Downloaded 11 times





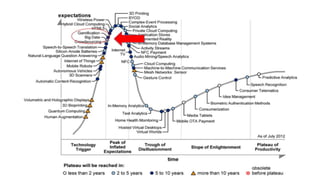
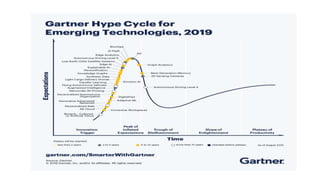
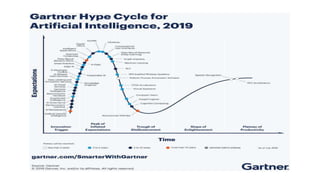
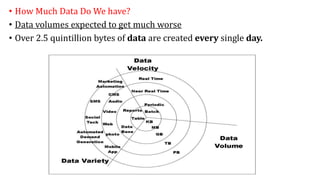
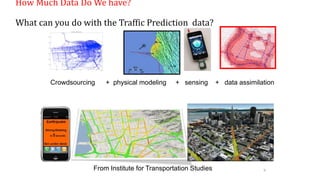

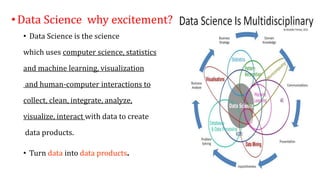


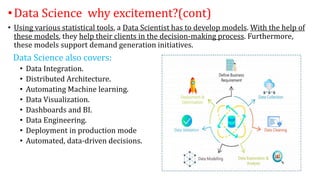






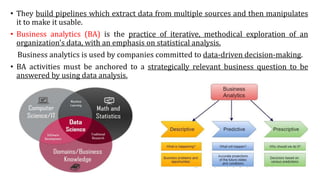

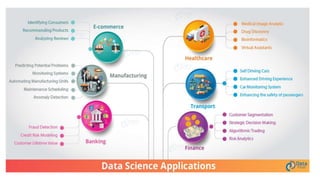
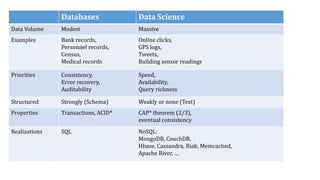
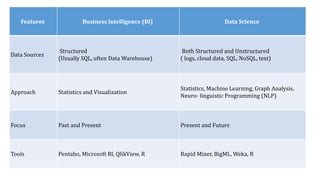
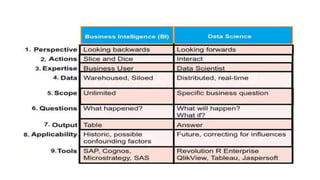
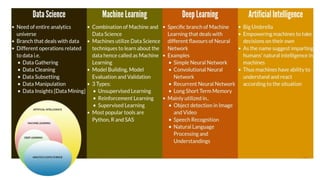



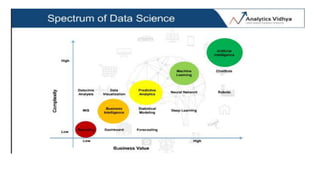
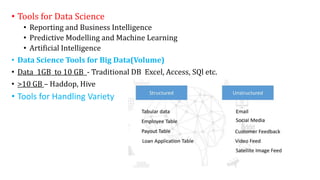


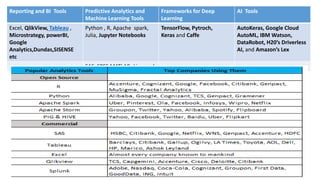
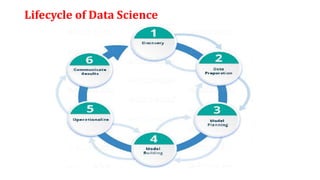




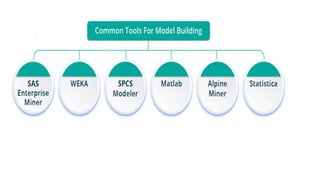







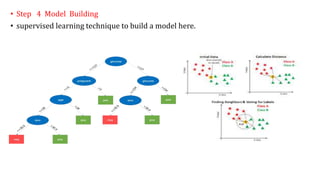
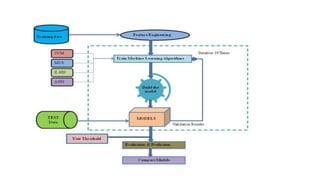


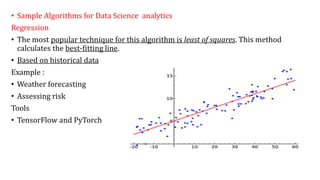
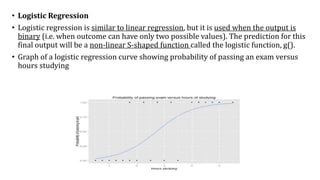


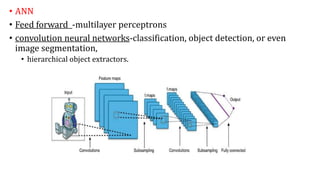

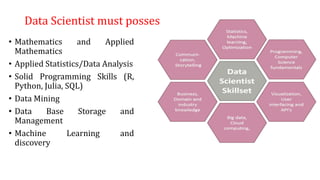

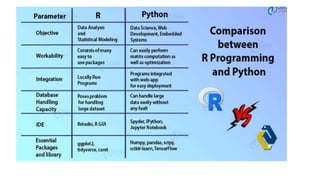
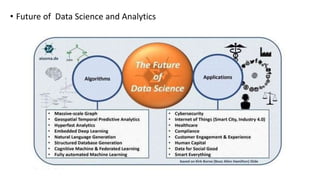

The document provides an extensive overview of data science and business analytics, detailing the evolution, applications, and interrelationships with areas like artificial intelligence and machine learning. It discusses the lifecycle of data science, tools, algorithms, and various case studies, emphasizing the significance of data in modern decision-making. Additionally, it highlights the multifaceted nature of data science as a blend of statistics, programming, and domain knowledge to extract valuable insights from large datasets.



































































