
Downloaded 17 times










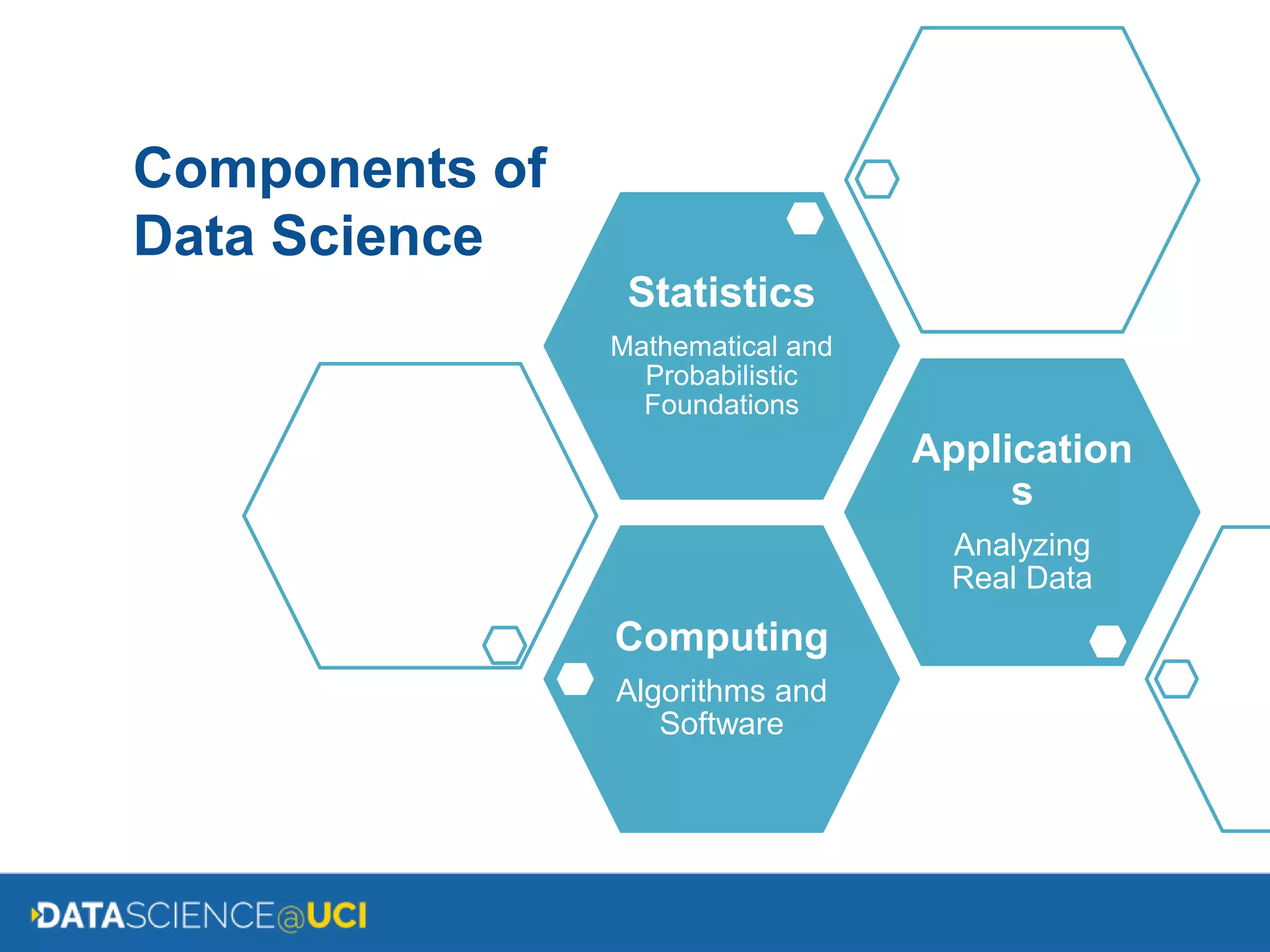








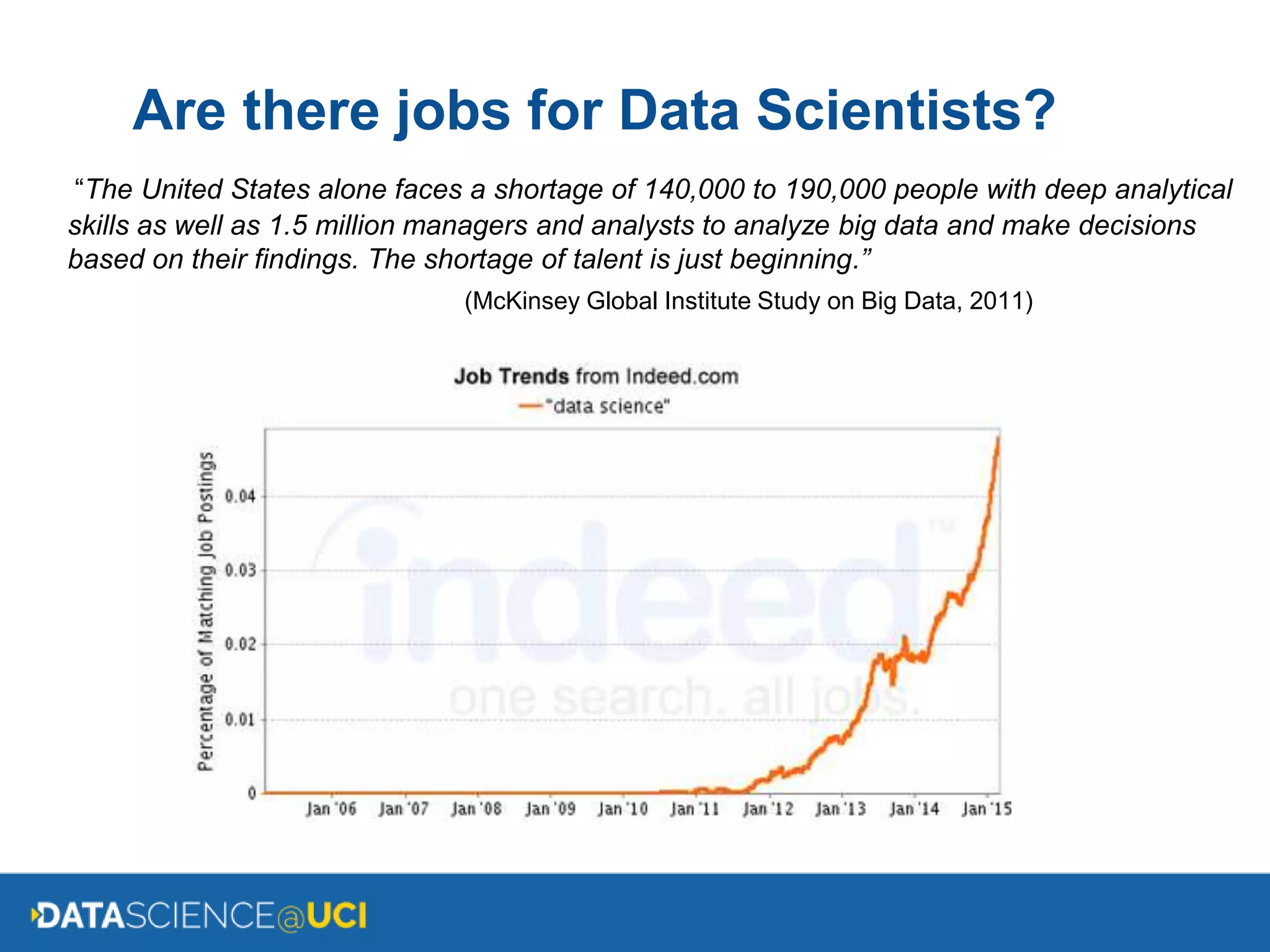





The document discusses the UCI Data Science major, detailing its applications in various fields such as web search, shopping, climate, medicine, physics, sports, and social media, emphasizing the essential skills in computing, mathematics, and statistics. It outlines the foundational courses, sample programs for the first four years, change of major requirements, potential career paths, and the job market for data scientists. It concludes with resources for further information about the major and application processes.



































































