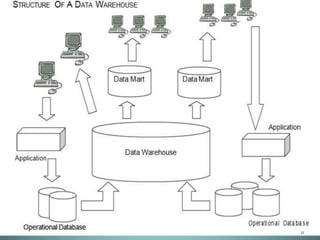
A data warehouse consists of several key components:
- Current detail data from operational systems of record which is stored for analysis.
- Integration and transformation programs that convert operational data into a common format for the data warehouse.
- Summarized and archived data used for reporting and analysis over time.
- Metadata that describes the structure and meaning of the data.
Data warehouses are used for standard reporting, queries on summarized data, and data mining of patterns in large datasets to gain business insights.