Downloaded 71 times

















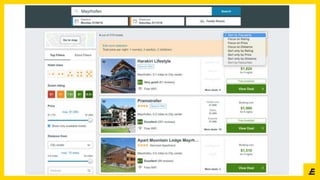





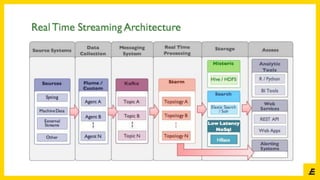



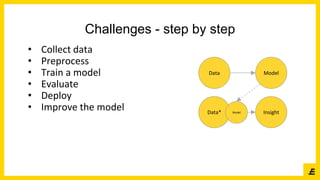







The document outlines the establishment of a Data Science Club aimed at fostering collaboration between academia and business, focusing on data, analytics, software engineering, and AI. It details the club's structure, goals, and planned activities, including expert talks and workshops on various data science topics throughout the academic year. Additionally, it highlights the roles of key team members and provides contact information for interested participants.









































































