Workshop on DataAnalysis for Management
and Social Sciences
Dr. Madhanrajan Udayanan
2.
Today’s Agenda
• BasicStatistics
1. Hypothesis Formulation and testing
2. T – Test
a. One Sample
b. Independent Sample
c. Paired Sample
3. ANOVA
4. Chi – Square Test
5. Correlation
6. Spearman’s Rank Correlation
• Multivariate Analysis
7. Multiple Linear Regression
8. Factor Analysis
3.
Measures of CentralTendency
Mean
Median
Mode
Parametric Test
Independent T-test
Analysis of variance (One-way ANOVA)
Non Parametric Test
Friedman's Test
Kruskal-Wallis (KW) Test
Mann-Whitney U Test
Chi square Test
Wilcoxon Signed rank Test
Pearson’s Correlation
Spearman’s Rank Correlation
Most research projectsshare the same general structure, which could be represented in the
shape of an hourglass .
Beg In With Broad Questions
Narrow Down, Focus In
Operationalize
Observe
Analyze Data
Reach Conclusions
Generalize Back To Questions
7.
Definitions of hypothesis
“Hypotheses are single tentative guesses, good hunches – assumed for use in devising
theory or planning experiments intended to be given a direct experimental test when
possible”. (Eric Rogers, 1966 )
“A hypothesis is a conjectural statement of the relation between two or more variables”.
(Kerlinger, 1956)
“Hypothesis is a formal statement that presents the expected relationship between an
independent and dependent variable.”(Creswell, 1994)
“A research question is essentially a hypothesis asked in the form of a question.”
8.
Nature of Hypothesis
It can be tested – verifiable or falsifiable.
Hypotheses are not moral or ethical questions.
It is neither too specific nor to general.
It is a prediction of consequences.
It is considered valuable even if proven false.
9.
Types of Hypotheses
Thenull hypothesis represents a theory that has been put forward, either because it
is believed to be true or because it is to be used as a basis for argument, but has not
been proved.
Has serious outcome if incorrect decision is made!
The alternative hypothesis is a statement of what a hypothesis test is set up to
establish.
Opposite of Null Hypothesis.
Only reached if H0 is rejected.
Frequently “alternative” is actual desired conclusion of the researcher!
10.
Formulating a hypothesis
…isimportant to narrow a question down to one that can reasonably be studied in a
research project.
The formulation of the hypothesis basically varies with the kind of research project conducted:
QUALITATIVE or QUANTITATIVE
11.
Errors in settingHypotheses
Two types of mistakes are possible while testing the hypotheses.
Type I Error:
A type I error occurs when the null hypothesis (Ho) is wrongly rejected.
For example , A type I error would occur if we concluded that the two drugs produced different
effects when in fact there was no difference between them.
Type II Error:
A type II error occurs when the null hypothesis Ho, is not rejected when it is in fact false.
For example : A type II error would occur if it were concluded that the two drugs produced the same
effect, that is , there is no difference between the two drugs on average, when in fact they produced
different ones.
12.
Hypothesis testing isa four-step procedure:
1. Stating the hypothesis (Null or Alternative)
2. Setting the criteria for a decision
3. Collecting data
4. Evaluate the Null hypothesis
T-test
The t-test comparesthe actual difference between two means in relation to the variation in the data
(expressed as the standard deviation of the difference between the means).
One-Sample T-test
The one-sample t-test allows us to test whether a sample mean is significantly different from a
population mean. When only the sample standard deviation is known. Simply, when to use the one-sample
t-test, you should consider using this test when you have continuous data collected from group that you
want to compare that group’s average scores to some known criterion value (probably a population mean).
Often performed for testing the mean value of distribution.
It can be used under the assumption that sample distribution is normal.
For large samples, the procedure performs often well even for non-normal population.
16.
Independent Sample t-test
Purpose:test whether or not the populations represented by the two samples have a different mean.
Independent Sample t-test measures the significance difference in the means of the Two categories
/variables/Groups.
Examples :- Whether there is a significant difference in the satisfaction level of consumers using
Prepaid and Post Paid Packaging. Here we have Package in two subcategories as a variable and Test
Variable is Satisfaction Level
Social work students have higher GPA’s than nursing students
Social work students volunteer for more hours per week than education majors
17.
Assumptions of IndependentSample t-test
Level Of Measurement:
Independent sample t-test assume that grouping variable or categorical variable should be measured on
Nominal Scale whereas Test variable should be measured on interval or Ratio Scale. This is LOM for this
Test.
Normality:
The test variable should be Normal or Homogeneous. In order to check the homogeneity, Independent
Sample t-test has Levene’s Test.
If Test variable is abnormal or Heterogeneous then we can not proceed to independent sample t-test rather we
have to switch for Non-Parametric alternate to independent Sample t-test i.e. Mann Whitney test etc.
18.
Paired Sample T-test
•A paired sample t test is used to test if an observed difference between two means is
statistically significant i.e. whether there is a significant difference between the average
values of the same measurement made under two different conditions.
• Assumptions for paired sample T-test:
To run the paired sample T-test the data
• Should have normal distribution
• Is a large data set
• Has no outliers
19.
Research Questions forPaired Sample T-test
• Is there an instructional effect taking place in the computer class? Hypothesis for Paired Sample T-
test:
NULL HYPOTHESIS (H0): H0 specifies that the value for the population parameters are the same.
• H0 always includes an equality.
• H0: there is no influence of using internet on academic achievement for this class.
ALTERNATE HYPOTHESIS (H1): H1 always includes a non-equality
• H1: there is an influence of using the internet on academic achievement for this class.
Paired Sample T-test cntd..
20.
Analysis of Variance(ANOVA)
ANOVA measures significant difference among at-least three or more categories.
• Purpose of ANOVA:
• In statistics, analysis of variance (ANOVA) is a collection of statistical models about
comparing the mean values of different groups. There are a few types of ANOVA depending
on the number of treatments and the way they are applied to the subjects in the experiment.
• In SPSS, you can calculate One-way ANOVA in two different ways:-
• Analyze/Compare Means/ One-way ANOVA
• Analyze/ General Linear Model/ Univariate
21.
Analysis of Variance(ANOVA)
Null and Alternate Hypothesis:
• The null hypothesis is that the mean are all equali. Ho: u1=u2=u3=…=ukii. For
Example, with three groups: Ho: u1=u2=u3
• The alternate hypothesis is that at least one of the mean is different from another
• In other words, H1: u1=u2=u3=…=uk would not be an acceptable way to write the
alternate hypothesis (this slightly contradicts Gravettter & Wallnau, but technically
there is no way to test this specific alternative hypothesis with a one-way ANOVA ).
22.
Assumptions
Level of Measurementassumption:
• According to this assumption one variable should be categorical having at least 3-subcategories or nominal
scale and Test variable (dependent) should be measured on interval or Ratio Scale.
Normality:
• Second assumption is Normality or Homogeneity of the Test variable. This means that the test variable
should be normal and we test this by means of Levene’s Test.
• The Hypothesis of ANOVA are
• Null : means across the categories are equal
• Alternate: means across the categories are not equal
23.
Normality
• Homogeneity iswhether the variances in the populations are equal. When conducting an
ANOVA, one of the options is to produce a test of homogeneity in the output, called
Levene’s Test.
• If Levene’s test is significant (p < .05) then equal variances are NOT assumed, called
heterogeneity.
• If Levene’s is not significant (p > .05) then equal variances are assumed, called
homogeneity.
• What if
• If Test variable is not Normal, then we switch to the Non-Parametric alternate to
ANOVA i.e. Kruskal Wallis Test…
24.
Difference from t-Test
ANOVAis different than “t-test” in that the t-test is testing the mean difference between
two groups; whereas ANOVA is testing the mean difference between three or more groups.
Examples:
T-test compares two means to each other(Who is happier: Republicans, Democrats?).
ANOVA compares three or more means to each other(Happier: Republicans, Democrats,
Independents, etc.)
25.
Extension of ANOVA……PostHoc
• ANOVA Sees only significant difference (Yes/No).
• In order to extend this analysis of measure of difference from one subsection
to another subsection, we proceed to Post Hoc test. With in Post Hoc test we
have further sub-categories in terms of Homogeneity or Heterogeneity.
• If Normal we proceed as ANOVA to Post Hoc to Tukey
• If Not Normal ANOVA to Post Hoc to Dunett’s
26.
Correlation
• The bivariatePearson Correlation produces a sample correlation coefficient, r, which measures the
strength and direction of linear relationships between pairs of continuous variables. By extension, the
Pearson Correlation evaluates whether there is statistical evidence for a linear relationship among the
same pairs of variables in the population, represented by a population correlation coefficient, ρ (“rho”).
The Pearson Correlation is a parametric measure.
• This measure is also known as:
• Pearson’s correlation
• Pearson product-moment correlation (PPMC)
27.
The Chi-Square Test
TheChi-Square Test of Independence is commonly used to test the following:
Statistical independence or association between two or more categorical variables.
The Chi-Square Test of Independence can only compare categorical variables. It cannot
make comparisons between continuous variables or between categorical and continuous
variables.
Additionally, the Chi-Square Test of Independence only assesses associations between
categorical variables, and can not provide any inferences about causation.
If your categorical variables represent "pre-test" and "post-test" observations, then the chi-
square test of independence is not appropriate.
Linear regression
• Lineardependence: constant rate of increase of one variable with respect to another (as opposed
to, e.g., diminishing returns).
• Regression analysis describes the relationship between two (or more) variables.
• Examples:
• Income and educational level
• Demand for electricity and the weather
• Home sales and interest rates
• Our focus:
•Gain some understanding of the mechanics.
• the regression line
• regression error
• Learn how to interpret and use the results.
• Learn how to setup a regression analysis.
31.
Two main questions:
•Predictionand Forecasting
• Predict home sales for December given the interest rate for this month.
• Use time series data (e.g., sales vs. year) to forecast future performance (next
year sales).
• Predict the selling price of houses in some area.
• Collect data on several houses (# of BR, #BA, sq.ft, lot size, property tax) and their
selling price.
• Can we use this data to predict the selling price of a specific house?
•Quantifying causality
• Determine factors that relate to the variable to be predicted; e.g., predict
growth for the economy in the next quarter: use past history on quarterly
growth, index of leading economic indicators, and others.
• Want to determine advertising expenditure and promotion for the 1999 Ford
Explorer.
•Sales over a quarter might be influenced by: ads in print, ads in radio, ads in TV, and
other promotions.
32.
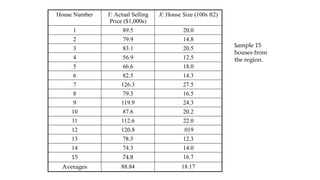
Example
Predict the sellingprices of houses in the region.
• Intuitively, we should compare the house for which we need a predicted selling price with houses that have sold recently in
the same area, of roughly the same size, same style etc.
• Idea: Treat it as a multiple sample problem.
• Unfortunately, the list of houses meeting these criteria may be quite small, or there may not be a house of exactly the same
characteristics.
• Alternative approach: Consider the factors that determine the selling price of a house in this region.
Collect recent historical data on selling prices, and a number of characteristics about each house sold (size,
age, style, etc.).
• Idea: one sample problem
• To predict the selling price of a house without any particular knowledge of the house, we use the average selling price of all of the
houses in the data set.
• Better idea:
• One of the factors that cause houses in the data set to sell for different amounts of money is the fact that houses come in various sizes.
• A preliminary model might posit that the average value per square foot of a new house is $40 and that the average lot sells for $20,000.
The predicted selling price of a house of size X (in square feet) would be: 20,000 + 40X.
• A house of 2,000 square feet would be estimated to sell for 20,000 + 40(2,000) = $100,000.
33.
•Probability Model:
• Weknow, however, that this is just an approximation, and the selling price of this particular house of 2,000
square feet is not likely to be exactly $100,000.
• Prices for houses of this size may actually range from $50,000 to $150,000.
• In other words, the deterministic model is not really suitable. We should therefore consider a probabilistic
model.
•Let Y be the actual selling price of the house. Then
Y = 20,000 + 40x + ,
where (Greek letter epsilon) represents a random error term (which might be positive
or negative).
• If the error term is usually small, then we can say the model is a good one.
• The random term, in theory, accounts for all the variables that are not part of the model (for instance, lot size,
neighborhood, etc.).
• The value of will vary from sale to sale, even if the house size remains constant. That is, houses of the
exact same size may sell for different prices.
34.
Regression Model
• Thevariable we are trying to predict (Y) is called the dependent (or response) variable.
• The variable x is called the independent (or predictor, or explanatory) variable.
• Our model assumes that
E(Y | X = x) = 0
+ 1
x (the “population line”) (1)
The interpretation is as follows:
• When X (house size) is fixed at a level x, then we assume the mean of Y (selling price) to be linear around the level
x, where 0
is the (unknown) intercept and 1
is the (unknown) slope or incremental change in Y per unit change
in X.
• 0
and 1
are not known exactly, but are estimated from sample data. Their estimates are denoted b0
and b1
.
• A simple regression model: Consider a model with only one independent variable,.
• A multiple regression model: a model with multiple independent variables.
Making Inferences aboutCoefficients
• To assess the accuracy of the model, it involves determining whether a particular
variable like house size has any effect on the selling price.
•Suppose that when a regression line is drawn it produces a horizontal line. This means the selling
price of the house is unaffected by the size of the house.
•A horizontal line has a slope of 0, so when no linear relationship exists between an independent
variable and the dependent variable we should expect to get 1
= 0.
•But of course, we only observe estimate of 1
, which might only be “close” to zero. To
systematically determine when 1
might in fact be zero, we will make inferences about it using
our estimate , specifically, we will do hypothesis tests and build confidence intervals.
• Testing 1
, we can test any of the following:
•H0
: 1
= 0 versus HA
: 1
0
•H0
: 1
0 versus HA
: 1
< 0
•H0
: 1
0 versus HA
: 1
> 0
• In each case, the null hypothesis can be reduced to H0
: 1
= 0. The test statistic in
each case is 1
ˆ
1 /
0
ˆ
s
37.
Example
• Can weconclude at the 1% level of significance that the size of a house is linearly related to its selling
price? Test H0
: 1
= 0 versus HA
: 1
0
• Note this is a two-sided test, we are interested in whether there is any relationship at all between price and size.
• Calculate T = (3.879 - 0) / 0.794 = 4.88.
• That is, we are 4.88 standard deviations from 0. So at the 1% level (corresponding to thresholds t(13, 0.005)
= 3.012),
we reject H0
.
• There is sufficient evidence to conclude that house size does linearly affect selling price.
• To get a p-value on this we would need to look up 4.88 inside the t-table.
• It is 0.00024 or 0.024%; very small indeed.
• A 95% confidence interval for 1
is given by
• For this example: It is 3.879 (2.160)(0.794) = 3.879 1.715.
• Using the 15 data points, we are 95% confident that every extra square foot increases the price of the house by anywhere
from $21.64 to $55.94.
1
ˆ
)
025
.
0
,
2
(
1
ˆ
s
t n
38.
Regression Statistics
• DefineR2
= SSR/SST = 1- SSE/SST
• The fraction of the total variation explained by the regression.
• R2
is a measure of the explanatory power of the model.
• Multiple-R = (R2
)1/2
(in one variable case = |rXY|)
• According to the definition of R2
, adding extraneous explanatory variables will artificially inflate the R2
.
• We must be careful in interpreting this number.
• Introducing extra variables can lead to spurious results and can interfere with the proper estimation of slopes for the
important variables.
• In order to penalize an excess of variables, we consider the adjusted R2
, which is
adjusted R2
= 1- [SSE/(n-k-1)]/[SST/(n-1)] .
Here n is the number of data and k is the number of explanatory variables.
• The adjusted R2
thus divides numerator and denominator by their DF.
39.
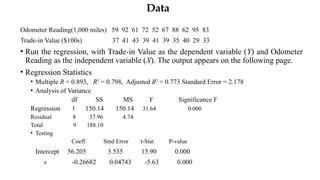
How to determinethe value of used cars that customers trade in
when purchasing new cars?
• Car dealers across North America use the “Red Book” to help them determine the value of used
cars that their customers trade in when purchasing new cars.
• The book, which is published monthly, lists average trade-in values for all basic models of North American,
Japanese and European cars.
• These averages are determined on the basis of the amounts paid at recent used-car auctions.
• The book indicates alternative values of each car model according to its condition and optional features, but it
does not inform dealers how the odometer reading affects the trade in value.
• Question: In an experiment to determine whether the odometer reading should be included in the
Red Book, an interested buyer of used cars randomly selects ten 3-year-old cars of the same
make, condition, and optional features.
• The trade-in value and mileage for each car are shown in the following table.
40.
Data
Odometer Reading(1,000 miles)59 92 61 72 52 67 88 62 95 83
Trade-in Value ($100s) 37 41 43 39 41 39 35 40 29 33
• Run the regression, with Trade-in Value as the dependent variable (Y) and Odometer
Reading as the independent variable (X). The output appears on the following page.
• Regression Statistics
• Multiple R = 0.893, R2
= 0.798, Adjusted R2
= 0.773 Standard Error = 2.178
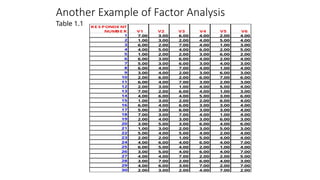
• Analysis of Variance
df SS MS F Significance F
Regression 1 150.14 150.14 31.64 0.000
Residual 8 37.96 4.74
Total 9 188.10
• Testing
Coeff. Stnd Error t-Stat P-value
Intercept 56.205 3.535 15.90 0.000
x -0.26682 0.04743 -5.63 0.000
41.
F and F-significance
•F is a test statistic testing whether the estimated model is meaningful; i.e.,
statistically significant.
•F =MSR/MSE
•A large F or a small p-value (or F-significance) implies that the model is significant.
•It is unusual not to reject this null hypothesis.
42.
Factor Analysis
• Factoranalysis is a class of procedures used for data reduction and summarization.
• It is an interdependence technique: no distinction between dependent and
independent variables.
• Factor analysis is used:
• To identify underlying dimensions, or factors, that explain the correlations
among a set of variables.
• To identify a new, smaller, set of uncorrelated variables to replace the original set
of correlated variables.
43.
Factor Analysis Model
Eachvariable is expressed as a linear combination of factors. The factors are
some common factors plus a unique factor. The factor model is represented as:
Xi = Ai 1F1 + Ai 2F2 + Ai 3F3 + . . . + AimFm + ViUi
where
Xi = i th standardized variable
Aij = standardized mult reg coeff of var i on common factor j
Fj = common factor j
Vi = standardized reg coeff of var i on unique factor i
Ui = the unique factor for variable i
m = number of common factors
44.
• The firstset of weights (factor score coefficients) are
chosen so that the first factor explains the largest
portion of the total variance.
• Then a second set of weights can be selected, so that
the second factor explains most of the residual
variance, subject to being uncorrelated with the first
factor.
• This same principle applies for selecting additional
weights for the additional factors.
Factor Analysis Model
45.
The common factorsthemselves can be expressed as
linear combinations of the observed variables.
Fi = Wi1X1 + Wi2X2 + Wi3X3 + . . . + WikXk
Where:
Fi = estimate of i th factor
Wi= weight or factor score coefficient
k = number of variables
Factor Analysis Model
46.
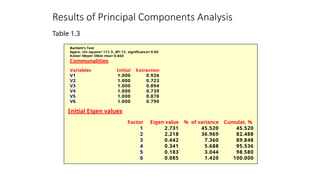
Statistics Associated withFactor Analysis
• Bartlett's test of sphericity. Bartlett's test of sphericity
is used to test the hypothesis that the variables are
uncorrelated in the population (i.e., the population corr
matrix is an identity matrix)
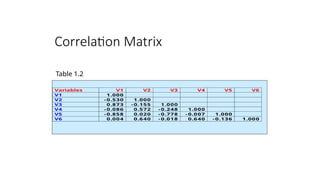
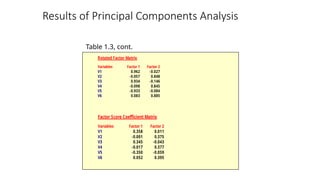
• Correlation matrix. A correlation matrix is a lower
triangle matrix showing the simple correlations, r,
between all possible pairs of variables included in the
analysis. The diagonal elements are all 1.
47.
• Communality. Amountof variance a variable shares with
all the other variables. This is the proportion of variance
explained by the common factors.
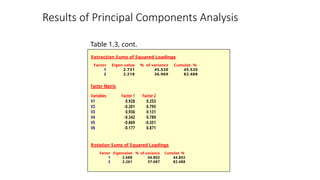
• Eigenvalue. Represents the total variance explained by
each factor.
• Factor loadings. Correlations between the variables and
the factors.
• Factor matrix. A factor matrix contains the factor
loadings of all the variables on all the factors
Statistics Associated with Factor Analysis
48.
• Factor scores.Factor scores are composite scores estimated for
each respondent on the derived factors.
• Kaiser-Meyer-Olkin (KMO) measure of sampling adequacy. Used
to examine the appropriateness of factor analysis. High values
(between 0.5 and 1.0) indicate appropriateness. Values below 0.5
imply not.
• Percentage of variance. The percentage of the total variance
attributed to each factor.
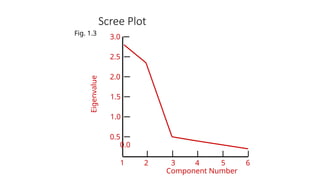
• Scree plot. A scree plot is a plot of the Eigenvalues against the
number of factors in order of extraction.
Statistics Associated with Factor Analysis
49.
• A PrioriDetermination. Use prior knowledge.
• Determination Based on Eigenvalues. Only factors with
Eigenvalues greater than 1.0 are retained.
• Determination Based on Scree Plot. A scree plot is a plot of the
Eigenvalues against the number of factors in order of extraction.
The point at which the scree begins denotes the true number of
factors.
• Determination Based on Percentage of Variance.
Determine the Number of Factors
50.
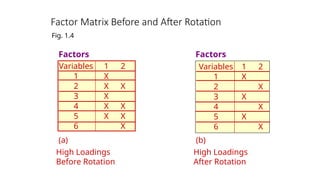
• Through rotationthe factor matrix is transformed into a simpler
one that is easier to interpret.
• After rotation each factor should have nonzero, or significant,
loadings for only some of the variables. Each variable should
have nonzero or significant loadings with only a few factors, if
possible with only one.
• The rotation is called orthogonal rotation if the axes are
maintained at right angles.
Rotation of Factors
51.
• Varimax procedure.Axes maintained at right angles
-Most common method for rotation.
-An orthogonal method of rotation that minimizes the number of variables with
high loadings on a factor.
-Orthogonal rotation results in uncorrelated factors.
• Oblique rotation. Axes not maintained at right angles
-Factors are correlated.
-Oblique rotation should be used when factors in the population are likely to be
strongly correlated.
Rotation of Factors
52.
• A factorcan be interpreted in terms of the variables that load high on
it.
• Another useful aid in interpretation is to plot the variables, using the
factor loadings as coordinates. Variables at the end of an axis are
those that have high loadings on only that factor, and hence describe
the factor.
Calculate Factor Scores
The factor scores for the i th factor may be estimated as follows:
Fi = Wi1 X1 + Wi2 X2 + Wi3 X3 + . . . + Wik Xk
Interpret Factors
53.
• The correlationsbetween the variables can be deduced from the
estimated correlations between the variables and the factors.
• The differences between the observed correlations (in the input
correlation matrix) and the reproduced correlations (estimated
from the factor matrix) can be examined to determine model fit.
These differences are called residuals.
Determine the Model Fit
54.
Another Example ofFactor Analysis
• To determine benefits from toothpaste
• Responses were obtained on 6 variables:
V1: It is imp to buy toothpaste to prevent cavities
V2: I like a toothpaste that gives shiny teeth
V3: A toothpaste should strengthen your gums
V4: I prefer a toothpaste that freshens breath
V5: Prevention of tooth decay is not imp
V6: The most imp consideration is attractive teeth
• Responses on a 7-pt scale (1=strongly disagree; 7=strongly agree)
Factor Matrix Beforeand After Rotation
Factors
(a)
High Loadings
Before Rotation
Fig. 1.4
(b)
High Loadings
After Rotation
Factors
Variables
1
2
3
4
5
6
1
X
X
X
X
X
2
X
X
X
X
1
X
X
X
2
X
X
X
Variables
1
2
3
4
5
6




































![Regression Statistics
• Define R2
= SSR/SST = 1- SSE/SST
• The fraction of the total variation explained by the regression.
• R2
is a measure of the explanatory power of the model.
• Multiple-R = (R2
)1/2
(in one variable case = |rXY|)
• According to the definition of R2
, adding extraneous explanatory variables will artificially inflate the R2
.
• We must be careful in interpreting this number.
• Introducing extra variables can lead to spurious results and can interfere with the proper estimation of slopes for the
important variables.
• In order to penalize an excess of variables, we consider the adjusted R2
, which is
adjusted R2
= 1- [SSE/(n-k-1)]/[SST/(n-1)] .
Here n is the number of data and k is the number of explanatory variables.
• The adjusted R2
thus divides numerator and denominator by their DF.](https://image.slidesharecdn.com/basicstatistics-250413121955-3e3267ff/85/Basic-Statistics-Until-Regression-in-SPSS-38-320.jpg)