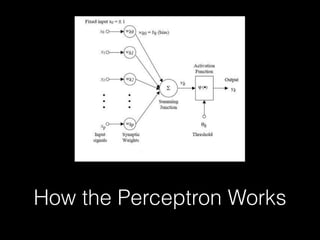
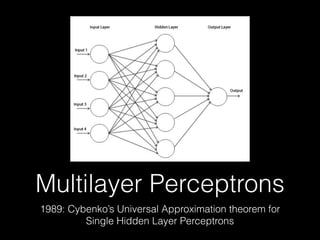
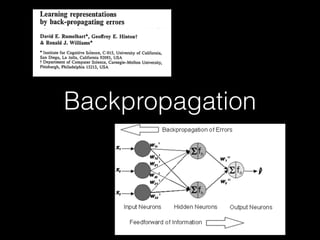
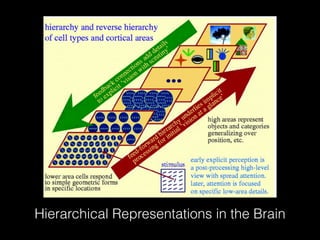
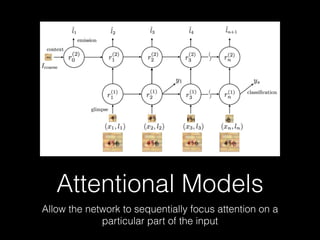
Deep learning has made significant progress in solving problems like visual recognition, speech recognition, and natural language processing. The field began with the perceptron in 1957 but had many limitations. Multilayer perceptrons and backpropagation in the 1980s-90s helped address these issues. Breakthroughs like convolutional neural networks in the 1990s and large datasets like ImageNet in 2012 helped deep learning scale. Factors like GPUs, very deep models, and big data fueled further advances in areas such as image captioning. Future progress may come from faster processing, recurrent and hierarchical models, attentional models, and simulated worlds to generate more training data.



































![[264] large scale deep-learning_on_spark](https://cdn.slidesharecdn.com/ss_thumbnails/246large-scaledeeplearningonspark-150915055051-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)













































