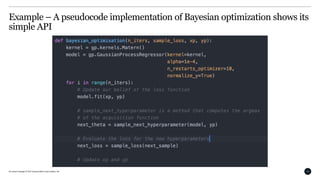
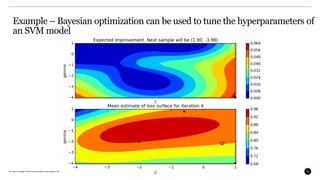
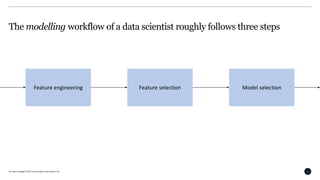
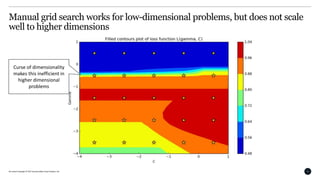
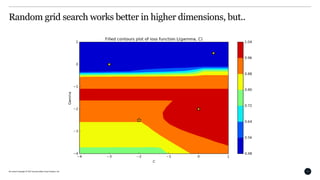
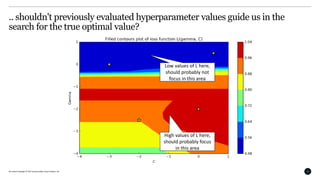
This document discusses Bayesian optimization for hyperparameter tuning. It begins by introducing the modelling workflow of a data scientist and focusing on the model selection step. It then explains that most models have hyperparameters that need to be chosen and the goal is to find hyperparameters that optimize model performance on holdout data. Bayesian optimization is introduced as a method for hyperparameter tuning that builds a probabilistic model of performance using Gaussian processes. It iteratively evaluates hyperparameters chosen by an acquisition function that balances exploitation and exploration. An example of using Bayesian optimization to tune an SVM's hyperparameters is provided, along with practical considerations and open-source tools.











![All content Copyright © 2017 QuantumBlack Visual Analytics Ltd. 17
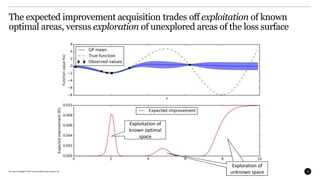
Acquisition functions are used to formalize what constitutes a ”best guess”
𝐸𝐼 𝜃 = 𝔼[max
𝜃
0, 𝑓ℳ 𝜃 − 𝑓ℳ 𝜃 ] ,
𝜃 𝑛𝑒𝑤 = argmax
𝜃
𝐸𝐼(𝜃)](https://image.slidesharecdn.com/pydata-presentation-170512154047/85/Pydata-presentation-17-320.jpg)