ X
Features do not have the
same default value
--qpmax [51] --qpmax [69]
Different requirements
or feature interactions
.yuv format
=> --input-res
.yuv format
≠> --input-res
Feature ranges differ
between source & target
--crf [0-51] --crf [0-51] --crf [0-69]
Challenges (2/2) - Align Configuration Spaces
Transfer requires a common
configuration space
How to automate the alignment of
config. space?
Different cases
to handle
69](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-69-320.jpg)



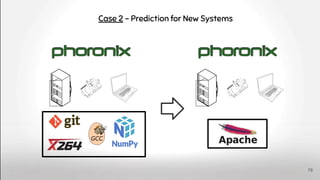
![Predicting performance of hardware platforms based on properties
Built in 16 minutes
[9] Y. Wang, V. Lee, GY. Wei, D. Brooks, Predicting New Workload or
CPU Performance by Analyzing Public Datasets, TACO’19, Link
[9]
Case 1 - Prediction for New SKUs](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-77-320.jpg)
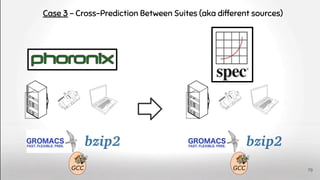
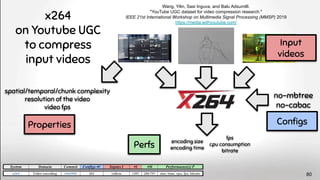
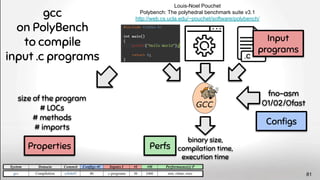
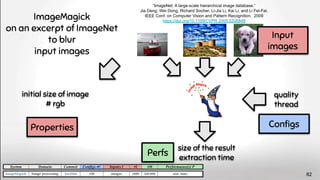
![Lingeling memlimit
minimize
lingeling
on SAT Compet. bench.
to solve
input formulae
Francisco Gomes de Oliveira Neto, Richard Torkar et al.
Evolution of statistical analysis in empirical software engineering research [...]
Journal of Systems and Software, 2019
https://doi.org/10.1016/j.jss.2019.07.002
#conflicts
#reductions
# propositions
# and
# or
Input
formulae
Configs
Properties
Perfs
83](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-83-320.jpg)
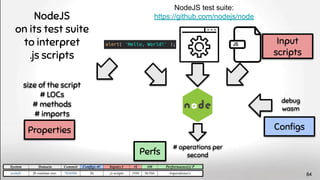
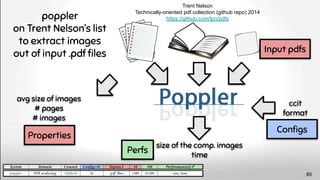
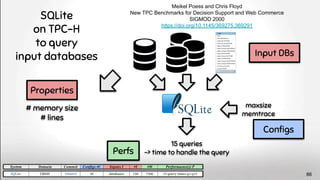
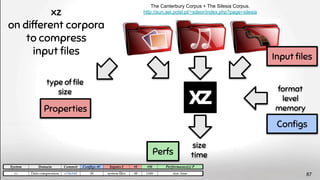

![“Neuroimaging pipelines are known to generate different results
depending on the computing platform where they are compiled and
executed.” Significant differences were revealed between
FreeSurfer version v5.0.0 and the two earlier versions.
[...] About a factor two smaller differences were detected
between Macintosh and Hewlett-Packard workstations
and between OSX 10.5 and OSX 10.6. The observed
differences are similar in magnitude as effect sizes
reported in accuracy evaluations and neurodegenerative
studies.
see also Krefting, D., Scheel, M., Freing, A., Specovius, S., Paul, F., and
Brandt, A. (2011). “Reliability of quantitative neuroimage analysis using
freesurfer in distributed environments,” in MICCAI Workshop on
High-Performance and Distributed Computing for Medical Imaging. 91](https://image.slidesharecdn.com/deepvariabilityphdefense-1-230417212733-f51b5514/85/Deep-Software-Variability-for-Resilient-Performance-Models-of-Configurable-Systems-91-320.jpg)