Download to read offline


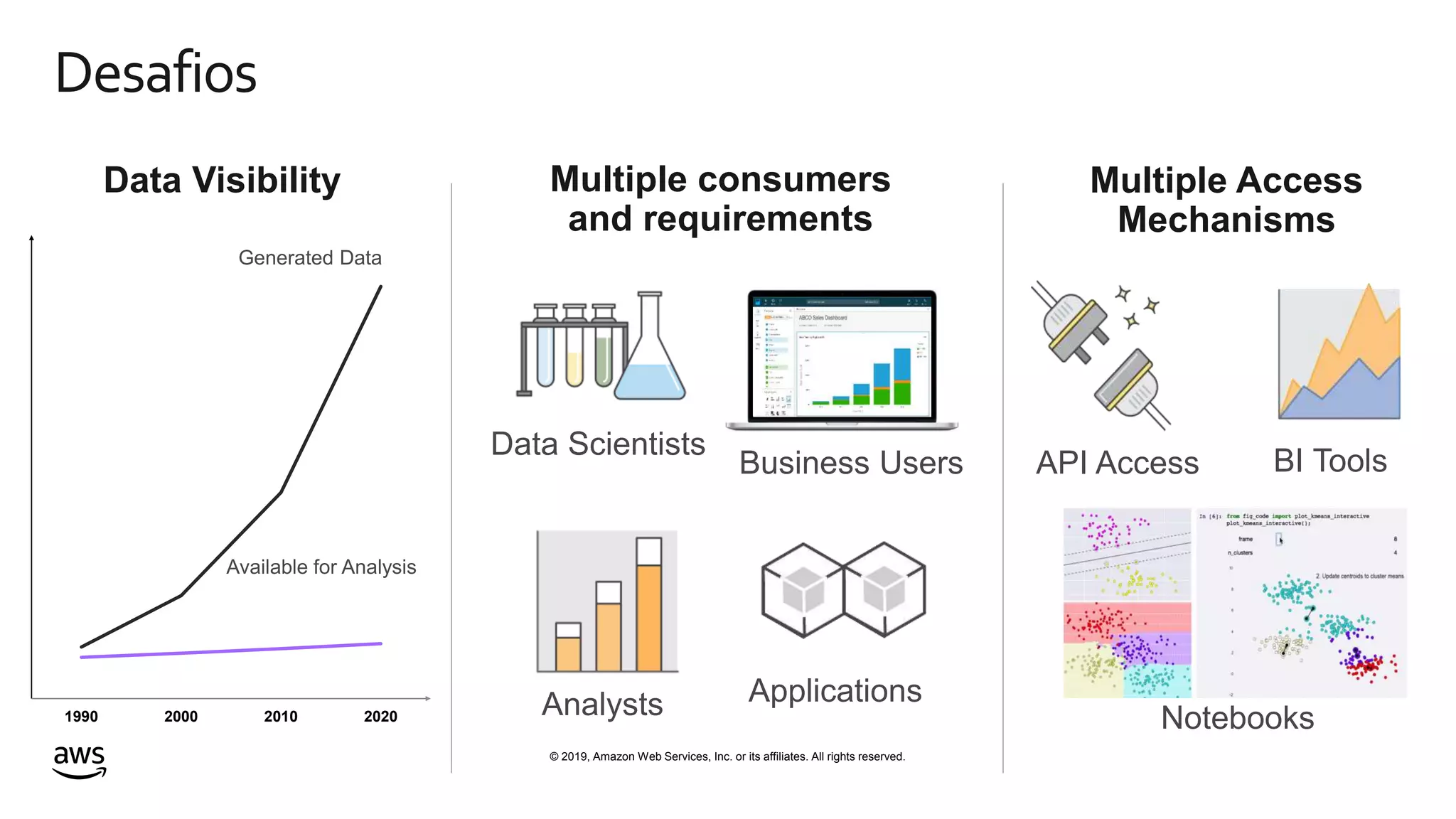
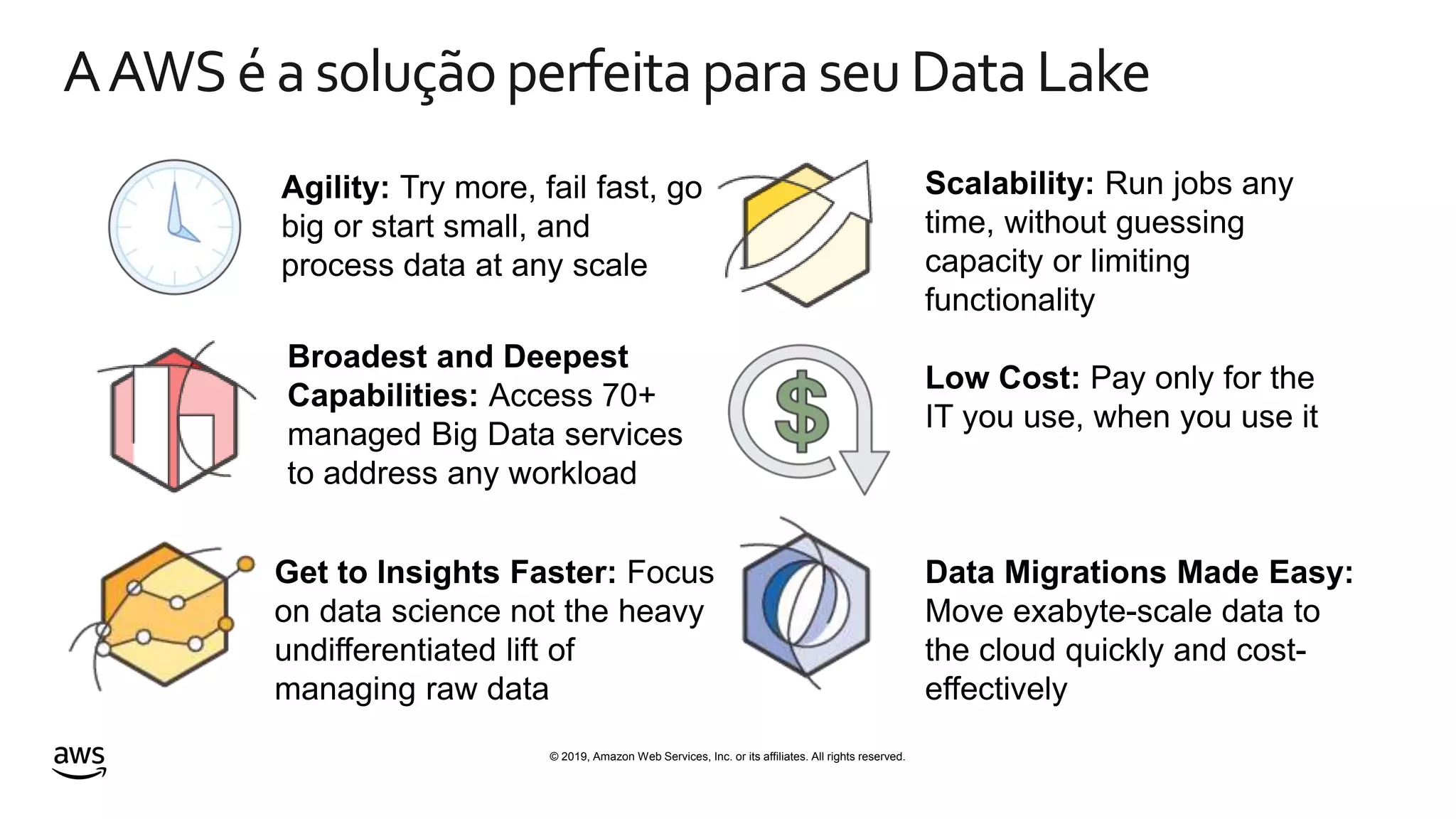


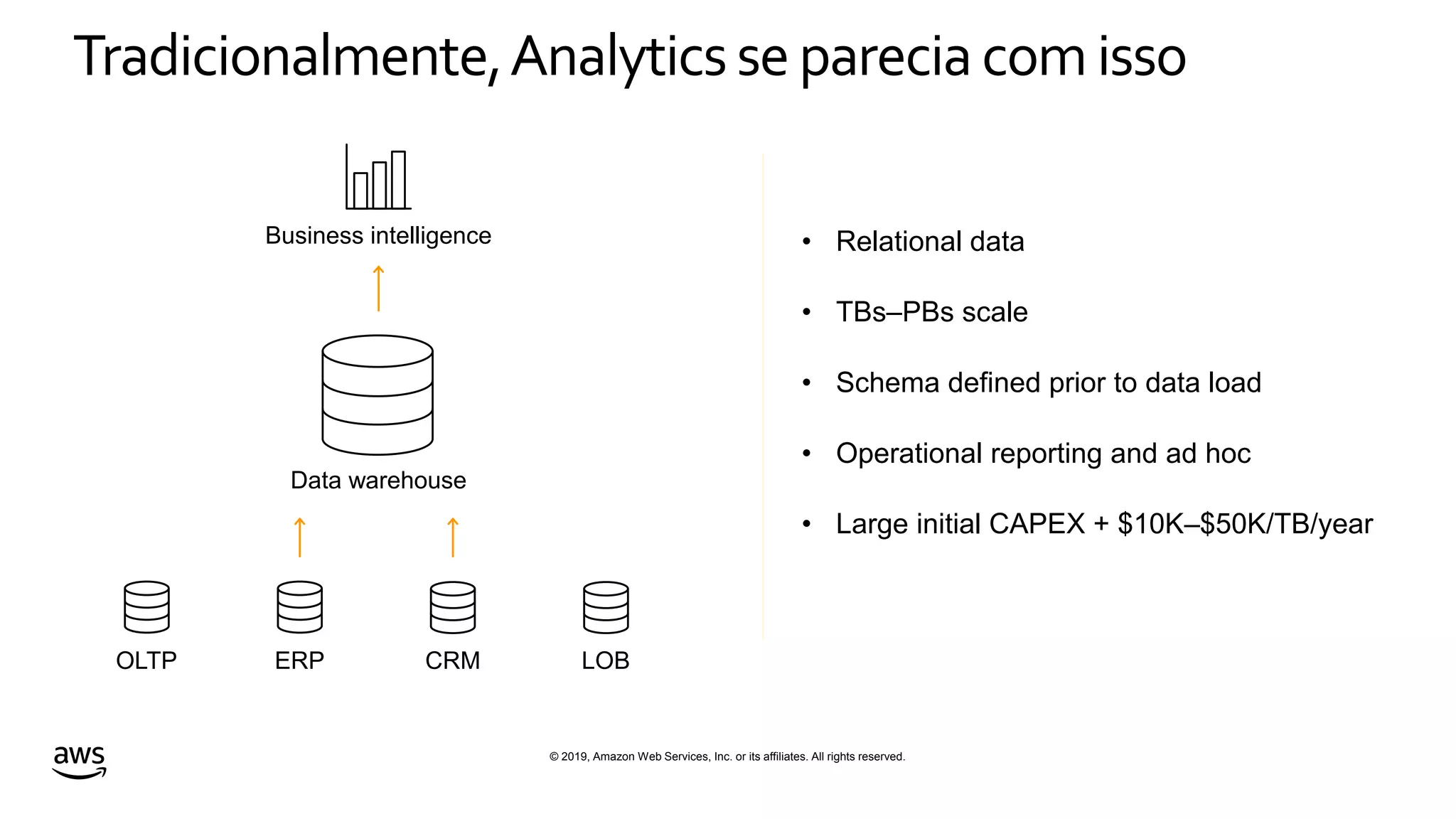



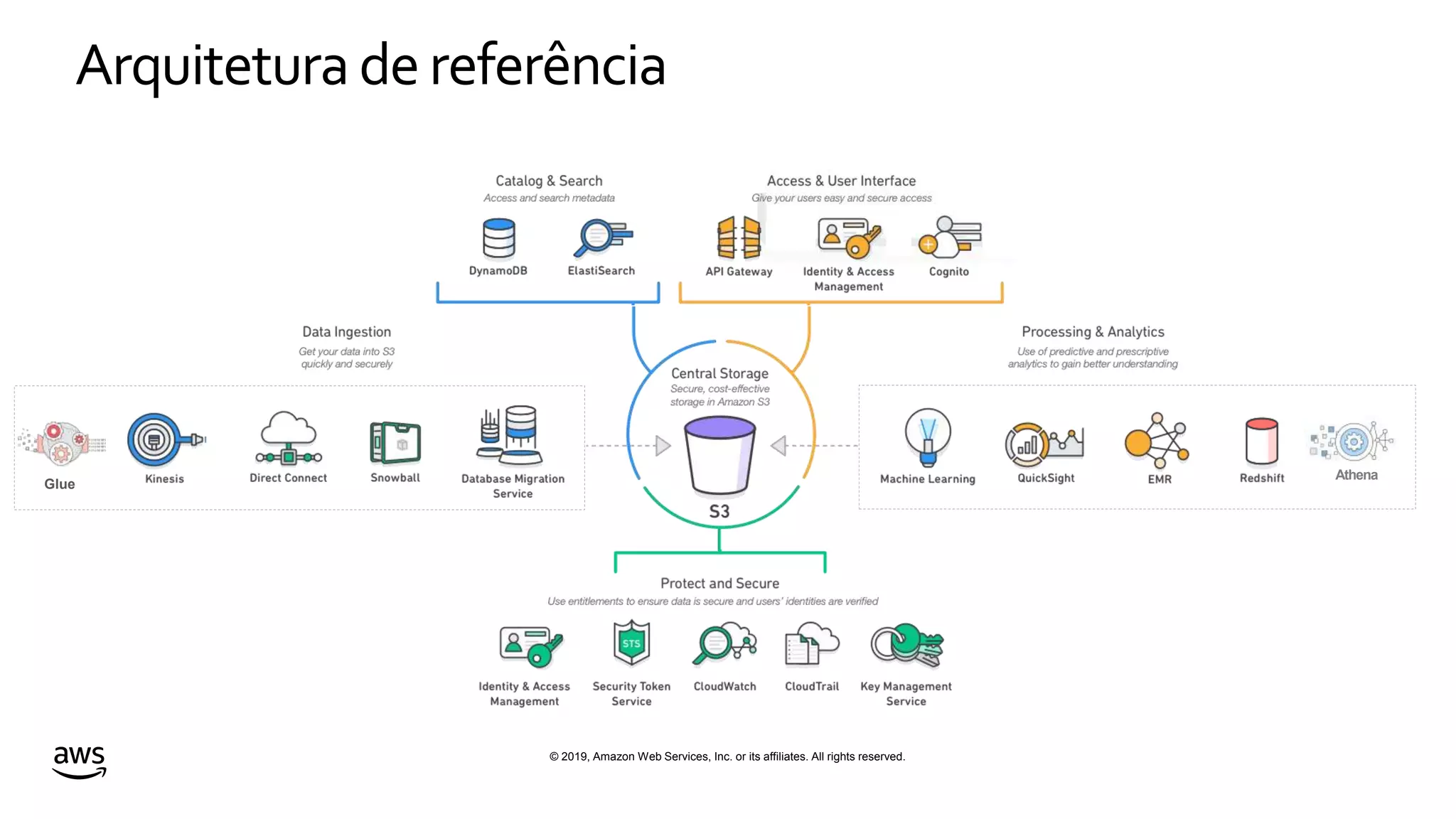


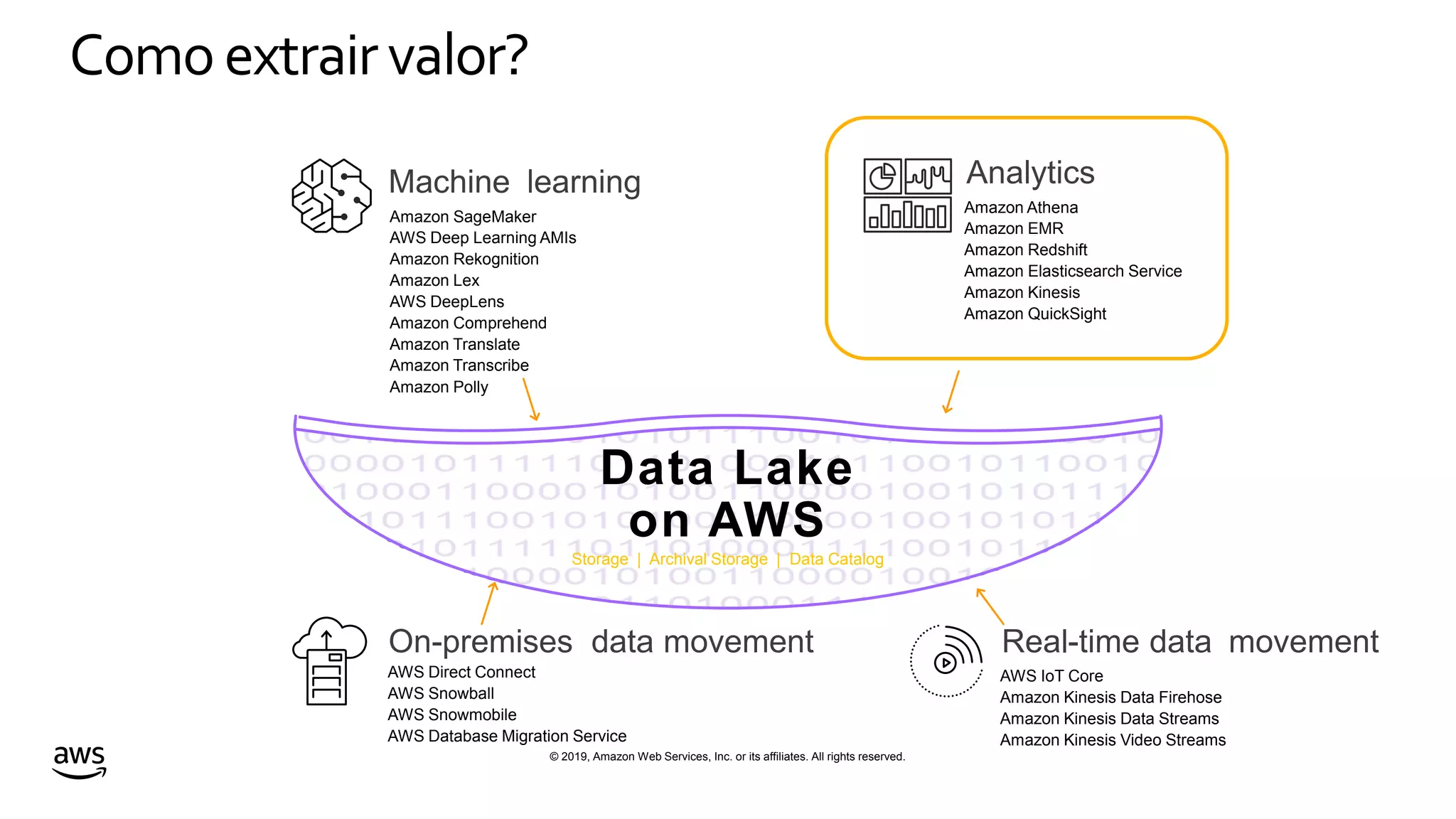



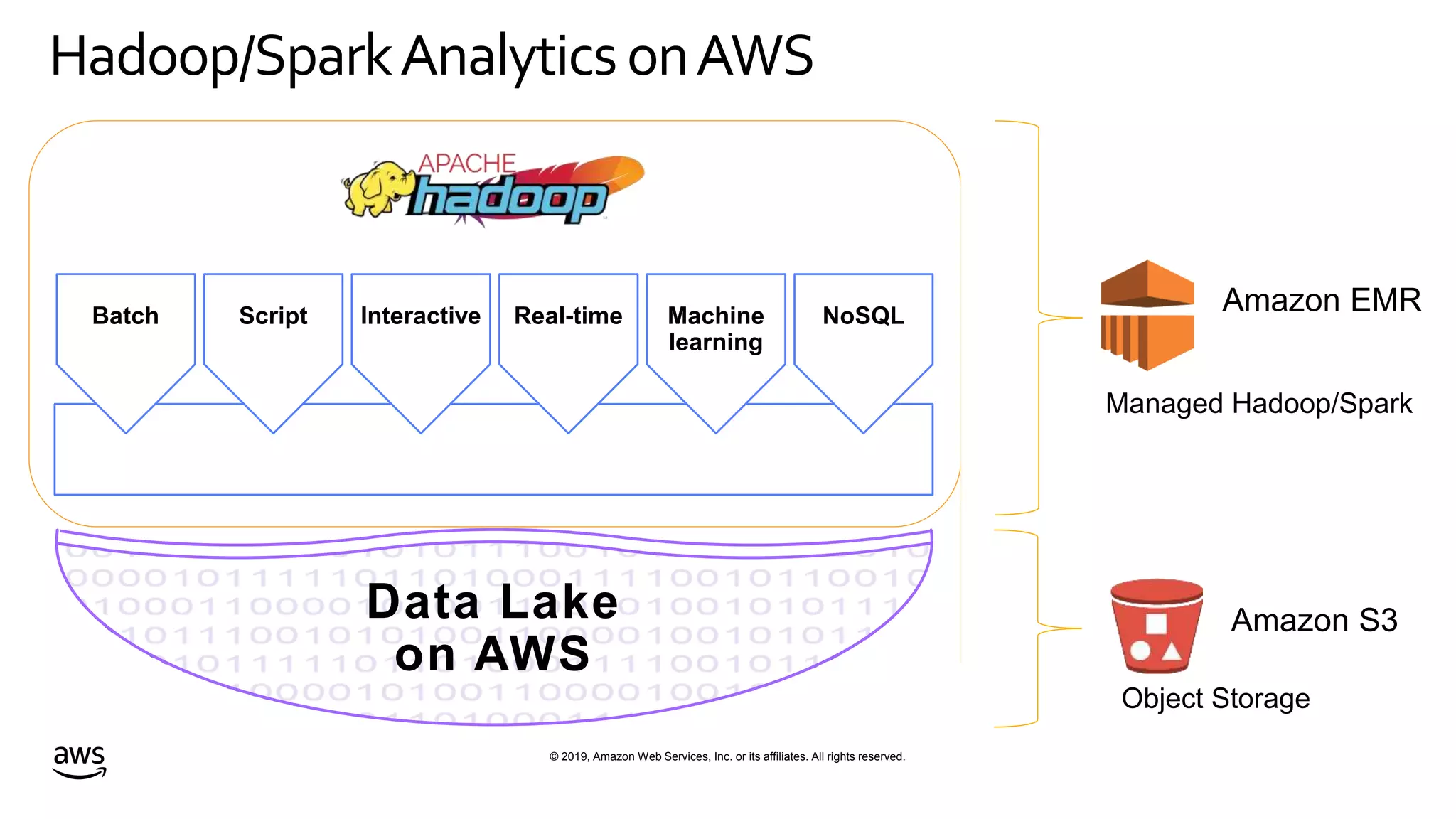
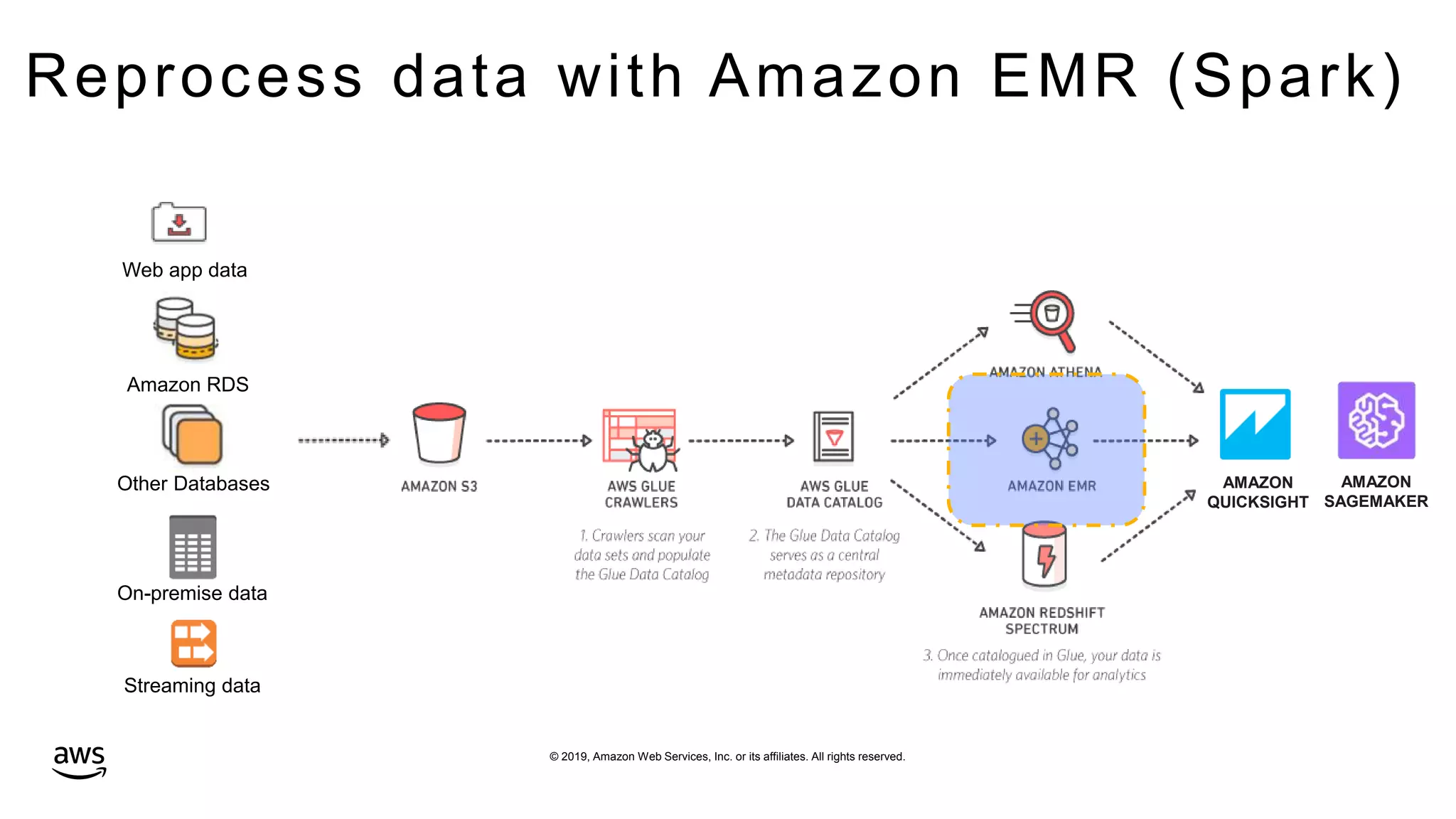

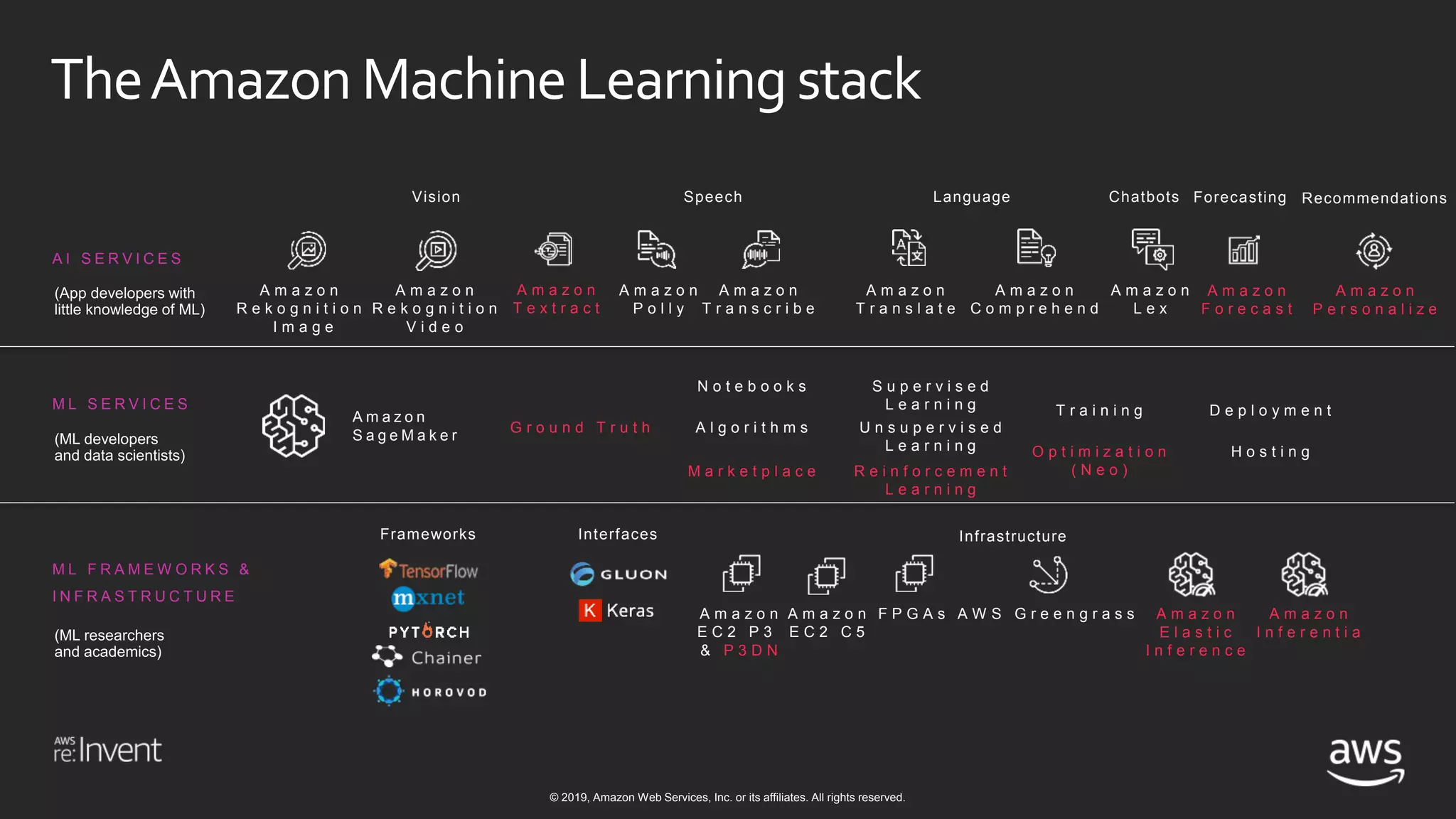
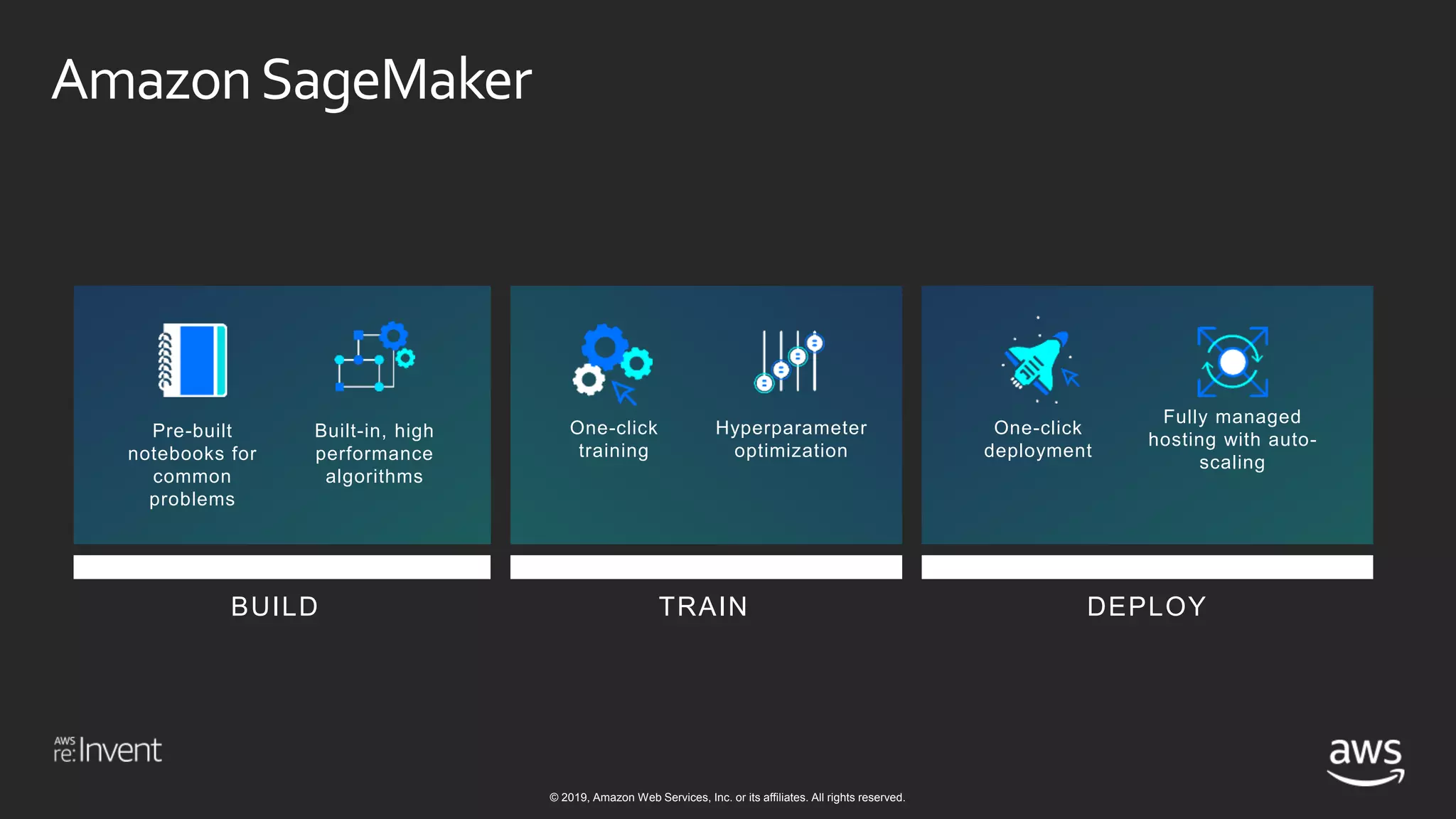






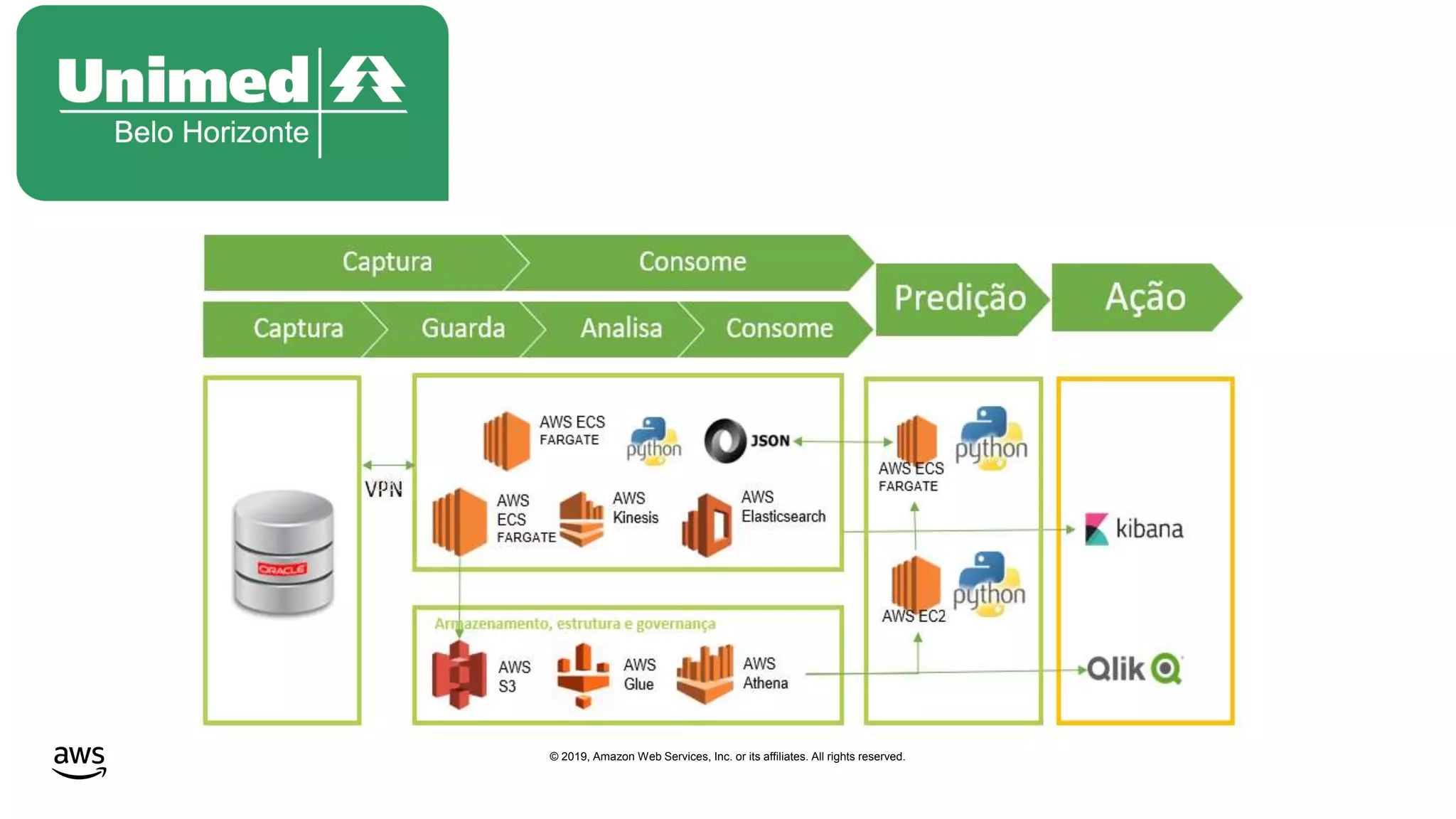





This document discusses building a data lake on AWS. It notes that organizations that successfully generate value from data will outperform competitors. It outlines challenges of data visibility, multiple access mechanisms, and analyzers needing access. AWS is presented as the perfect solution with its storage, analysis and security capabilities at scale. Case studies of Celgene and IEP are presented that used AWS for their data lakes. Traditional analytics are separated from data warehousing, but data lakes extend this by including diverse data and analytical engines at larger scale with lower costs. The AWS portfolio for data lakes, analytics and IoT is presented as the most complete toolset. Building value from the data lake is discussed through machine learning, analytics, data movement and visualization.

















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















