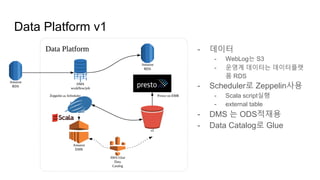
Data Platform v1
-데이터
- WebLog는 S3
- 운영계 데이터는 데이터플랫
폼 RDS
- Scheduler로 Zeppelin사용
- Scala script실행
- external table
- DMS 는 ODS적재용
- Data Catalog로 Glue
4.
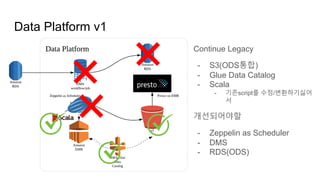
Data Platform v1
ContinueLegacy
- S3(ODS통합)
- Glue Data Catalog
- Scala
- 기존script를 수정/변환하기싫어
서
개선되어야할
- Zeppelin as Scheduler
- DMS
- RDS(ODS)
5.
- stability 안정성
-Data
- 재실행시에도 데이터 정합성보장
- HA
- scalability 확장성
- Data
- User(개발자, 사용자)
- operability 운영편의
- monitor/alert
- rerun/backfill
- realtime 실시간
- 실시간 요건
Data Platform v2 개발목표(Data Pipeline)
6.
Data Platform v2개발방향
- 처음은 zeppelin으로 되어있는 scheduler에 대한 개선
a. 별로 고민 없이 airflow(oozie, luigi, azkaban, nifi등)
- EMR 사용개선/운영부담
a. 기존에 EMR을 terminate없이 1년넘게 사용하고 있고 EMR에 문제시 대응에 대한 압박이 있음
b. batch job단위로 EMR 생성하고 종료시 terminate해서 EMR 운영에 대한 부담을 줄임
- ODS 적재프로세스 및 활용 개선
a. RDS로 적재해서 다른 mart와의 join이 어렵고 데이터 용량도 커져서 적재시간이나 테이블관리
에 어려움
b. S3로 적재 후 glue catalog를 통해 hive/spark에서 활용
- 개발방향은
1. Airflow 도입
2. ODS 적재 개선
3. Data-Pipeline 안정화
- Workflow manager+ scheduler
- 왜 Airflow인가?
- ETL아님! Bring Your Own ETL
- EMR, DMS, Glue,...
- python 기반
- DAG as a code
- google cloud composer
- DAG
- Directed Acyclic Graph – is a collection of all the tasks you want to run, organized in a way that reflects their
relationships and dependencies.
- operator
- An operator describes a single task in a workflow
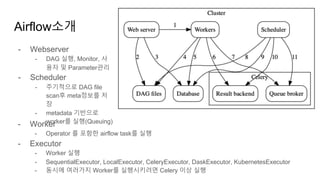
Airflow소개
9.
- Worker
- Operator를 포함한 airflow task를 실행
- Executor
- Worker 실행
- SequentialExecutor, LocalExecutor, CeleryExecutor, DaskExecutor, KubernetesExecutor
- 동시에 여러가지 Worker를 실행시키려면 Celery 이상 실행
- Webserver
- DAG 실행, Monitor, 사
용자 및 Parameter관리
- Scheduler
- 주기적으로 DAG file
scan후 meta정보를 저
장
- metadata 기반으로
worker를 실행(Queuing)
Airflow소개
Airflow 도입
- 기존batch 전환
- Livy
- zeppelin 에 scala spark 로 개발되어있어서, 최대한 재활용할 수 있도록
- scala 를 build안하고 사용가능
- 실제 Data 작업은 emr spark에서 이루어지는거라 build한거나 script나 별로 성능차이는
없다고 판단
- spark submit 에 옵션 대부분 사용가능
- scala, sql, r, pyspark
- Livy Operator 개발
- Spark Thrift server?
- EMR
- batch 단위마다 EMR을 띄우고 종료시에 EMR도 Terminate시킴
- EMR 생성,종료 함수 개발
- core, task 숫자 조절가능
- MASTER, CORE는 OnDemand, Task는 Spot Instance
13.
- 안정적인 airflow서버상태유지
- airflow 서버를 통한 데이터 전송 (ETL)은 금지!!
- DAG python은 단순하게. 분기문이나 복잡한 로직등은 배제
- 일자별data의 dependency가 있는 경우에는 DAG실행은 한번에 하나씩 날짜
순서대로
- depends_on_past : true
- max_active_runs = 1
- 시작날짜는 전날부터
- 'start_date': local_tz.convert(airflow.utils.dates.days_ago(2))
- UTC때문에 2일전으로 해야 전날배치부터 실행됨
- 특정일로 정하고 개발기간이 길어지게되면 production에 올릴때 날짜 수정해줘야함
- 날짜는 한국시간
- airflow화면에서 UTC로 나오기는 하는데, schedule은 한국시간으로 설정
- airflow에서 제공하는 date 변수 (ex) {ds}, {ds_nodash} ) 시간에서 UTC를 제공해서 한국시간으
로 하려면 자체적으로 변수생성
Airflow 개발
14.
- folder구조
- compile-less구조와 airflow서버에 부하를 덜 주기위한 목적으로
- folder는 DAG, library, script 의 세개로 나누어져있고
- DAG
- DAG를 구성
- script folder의 spark script를 livy/glue 등에 전달하는 역할
- library
- 공통함수, operator, sensor등
- script
- sql, scala, python script
- parameter화 되어있음
Airflow 개발
15.
Airflow 개발
- DAG간dependency
- task_sensor활용하고 DAG자체는 너무크지 않게 관리
- 기준일자?
- batch 실행이기때문에 기준날짜는 실행시간 전 schedule time
- 5 0 * * *
- 11/1일 에 실행되는 Job 의 경우 interval이 1day 이므로 10/31 00:05:00
- 0 2,4,10 * * *
- 11/1일 2시에 실행되는 Job의 경우 기준일시는?
16.
Airflow 운영안정성
- EMR이도중에 죽을경우를 대비해서 (Master, Core는 ondemand라서 죽을일
은 거의 없기는 하지만 AWS장애등 상황대비) , EMR 상태확인 및 재시작
- canary dag
- airflow 상태를 위한 task
- 한시간에 한번씩 task Schedule시간, 실행시간 비교
- 오래된 Task가 있는지 검사
- log retention
- log 는 S3 영구적으로 적재하고 , local log는 삭제하도록
- airflow에서 현재실행되는건 local log를 보고 이전log는 s3에서 가져옴
- https://github.com/teamclairvoyant/airflow-maintenance-dags/blob/master/log-cleanup/airflow-log-cleanup.py
- DMS문제점
- migration용이라서전체데이터만 가져옴
- 테이블이 커지면서 변경데이터만 가져오거나,
- 개인정보에 대해서 안가져오거나(이건됨), 변환해서 가져오고 싶을때
- mysql에 view같은걸 만들어서 처리할수도 있으나, 운영계에 권한이 없는경우도 많고
- 원하는 데이터만 가져오는데는 한계가 있음
- 검토
- lambda
- 데이터적재에는 부적합
- 시간제한 15분
- python Queue사용못함
- glue ELT Job(python)
- python 개발이 필요함
- glue python 에 기본적으로 설치된 connector가 별로 없고,
- 추가 package 설치도 안된다
ODS
19.
- 검토
- glueELT Job(spark)
- glue data catalog를 활용하면 script개발 용이
- glueContext 가 좋다고 하는데 sparkContext만큼 기능이 많지는 않다. 하지만 toDF() 를
통해 dataframe으로 바꿔서 이후작업하면됨
- repartition 및 다른 기능사용을 위해서 dataframe으로 변환해서 사용중
- spot instance를 사용한 EMR에 비해서 가격적인 이점 ?
- jar를 추가할수 있으나 EMR Bootstrap actions 처럼 script로 편하지는 않음
- glue instance 시작하는데 9~10분가량 걸림
- spark특성상 stream ETL이 안되고 데이터가 커도 가지고 있어야 하지만, 전체적제하는
테이블의 경우에는 size가 적고, 큰 테이블에 경우 변경적제해서 ETL 데이터 size가 크지
않음
- 개발환경 구성하기 까다로움.
- dev endpoints 랑 notebooks 를 만들어야함.
- dev endpoint는 계속띄어놓거나 개발할때마다 만들어야하는데 계속띄워 놓는것도
부담($)되고 개발할때마다 띄우는건 귀찮다
ODS
20.
Glue Jobs
- gluejob 시작이 delay 되는 log
- mart 관련 batch를 전환하는데는 아직 시기상조인듯 하나, ODS 적재에는 개발
이 편해서 Glue ETL(spark)사용
- glue ETL(python)이 좀 더 개선되면 ETL 목적으로 사용할수도 있을듯
21.
1. glue 적재준비(Jobs생성)
- Glue > ELT > Jobs 에서 add Job
- airflow에서 실행을 위한 job
- job name, Dependent jars path, Worker Type/capacity 항
목만 사용하고 script는 airflow에서 put 하므로 script 내용은
중요하지 않음
2. 개발
- Spark script
- Glue > ELT > Jobs 에서 add Job
- rds -> S3로 원하는 테이블은 연동하는 spark
script를 만듬
- toDF로 변환후 table insert, file write 등의 작업 수행
- 컬럼이 많은 경우 개발편하게 하려고 하는작업.
ODS(Glue spark job) 적재 개발
22.
ODS(Glue spark job)적재
2. 개발
- airflow
- glue job에서 만든 scala script를 s3에 put
- boto3 glue 활용해서 glue job 실행
- 실행되는 script는 airflow에서 put한 script
- 장점
- etl source 를 airflow repo에서 관리
- 날짜 변수등을 airflow에서 전달 가능
airflow 안정화 목표
-airflow 에 3개의 component에 대한 안정화
- webserver, scheduler, worker
- webserver
- down되어도 유실될 데이터는 없고, 빠른시간내에 재기동
- scheduler HA
- High Availability
- worker
- HA까지는 아니지만, 적당한 가용성과 작업을 처리할 수 있는 여러개의 worker가 필요
- source 배포
- git pull로 동기화하는걸 git에서 자동으로 동기화
25.
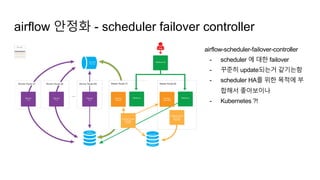
airflow 안정화 -scheduler failover controller
airflow-scheduler-failover-controller
- scheduler 에 대한 failover
- 꾸준히 update되는거 같기는함
- scheduler HA를 위한 목적에 부
합해서 좋아보이나
- Kubernetes ?!
26.
Feature apply(data pipeline입장)
Service discovery and load balancing 필수. airflow webserver
Automatic bin packing 기본기능
Storage orchestration 기본기능
Self-healing 필수! 이거때문에 도입
Automated rollouts and rollbacks 안씀. airflow image 배포가 자주있지 않음
Secret and configuration management 필수. Secret/ConfigMap활용
Batch execution 안씀. Batch는 Airflow로 하기때문에
Horizontal scaling
Airflow에는 적용하지 않았음. Worker 구조상 적용해볼
만함
- 컨테이너화된 애플리케이션을 자동으로 배포, 스케일링 및 관리해주는 오픈소
스 시스템
EKS, Kubernetes?
27.
EKS를 통한 airflow안정화 목표(구현)
- Webserver - LoadBalance
- Scheduler - HA, fault tolerant
- Worker - multiple worker, HA, fault tolerant
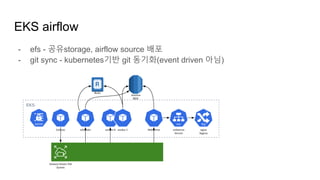
- airflow deployment using git sync
- pod hang걸릴경우에 대한 대비
- k8s deployments 에 livenessprobe
- webserver, scheduler에 대한 health check
- webserver : /health path에 httpGet으로 check
- scheduler : airflow metadb의 latest_heartbeat 시간과 현재 시간 차이 check
- airflow metadb check하는 부분을 python으로 실행(deployments yaml에 추가)
- EKS monitoring
- EKS 구성요소(pod, deployments 등) 에 대한 변화가 있을경우 slack
- https://github.com/bitnami-labs/kubewatch 를 쓰기는 했는데 설정적용이 안맞아서 다른 blog참조
(https://medium.com/@harsh.manvar111/kubernetes-event-notifications-1b2fb12a30ce)
airflow를 위한 EKS 설정/구성
31.
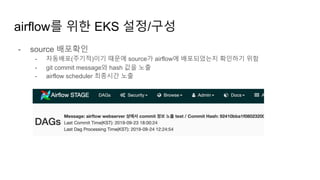
- source 배포확인
-자동배포(주기적)이기 때문에 source가 airflow에 배포되었는지 확인하기 위함
- git commit message와 hash 값을 노출
- airflow scheduler 최종시간 노출
airflow를 위한 EKS 설정/구성
32.
- DAG 간관계도
- DAG간에 dependency 관계를 diagram으로 표시
- 작업간에 관계파악, 재작업등에 용이
airflow를 위한 EKS 설정/구성
33.
더 생각해볼거
- 사용하는사람/팀이 많아지면 배포?
- Fork/PR
- Scale out worker
- Event(git change) based scheduler
34.
airflow 관련 site
-slack channel : apache-airflow.slack.com
- trouble shooting, Meetup
- lyft blog : https://eng.lyft.com/running-apache-airflow-at-lyft-6e53bb8fccff
- one of airflow committer : https://medium.com/@r39132/apache-airflow-grows-up-c820ee8a8324
































































![[NDC 2018] Spark, Flintrock, Airflow 로 구현하는 탄력적이고 유연한 데이터 분산처리 자동화 인프라 구축](https://cdn.slidesharecdn.com/ss_thumbnails/jparktemp-180424105624-thumbnail.jpg?width=640&height=640&fit=bounds)






![[MASOCON 2019] Serverless - Kimminjun](https://cdn.slidesharecdn.com/ss_thumbnails/masocon2019kimminjunserverless-191124110856-thumbnail.jpg?width=640&height=640&fit=bounds)



![[Open-infradays 2019 Korea] jabayo on Kubeflow](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradaysjabayoonkubeflowopen-190719080642-thumbnail.jpg?width=640&height=640&fit=bounds)


![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [If Lab] : 실시간 투표 커뮤니티 서비스 기반 데이터 파이프라인 구축 및 성능 검증](https://cdn.slidesharecdn.com/ss_thumbnails/2-1boaz23rdconferenceiflab-260203101556-e51663dd-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [F4] : 시켜줘, 금잔디 명예 플로리스트](https://cdn.slidesharecdn.com/ss_thumbnails/3-3boaz23rdconferencef4-260204011323-1cb48ec9-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [북적북적] : 데이터 기반 독립출판사,서점 경영지원 대시보드](https://cdn.slidesharecdn.com/ss_thumbnails/1-1boaz23rdconference-260203093712-78abc1a0-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [백 투 더 엔지] : 분산환경 주문 이벤트 처리 플랫폼](https://cdn.slidesharecdn.com/ss_thumbnails/1-2boaz23rdconference-260203100241-73ce0aa8-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [픽미] : 디저트 큐레이팅 플랫폼, 딸기로픽을 위한 데이터 기반 의사결정 프로세스 구축](https://cdn.slidesharecdn.com/ss_thumbnails/3-2boaz23rdconference-260203102931-15458767-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [셋이어때] : 헬퍼잇](https://cdn.slidesharecdn.com/ss_thumbnails/2-3boaz23rdconference-260203102432-6c8c7ed6-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [어벤정스] : ToonP](https://cdn.slidesharecdn.com/ss_thumbnails/2-2boaz23rdconference-260203102006-3a01358e-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [SimAI] : Omni_모든 콘텐츠 운영을 하나로](https://cdn.slidesharecdn.com/ss_thumbnails/1-4boaz23rdconferencesimai-260203101225-d673a594-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [OnLog]: Real-time Edge-to-Cloud Data Pipeline fo...](https://cdn.slidesharecdn.com/ss_thumbnails/3-4boaz23rdconferenceonlog-260204093729-11983ba7-thumbnail.jpg?width=640&height=640&fit=bounds)
![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [JJAI] : Re:Buy - 고객 행동 패턴 기반 재구매 시점 예측 개인화 CRM 시스템](https://cdn.slidesharecdn.com/ss_thumbnails/1-3boaz23rdconferencejjai-260203100705-ab1ce027-thumbnail.jpg?width=640&height=640&fit=bounds)