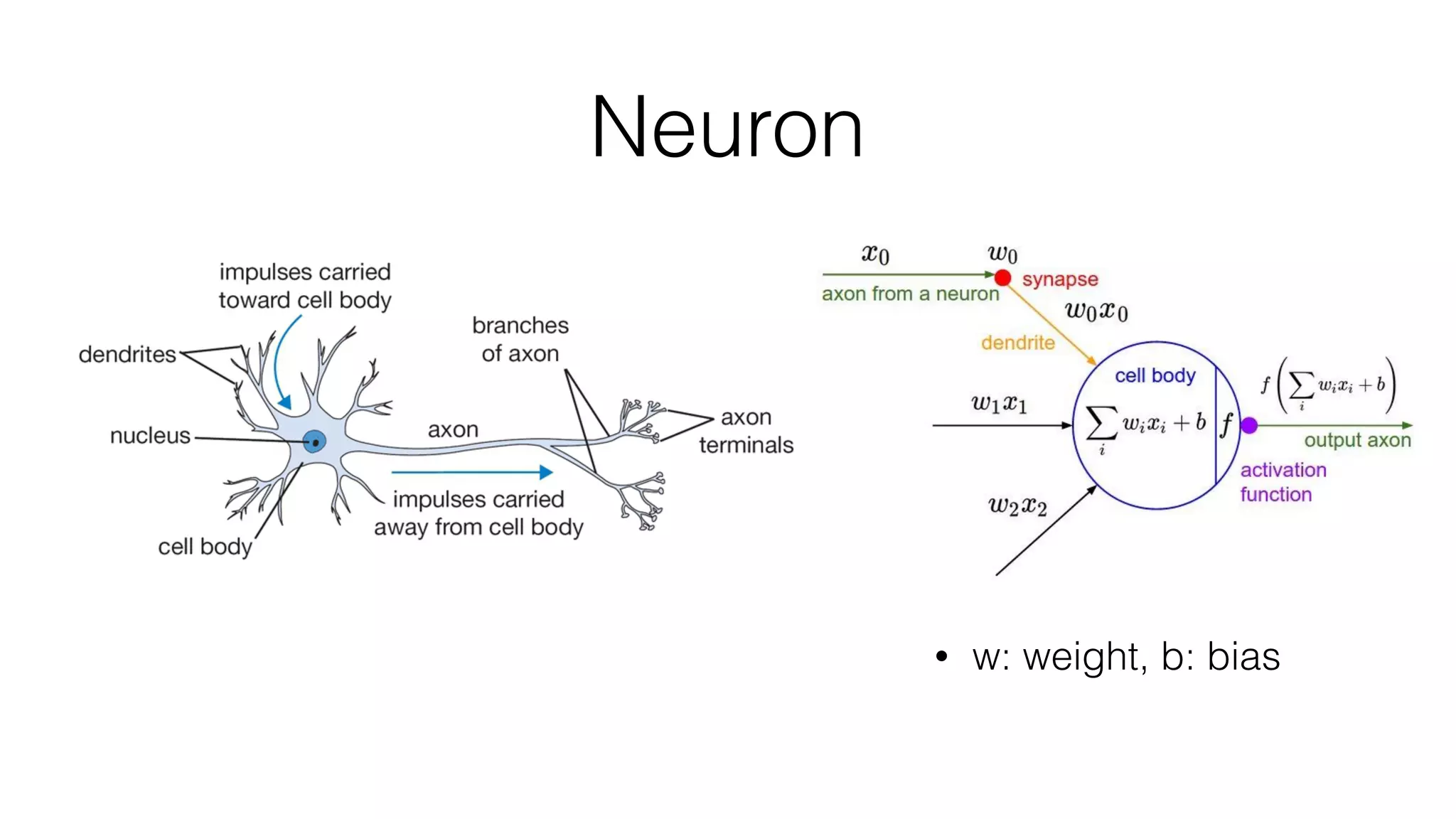
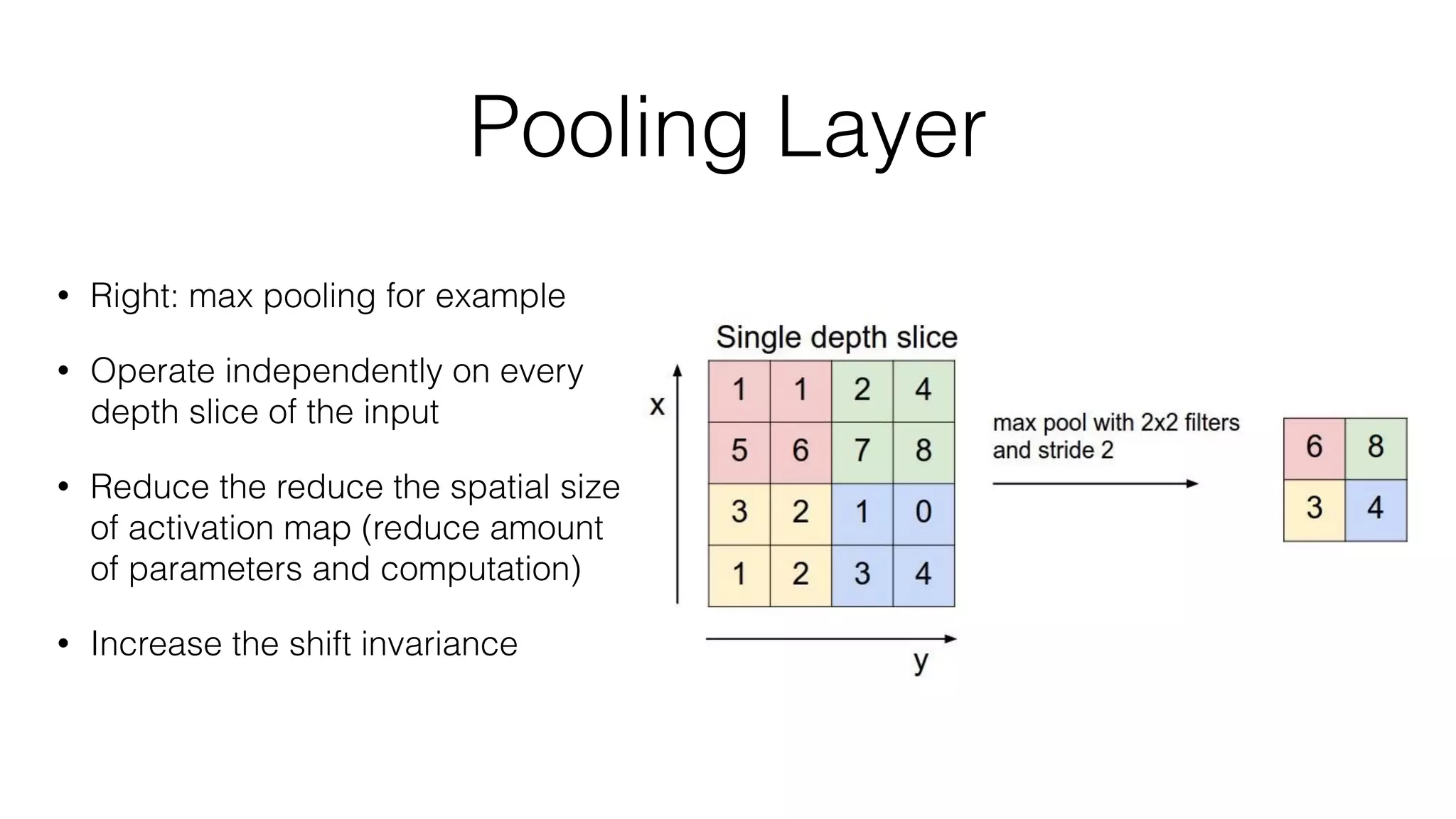
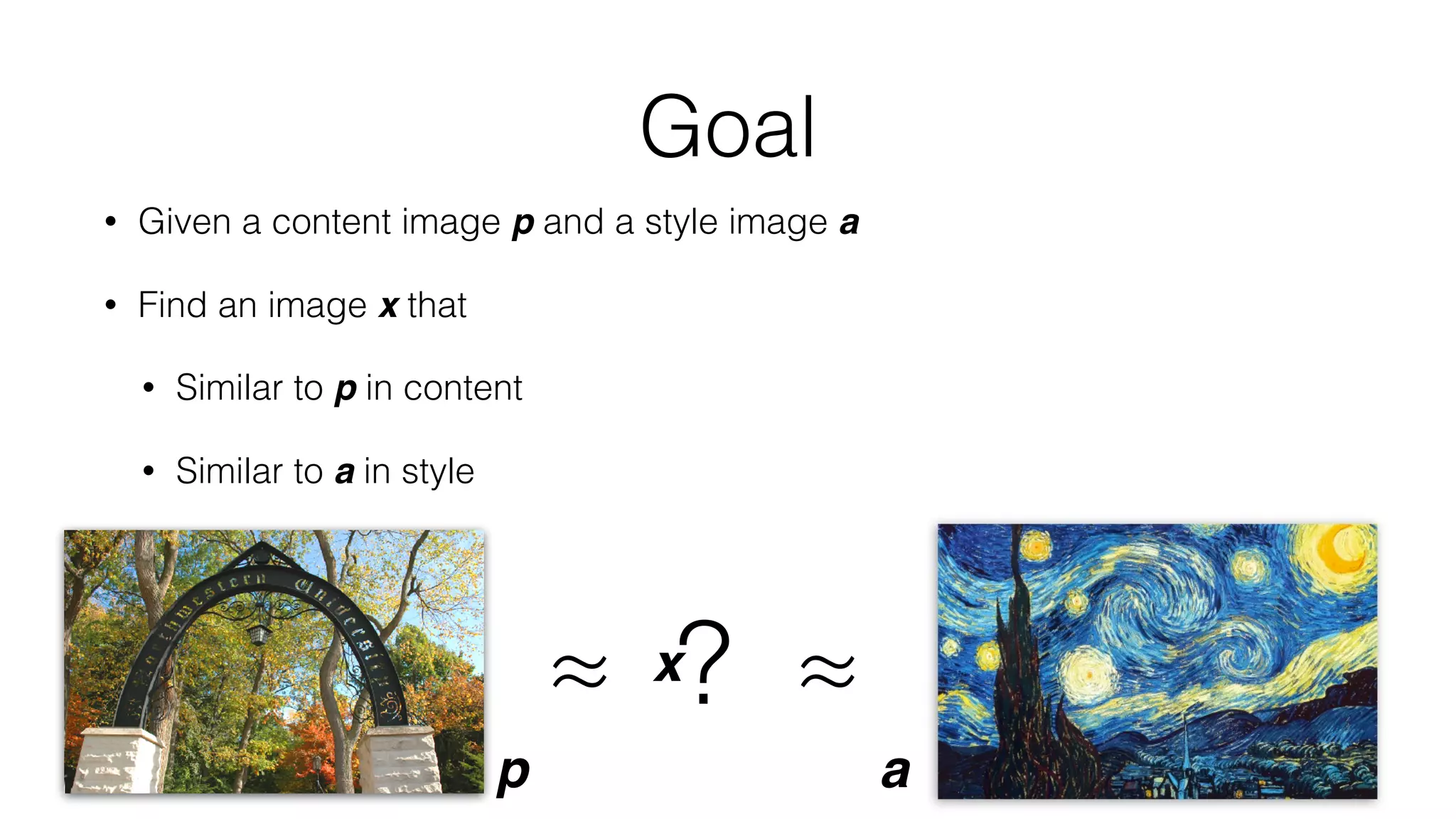
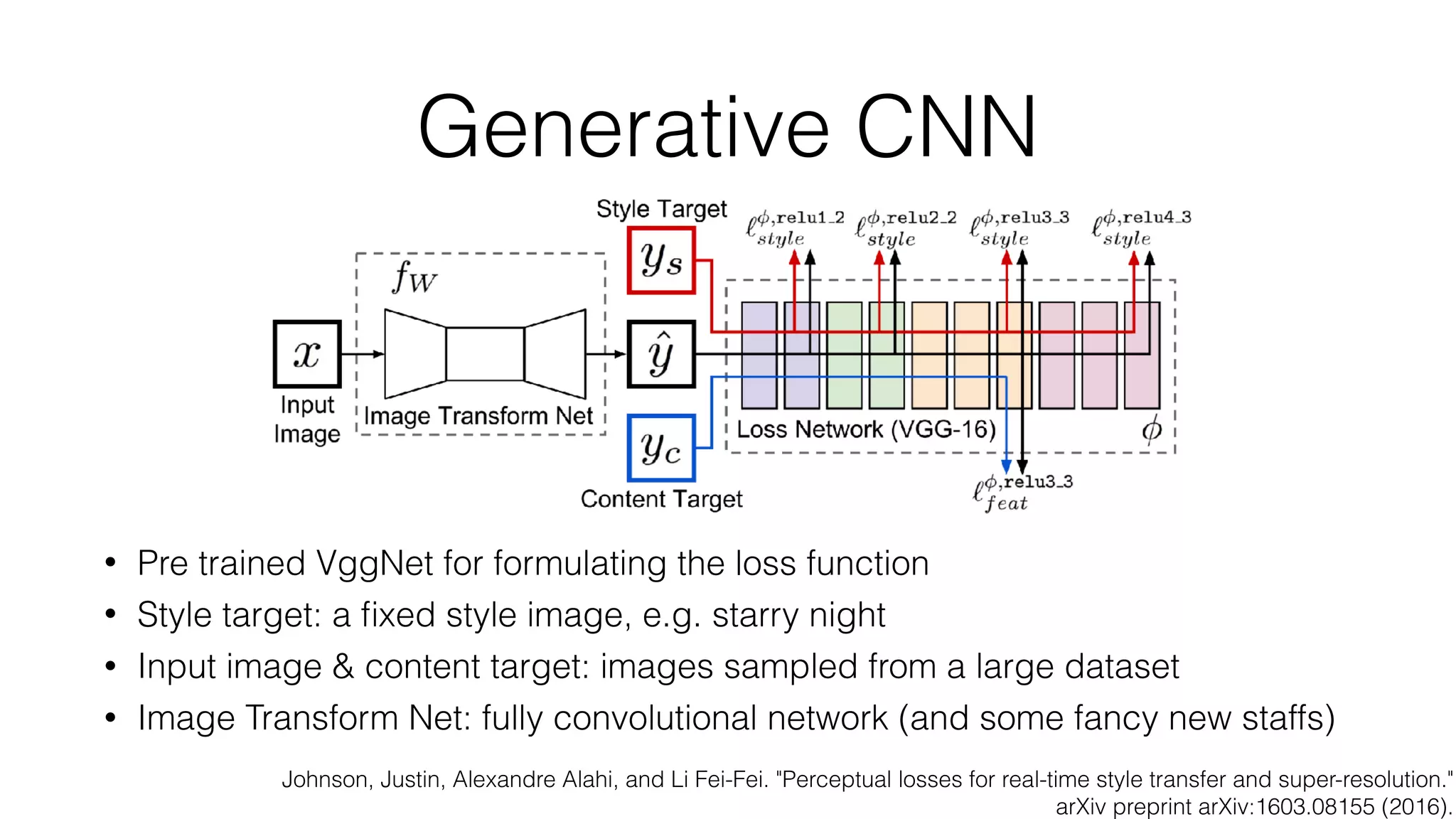
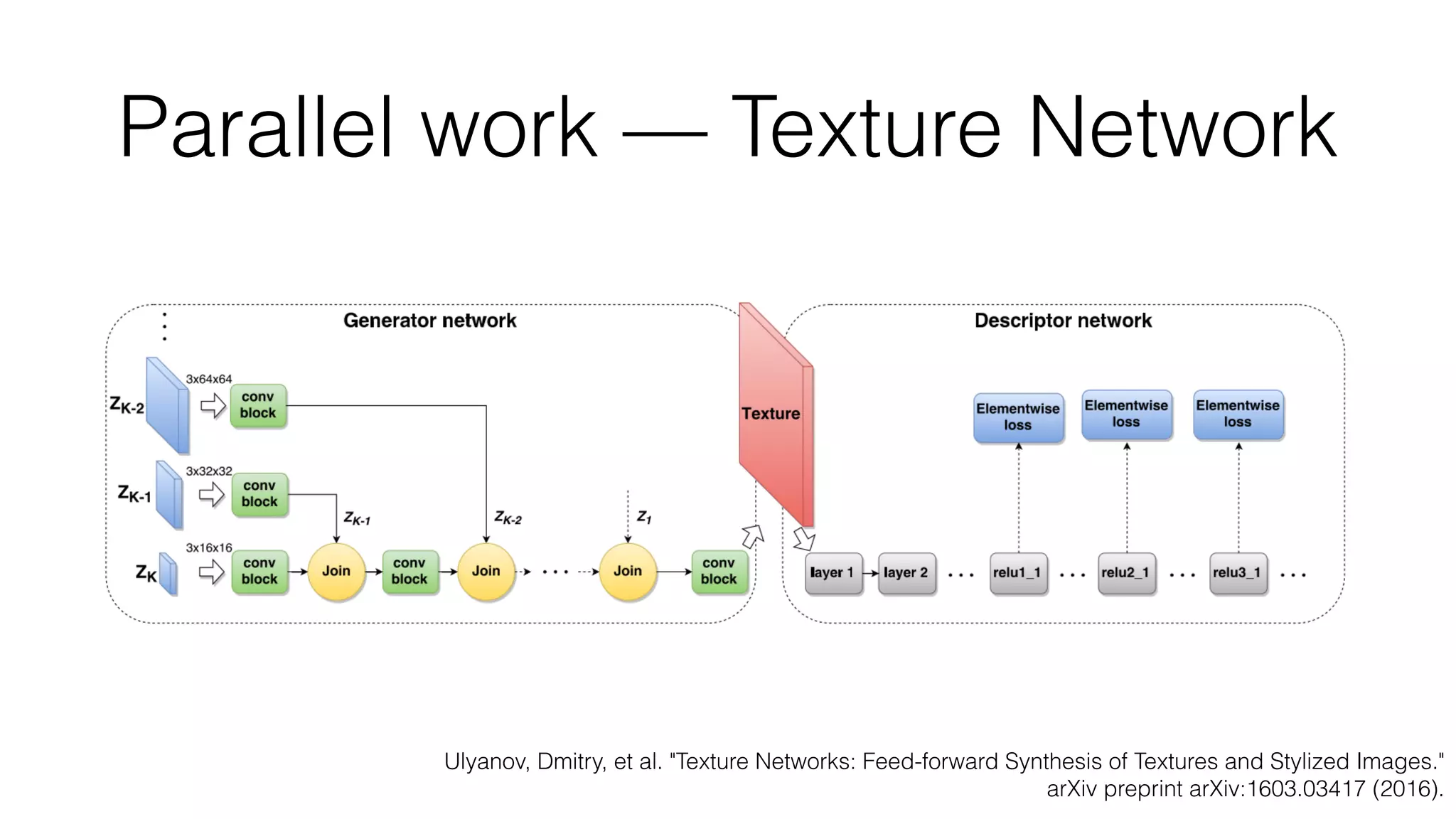
Prisma uses deep learning techniques like neural style transfer to transform photos into artworks. Neural style transfer uses convolutional neural networks to extract features from content and style images, then finds an image that minimizes differences in these features. Early work used iterative optimization, but real-time style transfer trains a generative CNN on a dataset to synthesize stylized images with one forward pass. Prisma's offline mode likely uses a similar generative approach to enable fast stylization on mobile.






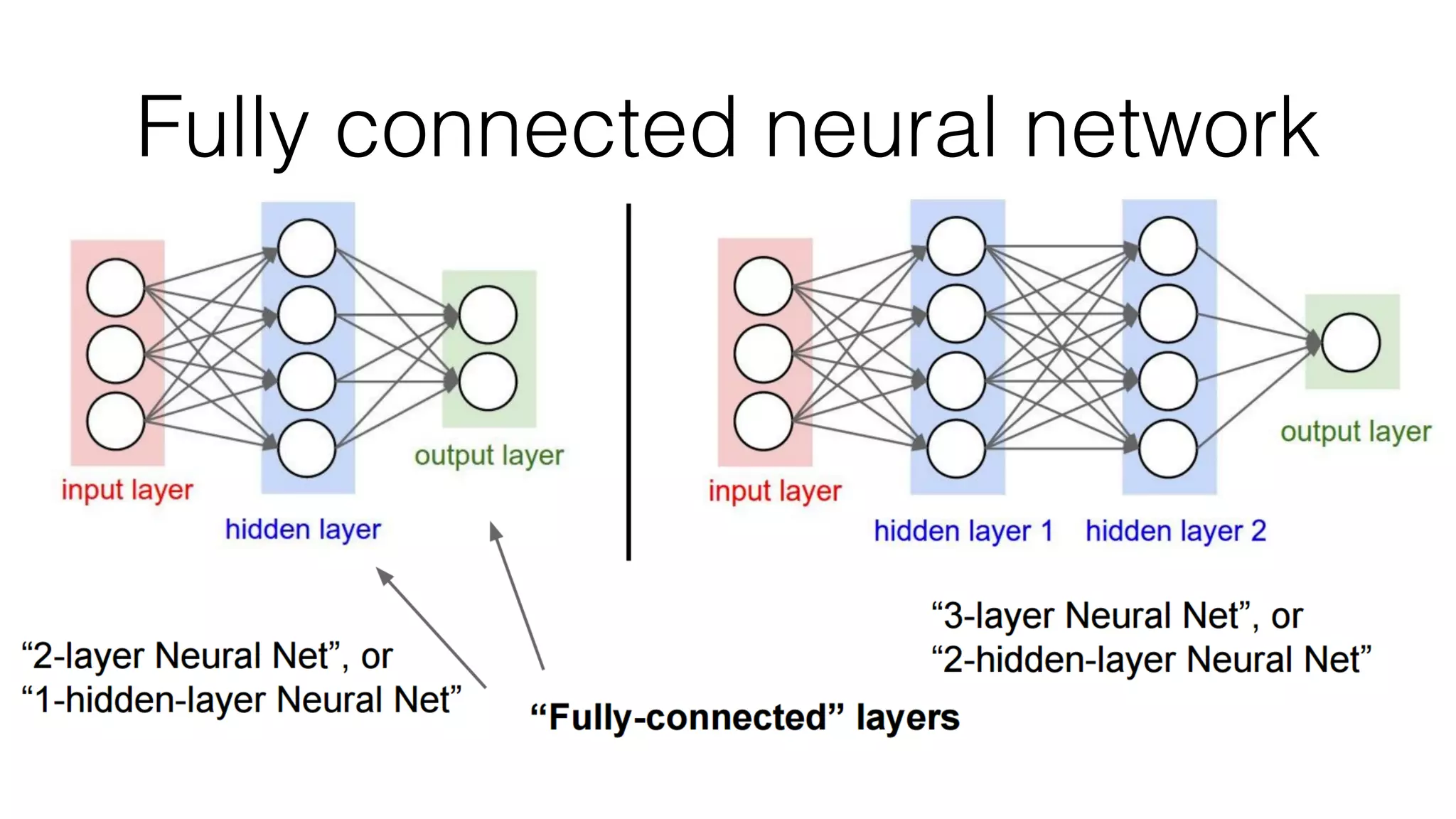
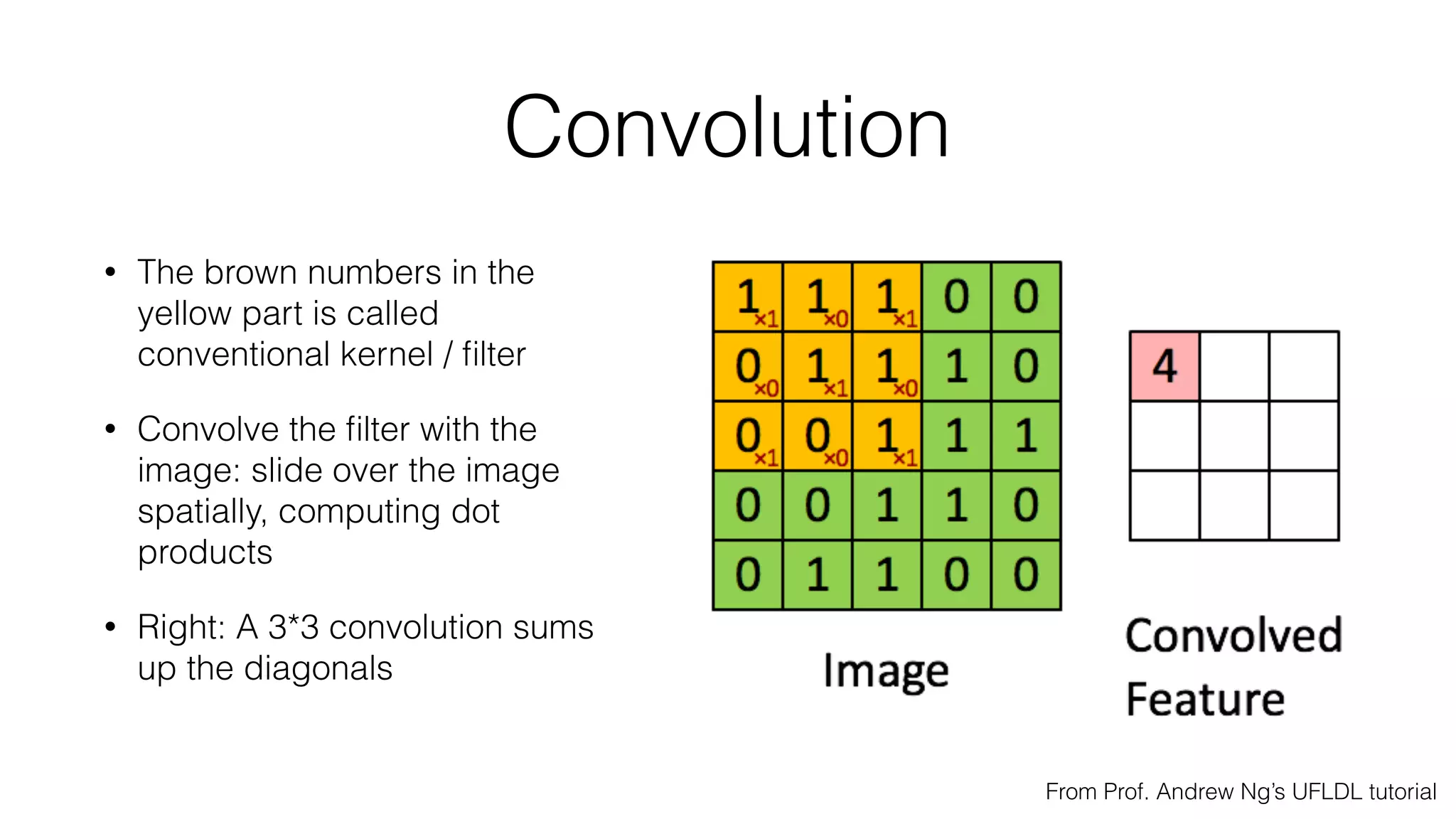
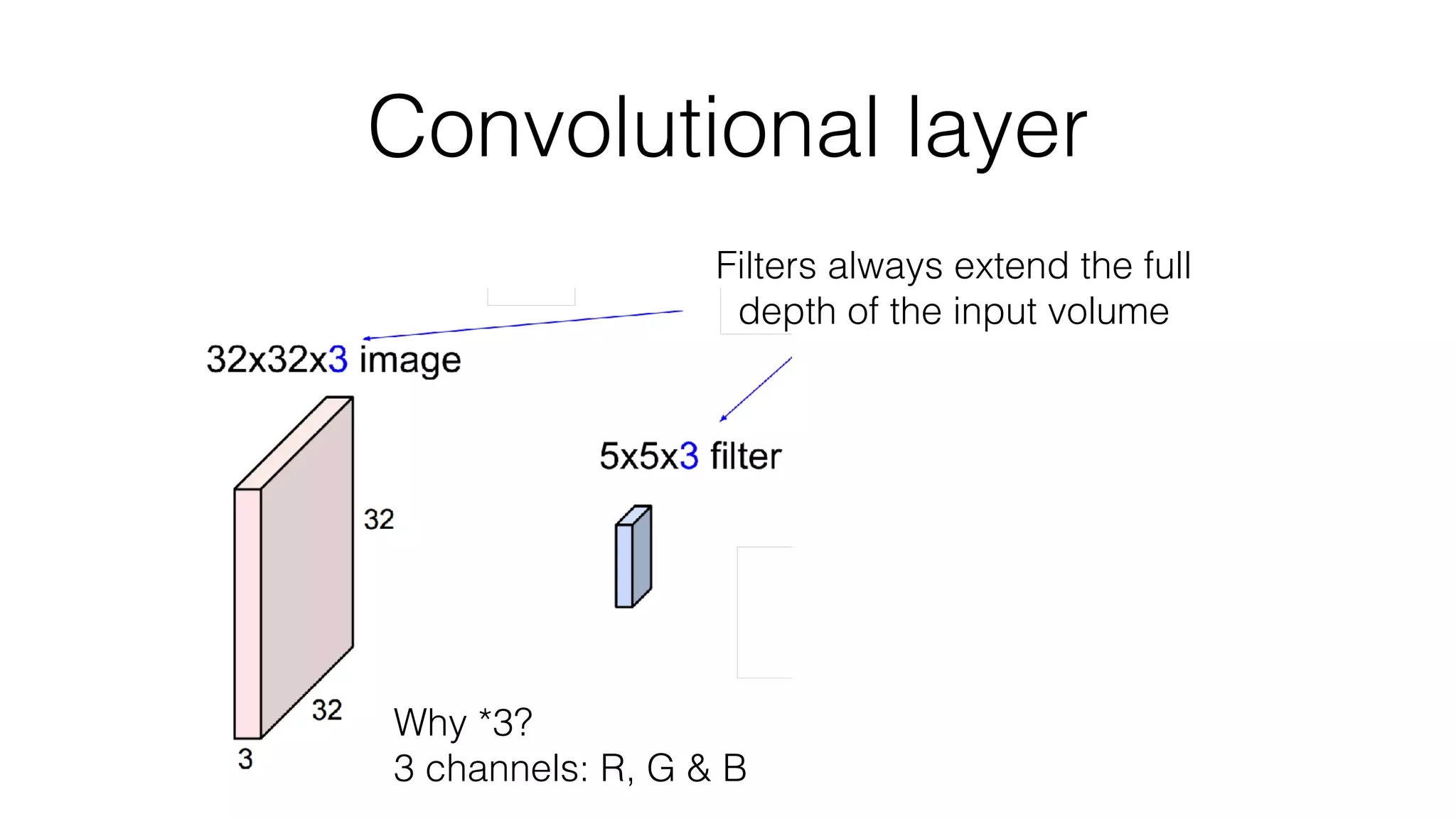
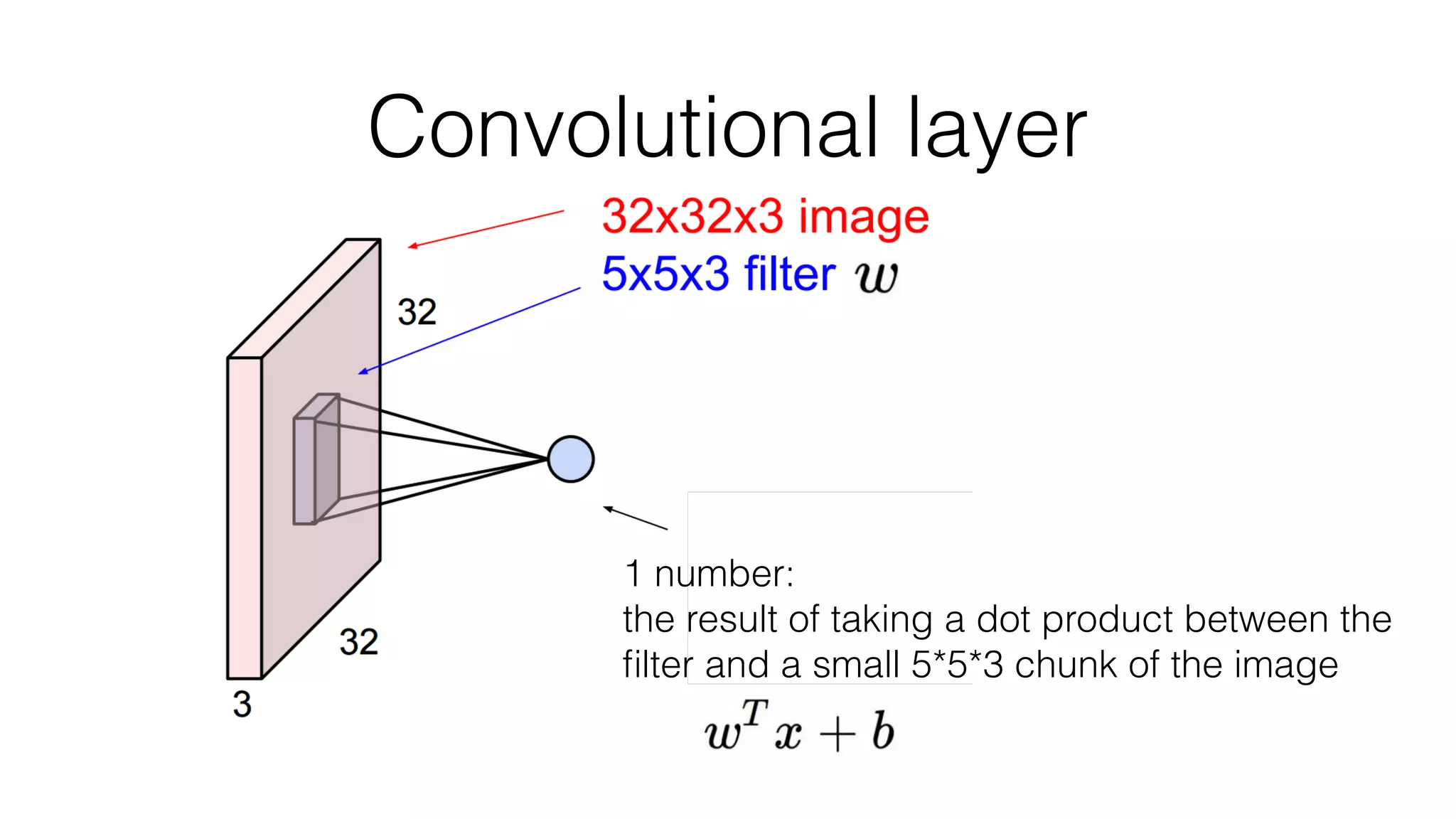
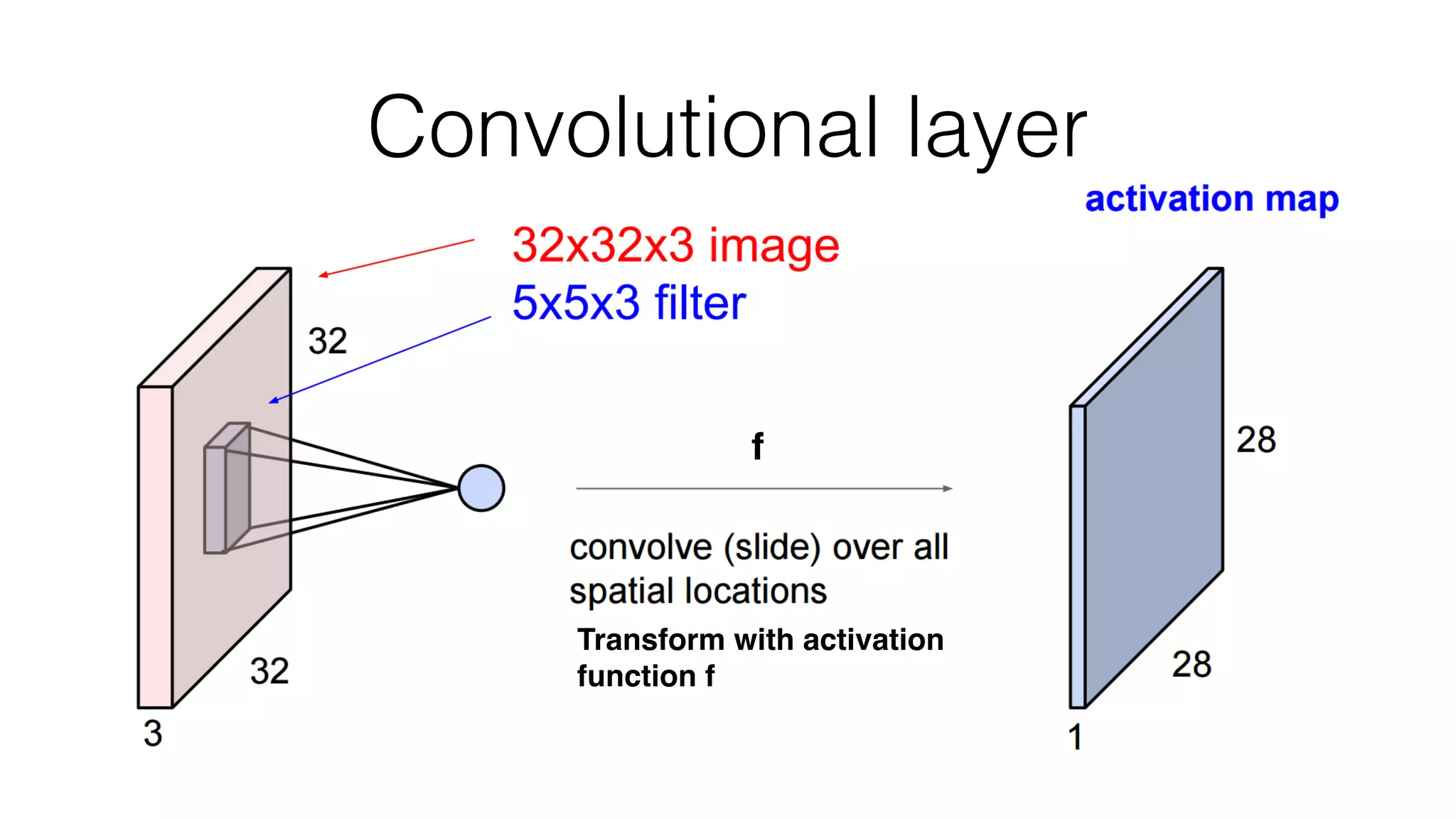
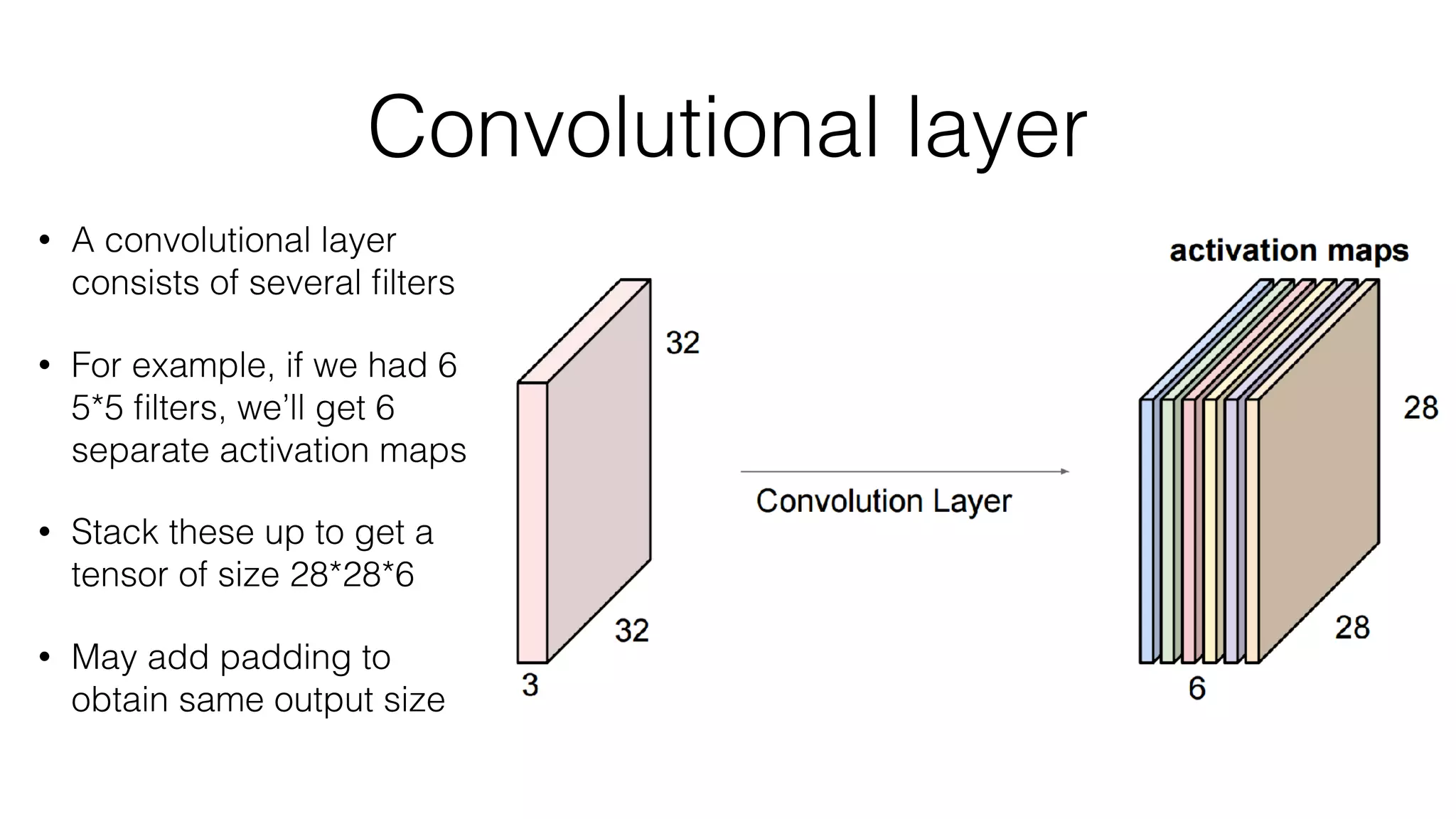
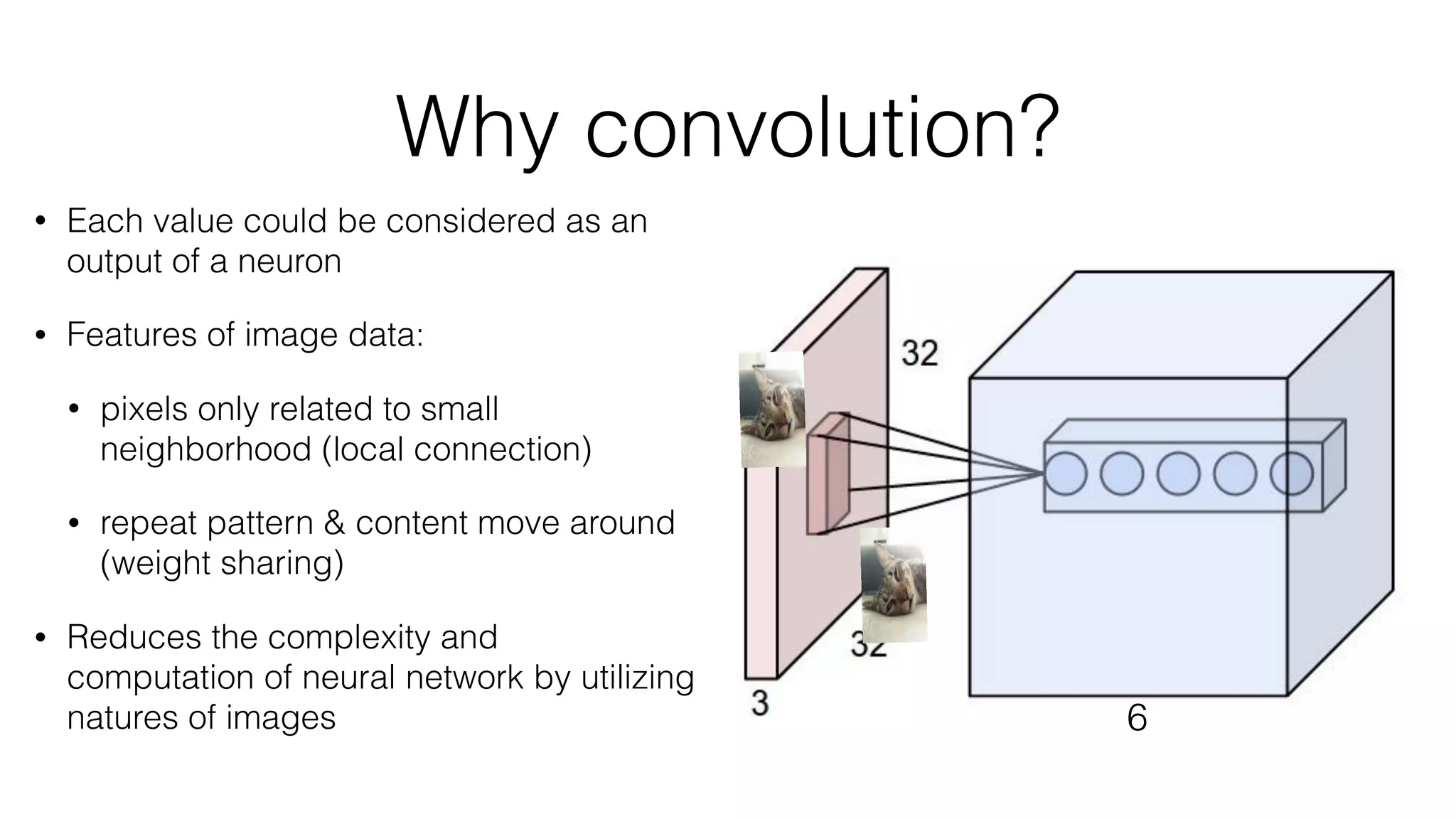

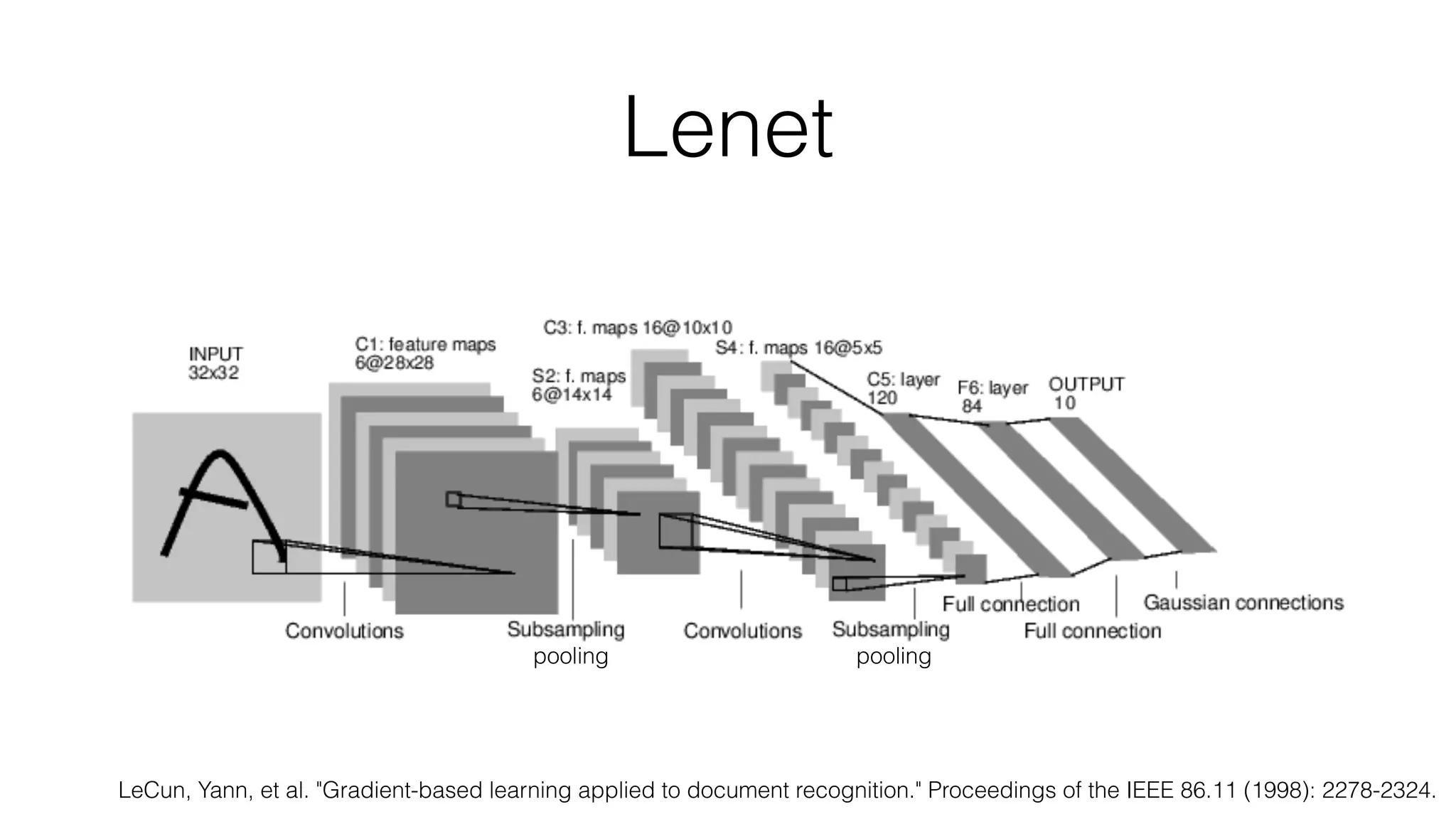


![Typical architecture
• Convolutional part & Fully connected part
• [(CONV-RELU)*N-POOL?]*M-(FC-RELU)*K,SOFTMAX](https://image.slidesharecdn.com/styletemp-161002182243/75/Deep-Learning-behind-Prisma-20-2048.jpg)




































































![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)