요약
● Isolation을 가능하게하는 기술
○ Linux Namespace : files, processes, network interfaces 등 같은 namespace에 있는 리소스만 접근 가능한
Personal View를 제공
○ Linux Control Group(cgroup) : process가 사용할 수 있는 리소스양의 제한을 컨트롤
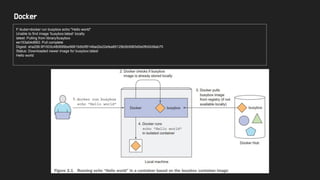
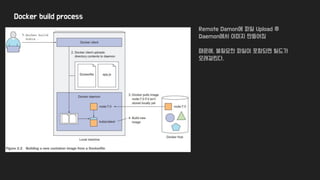
● Docker container
○ Docker is a platform for packaging, distributing and running applications
■ allows you to package your application along with the whole environment
○ 3가지 주요 Concepts
■ Images
● application + environment + filesystem
● Layer 구조로 되어 있음
■ Registries (public/private)
● repository for Docker images
■ Containers
● regular Linux container from Docker-based container image.
VM vs Containers
●6개의 App을 VM에서 돌릴때와 Container에서 돌릴때이 차이점
● AppA 와 AppB가 같은 Filesystem 공유가 어떻게 가능한가?
(Container는 독립된 Filesystem을 갖는게 아닌가?)
○ Docker Image는 Layer구조로 되어 있음
○ 따라서, 서로다른 Image라도 같은 Parent Image를 가질 수 있음
○ Distribution & Storage Footprint를 절약해줌
○ 특정 App에서 해당 filesystem에 write할때는 이야기가 달라짐
○ App A가 변경한 파일 내용을 App B에 영향을 받지 않아야 함
■ 공유하는 File 대해 변경 발생 시 해당 파일의 copy본이 최상위
layer에 생성되고 그 파일에 변경을 저장함
■
6.
Kubernetes
● Kubernetes isa software that allows you to easily deploy and manage containerized applications on top of
it
● Kubernetes를 사용한다면,
○ 2-3개 node 규모의 클러스터에 Application을 배포하는것과 1,000개 규모의 클러스터에 배포하는것은 동일하다.
● Google Borg에서 시작(이후 Omega로 이름 변경) → 2003년도, 수십만 Node를 효율적으로 관리하기 위해서 만들어짐
● 2014년도 오픈소스화
7.
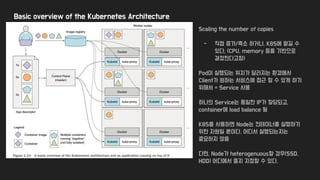
Basic overview ofthe Kubernetes Architecture
Scaling the number of copies
- 직접 증가/축소 하거나, K8S에 맡길 수
있다. (CPU, memory 등을 기반으로
결정한다고함)
Pod이 실행되는 위치가 달라지는 환경에서
Client가 원하는 서비스에 접근 할 수 있게 하기
위해서 = Service 사용
하나의 Service는 동일한 IP가 할당되고,
container에 load balance 됨
K8S를 사용하면 Node는 컨테이너를 실행하기
위한 자원일 뿐이다, 어디서 실행되는지는
중요하지 않음
다만, Node가 heterogenuous할 경우(SSD,
HDD) 어디에서 뜰지 지정할 수 있다.
내부 Components
● Pods
○K8S에서는 개개 Container를 다루지 않고 Container group 개념인 POD 단위로 관리한다
■ Pod 내 정의된 container는 항상 같은 node에서 실행된다
■ 같은 Node 내 같은 Linux Namespace를 공유한다.
● ip, hostname, volume, process, ip, user 등이 공유됨
● ReplicationController
○ Pod를 실제로 생성하고 지정된 갯수만큼의 Instance가 실행되도록 컨트롤 하는 역할을 담당
○ kubectl run 커맨드 실행 시 내부적으로는 ReplicationController가 생성됨
Introduction
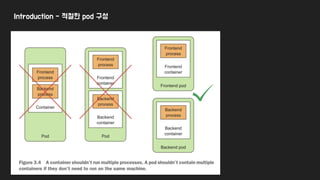
● Pods
○ k8s에서기본 Building block → 배포의 단위 → pod에 포함된 container은 모두 같은 node에서 실행된다.
○ 반드시 여러개의 container를 pod에 포함해야 할 필요는 없다
● 이런 아키텍처 설계 이유( instead of one container with multiple processes)
○ container is designed to run only a single process per container(child process 제외)
○ 만약 하나의 컨테이너에 여러 프로세스를 돌린다면,
■ 프로세스가 항상 실행되게 유지하거나, 로그관리등을 우리가 신경써야 한다.
● Pods 이해하기
○ pod안의 컨테이너들은 partial isolated 되어 있다.
○ k8s는 pods 안의 container들간의 같은 namespace를 공유하여 이 문제를 해결한다.
■ network, uts, ipc namespace 공유 → port conflict..
■ filesystem 격리됨
■ volume를 통해 filesystem을 공유할 수 있음
14.
Introduction
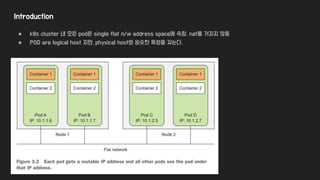
● k8s cluster내 모든 pod은 single flat n/w address space에 속함. nat를 거치지 않음
● POD are logical host 지만, physical host와 비슷한 특성을 갖는다.
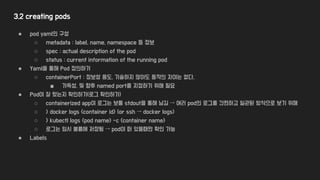
3.2 creating pods
●pod yaml의 구성
○ metadata : label, name, namespace 등 정보
○ spec : actual description of the pod
○ status : current information of the running pod
● Yaml을 통해 Pod 정의하기
○ containerPort : 정보성 용도, 기술하지 않아도 동작의 차이는 없다.
■ 가독성, 및 향후 named port를 지정하기 위해 필요
● Pod이 잘 떴는지 확인하기(로그 확인하기)
○ containerized app이 로그는 보통 stdout을 통해 남김 → 여러 pod의 로그를 간편하고 일관된 방식으로 보기 위해
○ > docker logs <container id> (or ssh → docker logs)
○ > kubectl logs <pod name> -c <container name>
○ 로그는 임시 볼륨에 저장됨 → pod이 떠 있을때만 확인 가능
● Labels
17.
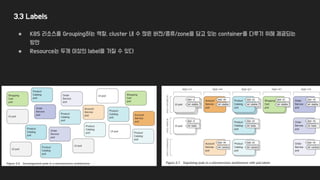
3.3 Labels
● K8S리소스를 Grouping하는 역할. cluster 내 수 많은 버전/종류/zone을 담고 있는 container를 다루기 위해 제공되는
방안
● Resource는 두개 이상의 label을 가질 수 있다
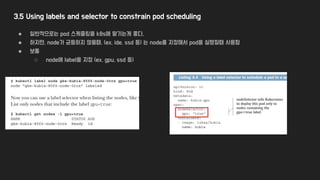
3.5 Using labelsand selector to constrain pod scheduling
● 일반적으로는 pod 스케쥴링을 k8s에 맡기는게 좋다.
● 하지만, node가 균등하지 않을때, (ex, ide, ssd 등) 는 node를 지정해서 pod을 실행할때 사용함
● 보통
○ node에 label을 지정 (ex, gpu, ssd 등)
20.
3.6 Annotating pods
●label과 형식은 동일
● 하지만, annotation selector 같은건 없다.
● 그럼 어떤 용도?
○ 내부적으로 사용하는 정보를 저장하는 용도
■ ex) pod을 생성한 사용자 이름
○ 더 큰 데이터를 담을 수 있다.(256KB in total)
○ new feature of api
■ annotation 으로 beta 기능 개발 후 확정되면 field로 정의됨
21.
3.7 Namespace
● Namepsace
○label selector과는 다른 관점의 관리 group
○ namespace 가 다르면 name이 중복 될 수 있다
○ 예외
■ node
○ Namespace의 isolation은 resource정의/관리의 isolation은 해주지만,실행환경의 isolation은 해주지 않는다.
■ namespace a 의 node a에서 namespace b의 node b 로의 socket 통신은 가능하다.
● Pod 종료
○ > kubectl delete pod <pod name>
○ 내부적으로
■ SIGTERM → 30초 대기 → SIGKILL
○ app이 gracefully shot down 하기 위해서는 SIGTERM을 처리해야 한다.
4.1 Keeping podshealthy - Liveness
● ReplicationController에 의해 process가 crash되면 해당 pod은 종료되고 새로운 pod이 자동 재시작된다.
● Process는 멀쩡한데 어플리케이션 동작에 이상이 있을 경우도 대비해야 한다.
○ Ex) OOM, Deadlock
○ → App 내부가 아닌 외부에서 판단하는게 coverage를 높일 수 있다.
● Liveness
○ 종류 : http get, tcp socket, exec
○ Additional Property
■ delay, timeout, period, success, failure
○ Liveness 개발 시 주의할 점
■ Container 내부 문제에 대해서만 failure를 리턴하라
● DB와 같은 외부 시스템 장애일 경우 → Front-end container를 재시작해도 문제가 해결되지 않을 수
있다.
■ 가볍게 작성해라.
■ prove 내부에서 retry를 할 필요가 없다. → failure 설정을 이용하자
24.
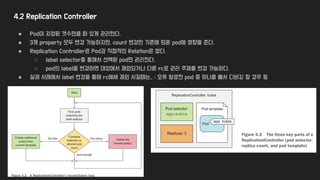
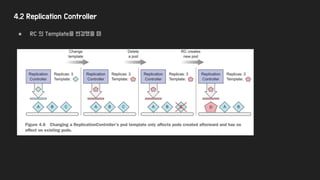
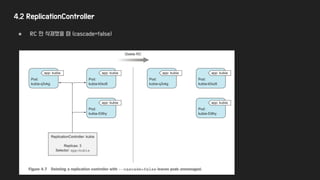
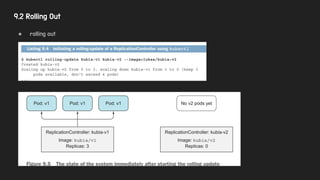
4.2 Replication Controller
●Pod이 지정된 갯수만큼 떠 있게 관리한다.
● 3개 property 모두 변경 가능하지만, count 변경만 기존에 띄운 pod에 영향을 준다.
● Replication Controller은 Pod과 직접적인 Relation은 없다.
○ label selector을 통해서 선택된 pod만 관리한다.
○ pod의 label을 변경하면 대상에서 제외되거나 다른 rc로 관리 주체를 변경 가능하다.
● 실제 사례에서 label 변경을 통해 rc에세 제외 시킬때는.. : 오류 발생한 pod 중 하나를 빼서 디버깅 할 경우 등
4.3 ReplicaSets
● ReplicationController이후 소개된 Resource. (ReplicationController의 Alternative)
● ReplicaSets을 써라!!
● ReplicationController와의 차이점(개선점)
○ set based selector 지원
■ env=production & env=dev (ReplicaSets 가능, ReplicationController 불가능)
○ ?? 단지 이 차이라면, replicationcontroller의 selector만 개선하면 되는것 아닌가?
28.
4.4 DaemonSets
● Cluster내 모든 Node에 하나의 Pod이 실행되도록 한다.
○ Infra level pod를 배포할때 사용함
● NodeSelector를 통해 Pod이 실행될 Node를 지정할 수도 있다
29.
4.5 Batch 성job (single completable task)을 위한 pod 실행하기
● Job 의 property
○ restartPolicy : default가 Always가 아니다.
○ completions, parallelism 을 통해 병렬성을 지정 가능하다.
○ activeDeadlineSeconds : pod 이 완료될때까지 최대 대기시간
관련 링크
● Service외부에 오픈하기 : https://kubernetes.io/docs/concepts/services-networking/service/#publishing-services-service-types
32.
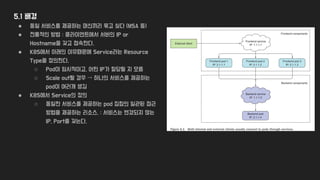
5.1 배경
● 동일서비스를 제공하는 머신끼리 묶고 싶다 (MSA 등)
● 전통적인 방법 : 클라이언트에서 서버의 IP or
Hostname을 갖고 접속한다.
● K8S에서 아래의 이유때문에 Service라는 Resource
Type을 정의한다.
○ Pod이 임시적이고, 어떤 IP가 할당될 지 모름
○ Scale out될 경우 → 하나의 서비스를 제공하는
pod이 여러개 생김
● K8S에서 Service의 정의
○ 동일한 서비스를 제공하는 pod 집합의 일관된 접근
방법을 제공하는 리소스. : 서비스는 변경되지 않는
IP, Port를 갖는다.
33.
5.1 서비스는 어떻게정의하나?
● ReplicationController와 동일한 방법 (Label Selector). (default type : ClusterIP)
● 실습 : 서비스에서 생성된 ip로 접근해보기
○ > kubectl exec [pod_id] -- curl -s http://[service ip]
○ 여기서 ‘--’ 는 kubectl 명령어의 끝을 명시적으로 표시한다. 이게 없으면 뒷 부분 -s를 옵션으로 인식 한다.
34.
5.1 추가 개념들
●sessionAffinity : load balance 정책
○ 두 가지 방법 제공 : None, ClientIP (TCP/IP level)
● single service with more than two port
● namedPort를 사용하여 하드코딩을 제거할 수 있다.(DRY).
●
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
ports:
- name: http
port: 80
targetPort: 8080
- name: https
port: 443
targetPort: 8443
selector:
app: kubia
35.
5.1 서비스 Discovery
●기본적으로 환경 변수를 통해 Discovery함
● K8S 내부 DNS를 이용할 수도 있음
○ kube-system namespace 내 kube-dns Pod
○ Pod 내의 dnsPolicy 프로퍼티로 설정 가능
● Domain 규칙
○ [service명].[namespace].[cluster domain(configurable)]
○ Ex), kubia.default.svc.cluster.local
36.
5.2 외부 Cluster서비스 연결하기
● Endpoint를 이용 (** Endpoint는 Service에 종속된 프로퍼티가 아닌, 독립된 리소스!!)
● service endpoint 정의 방법
○ Label selector → 자동으로 정의됨
○ Manual Define (with service without a selector)
● Endpoint정의 방식의 변경으로 pod의 실행 cluster변경을 반영할 수 있다.
● ExterName type의 Service를 통해서 연결도 가능 ⇒ 외부 연결 서비스를 추상화 할 수 있다.
apiVersion: v1
kind: Service
metadata:
name: external-service
spec:
ports:
- port: 80
kind: Endpoints
metadata:
name: external-service
subsets:
- addresses:
- ip: 11.11.11.11
- ip: 22.22.22.22
ports:
- port: 80
apiVersion: v1
kind: Service
metadata:
name: external-service
spec:
type: ExternalName
externalName:
api.somecompany.com
ports:
- port: 80
37.
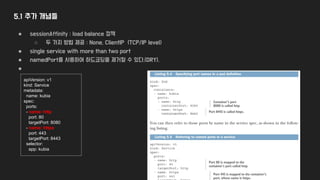
5.3 외부 Client에게서비스 노출하기 - Node Port
● 모든 node에 지정된 port를 할당하고, 서비스에 요청이 올 경우 pod이 배포된 node로 요청을 보낸다.
● ClusterIP type가 비슷하지만, Node IP로 접근할 수 있다는점이 다르다
● LB가 없는 환경에서 H/A LB 를 위해 사용된다.
38.
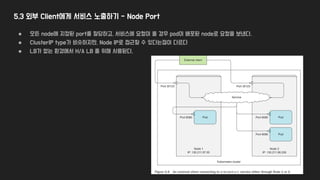
5.3 외부 Client에게서비스 노출하기 - Load Balancer
● Loadbalancer를 이용해 service를 expose한다.
● 만약 LoadBalancer가 없다면, NodePort를 이용해 동작한다. → LoadBalancer는 NodePort의 확장이다.
● 아래와 같이 서비스를 실행하면,
○ LB가 IP를 획득하여 서비스에 바인딩 해줌
39.
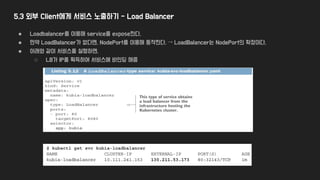
5.3 외부 Client에게서비스 노출하기 - Load Balancer
● LB <-> k8S Cluster 간 설정은 어떻게
진행될까?
● externalTrafficPolicy: Local
→ Network Hop을 줄이고, source ip가
유지되는 장점이 있으나,
→ 해당 local node에 pod이 죽었다면 hang
걸리고, lb가 균등하게 되지 않는 단점이 있다.
● 그럼 source IP를 유지하는 방법은??
40.
5.4 외부 Client에게서비스 노출하기 - Ingress
● Ingress가 왜 필요할까? (LB, NodeIP가 있는데,,)
○ Ingress는 하나의 공인 IP로 설정이 가능하다.
○ HTTP Layer control이 가능하다.
● K8S Cluster 환경에서 Ingress를 제공해야 한다. (→ Implementation specific 한 부분이 많음)
○ minkube 환경에서 enable 시키는 방법(책 참고)
● Ingress가 제공되는 환경에서 아래와 같이 Ingress 리소스를 정의한다.
○ host, path 모두 arrary로 정의 가능하다
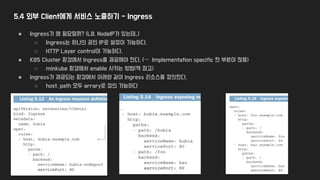
41.
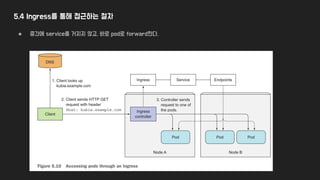
5.4 Ingress를 통해접근하는 절차
● 중간에 service를 거치지 않고, 바로 pod로 forward한다.
42.
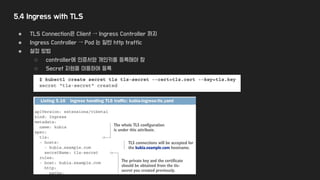
5.4 Ingress withTLS
● TLS Connection은 Client → Ingress Controller 까지
● Ingress Controller → Pod 는 일반 http traffic
● 설정 방법
○ controller에 인증서와 개인키를 등록해야 함
○ Secret 자원을 이용하여 등록
43.
5.5 Signaling whena pod is ready to accept connections
● Service에서 label selector를 통해 Pod을 지정할 경우 Pod이 생성되자마자 요청이 해당 Pod으로 Redirect됨
→ 아직 초기화 과정이 안끝나 요청을 처리할 준비가 되지 않은 Pod일지라도
● Readiness Prove
○ Pod의 속성
○ Liveness Prove와 비슷
■ 주기적으로 호출됨(default 10초)
■ Readiness의 판단은 앱 개발자의 역할
■ 3가지 종류 존재
● Exec
● Http get
● Tcp socket
○ Liveness Prove와의 차이점
■ fail된 pod를 죽이지 않고 Service Endpoint 에서만 제거한다
○ Pod 시작 시 와 서비스중 특정 container에서 db와의 연결이 끊겼을때 와 같은 문제를 피하게 해준다.
44.
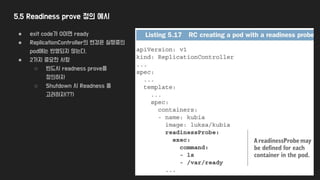
5.5 Readiness prove정의 예시
● exit code가 0이면 ready
● ReplicationController의 변경은 실행중인
pod에는 반영되지 않는다.
● 2가지 중요한 사항
○ 반드시 readness prove를
정의하자
○ Shutdown 시 Readness 를
고려하자(??)
45.
5.6 Using aheadless service for discovering individual pods
● Client가 Service안에 정의된 모든 Pod과 커넥션을 맺어야 할경우?
● Headless service 이용 : Service spec의 clusterIP 를 None로 세팅
● DNS lookup 시 모든 pod의 ip 리턴
● 일반적인 Client한테는 동일하게 동작함
○ DNS 를 통해 접근
○ 단, LB 방식이 다름(DNS Round robin)
46.
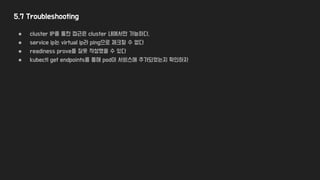
5.7 Troubleshooting
● clusterIP를 통한 접근은 cluster 내에서만 가능하다.
● service ip는 virtual ip라 ping으로 체크할 수 없다
● readiness prove를 잘못 작성했을 수 있다
● kubectl get endpoints를 통해 pod이 서비스에 추가되었는지 확인하자
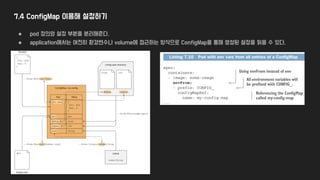
6.1 Volume 개요
●Pod내 container끼리 storage를 공유하거나 외부 storage에 저장하는 방법
● 기본적으로 pod 내 container는 디스크를 공유하지 않음 (고유의 분리된 filesystem을 이용)
● container와 filesystem의 lifecycle이 동일하기 때문에 container가 죽으면 data도 소멸
● volume은 pod과 lifecycle이 동일
49.
Kubernetes 내 Volume의종류 (공식가이드 링크)
이름 설명
Normal Volume pod 삭제시 지워짐 : emptyDir, gitRepo
Persistent
Storage(내부)
hostPath : Node의 Filesystem 접근을 위해 사용 (Ex, DaemonSet 에서 fs를 통해 h/w 접근)
Pod이 삭제되더라도 유지됨. 단, db용도로 만들어진건 아님.
local : 미리 생성되어 있어야 함. Dynamic provisioning은 지원하지 않음(v 1.14부터)
Persistent Storage
(Provided)
gcePersistentDisk : persistence disk를 만들고, container의 spec의 Volume에 해당 storage를 기술해준다.
Pod이 죽었다 살아도 기존에 write한 file이 유지된다.
다음 것들도 비슷(cephfs, awsElasticBlockStore, nfs, iscsi, GlusterFS, cephfs등등)
문제는 : 기술들을 알고 설정해야 하고, POD 정의 부가 특정 기술에 종속적이게됨
50.
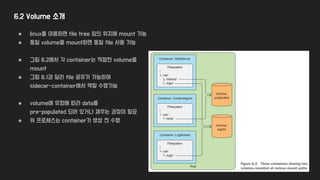
6.2 Volume 소개
●volume은 독립적인 k8s object가 아니기에 스스로 생성, 삭제가 불가능 (pod에 종속적)
● 모든 container에서 volume사용이 가능 (각 container에서 mount 필요)
● 그림 6.1에서 각 container는 volume없이
각자의 filesystem을 이용
● container 간의 storage 공유가 없음
● WebServer에서 log를 기록하더라도
LogRotator에서 log를 읽지 못해 rotating 불가
51.
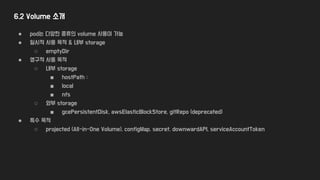
6.2 Volume 소개
●linux를 이용하면 file tree 임의 위치에 mount 가능
● 동일 volume을 mount하면 동일 file 사용 가능
● 그림 6.2에서 각 container는 적절한 volume을
mount
● 그림 6.1과 달리 file 공유가 가능하여
sidecar-container에서 역할 수행가능
● volume에 유형에 따라 data를
pre-populated 되어 있거나 채우는 과정이 필요
● 위 프로세스는 container가 생성 전 수행
52.
6.2 Volume 소개
●pod는 다양한 종류의 volume 사용이 가능
● 일시적 사용 목적 & 내부 storage
○ emptyDir
● 영구적 사용 목적
○ 내부 storage
■ hostPath :
■ local
■ nfs
○ 와부 storage
■ gcePersistentDisk, awsElasticBlockStore, gitRepo (deprecated)
● 특수 목적
○ projected (All-in-One Volume), configMap, secret, downwardAPI, serviceAccountToken
53.
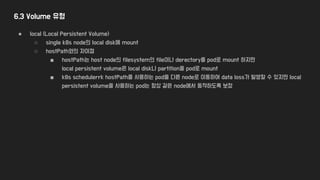
6.3 Volume 유형
●emptyDir
○ 이름 그대로 빈 directory로 생성
○ pod와 lifecycle이 같아 pod 삭제 시 data도 소멸
○ 사용 용도
■ scratch space
■ crash recovery를 위한 checkpoint 계산용
■ 두 container 간 file 송수신용
○ storage 종류 (hdd, ssd, nas) 와 상관없이 사용 가능
○ k8s에서는 “Memory” medium으로 사용하는 것을 권장 (가장 빠르고 쉽게 초기화가 가능)
54.
6.3 Volume 유형
●gitRepo (deprecated)
○ emptyDir에 git repository 를 clone하여 생성
○ pod가 생성될 때 특정 revision을 check out
○ git에 반영되는 최신버전의 file과 동기화 되지 않음
■ pod를 재생성하거나 sidecar container를 이용하여 ‘git sync’ 필요
55.
6.3 Volume 유형
●hostPath
○ host node의 file system에 있는 특정 file 또는 directory를 mount
○ pod가 삭제되도 data는 보존
○ 특정 node의 file system에만 data가 저장되므로 database에 부적합
○ 사용 용도
■ 운영중인 container에서 Docker 내부에 접근이 필요한 경우
■ 운영중인 container에서 cAdvisor(container advisor)를 사용하는 경우
■ allowing a Pod to specify whether a given hostPath should exist prior to the Pod running,
whether it should be created, and what it should exist as (해석이 어려움...)
○ 주의 사항
■ podTemplate으로 만들어진것처럼 동일한 설정의 pod라도 다른 node에서는 같은 path라도 다른 file일 수
있기 때문에 다르게 행동할 수 있음
■ resource-aware scheduling 추가 시 resource 증명이 안될수도 있음
■ root 권한으로만 host에 file이나 directory생성이 가능
● root권한으로 실행한 process이거나 hostPath의 권한 수정이 필요
56.
6.3 Volume 유형
●local (Local Persistent Volume)
○ single k8s node의 local disk에 mount
○ hostPath와의 차이점
■ hostPath는 host node의 filesystem의 file이나 derectory를 pod로 mount 하지만
local persistent volume은 local disk나 partition을 pod로 mount
■ k8s schedulerrk hostPath를 사용하는 pod을 다른 node로 이동하여 data loss가 발생할 수 있지만 local
persistent volume을 사용하는 pod는 항상 같은 node에서 동작하도록 보장
57.
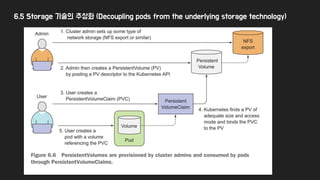
6.5 Storage 기술의추상화 (Decoupling pods from the underlying storage technology)
58.
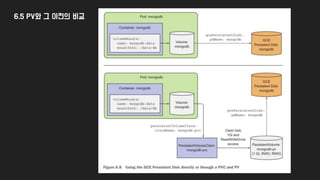
6.5 PV와 그이전의 비교
구현 Specific한 설정 Pod에 직접 정의되는
방식에서
→ 별도 설정으로 빠지고 Pod에서는
Reference하는
방식으로 바뀜
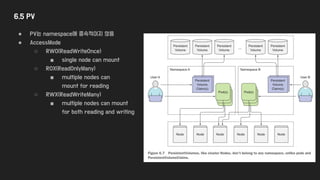
6.5 PV
● PV는namespace에 종속적이지 않음
● AccessMode
○ RWO(ReadWriteOnce)
■ single node can mount
○ ROX(ReadOnlyMany)
■ multiple nodes can
mount for reading
○ RWX(ReadWriteMany)
■ multiple nodes can mount
for both reading and writing
61.
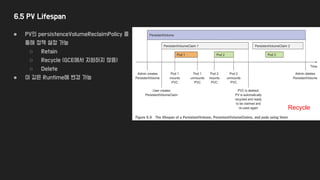
6.5 PV Lifespan
●PV의 persistenceVolumeReclaimPolicy 를
통해 정책 설정 가능
○ Retain
○ Recycle (GCE에서 지원하지 않음)
○ Delete
● 이 값은 Runtime에 변경 가능
Recycle
62.
6.6 Dynamic Provisioningof PV
● PV, PVC를 통해 technology 추상화는 되었지만, 관리자의 pv Provision 작업은 여전히 필요함
● K8S는 Dynamic Provision을 통해 이 과정을 자동화 할수 있음
● Admin이
○ 기존에는 PV를 만들었지만,
○ Dynamic Provisioning에서는 Persistent Volume provisioner를 deploy하고 여러개의 StorageClass를 정의함
● 사용자는
○ 자신이 필요한 StorageClass를 pvc의 정의부분에 Ref함
● StorageClass
○ namespaced 되지 않음
○ 이름으로 reference되기 때문에 다른 k8s cluster에 배포될때 yml을 변경없이 유지될 수 있음
■ Ex) fast, standard 등
○ StorageClass 없이 PVC 정의할때는 default StorageClass provision되어 할당됨
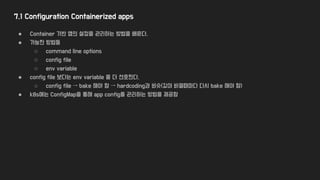
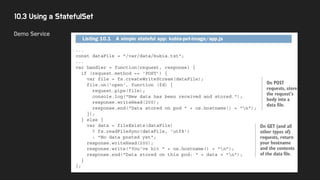
7.1 Configuration Containerizedapps
● Container 기반 앱의 설정을 관리하는 방법을 배운다.
● 가능한 방법들
○ command line options
○ config file
○ env variable
● config file 보다는 env variable 을 더 선호한다.
○ config file → bake 해야 함 → hardcoding과 비슷(값이 바뀔때마다 다시 bake 해야 함)
● k8s에는 ConfigMap을 통해 app config를 관리하는 방법을 제공함
65.
7.2 Command linearg 를 컨테이너에 전달하기
● Docker image에 cmd arg 정의하기
○ 두 가지 방법 존재
■ shell form : >ENTRYPOINT node app.js
● invoked inside a shell
■ exec form : ENTRYPOINT ["node", "app.js"].
● Directly invoked
○ shell process는 불필요함 → 대부분 exec 형식을 쓴다.
이슈사항?
●
● Headless Service를Cluster 외부에서 어떻게 접근하나?
○ https://tothepoint.group/blog/accessing-kafka-on-google-kubernetes-engine-from-the-outside-world/
○ https://github.com/kubernetes/kubernetes/issues/41565
○ https://stackoverflow.com/questions/47332421/how-to-connect-to-an-headless-service-in-kubernetes-from-outside
74.
개요
● 풀려는 문제
○1. 각 pod마다 독립된 volume을 갖는 Fully managed pod group을 갖고 싶다
○ 2. 각 pod이 (재시작 되더라도) stable한 identity를 갖게 하고 싶다.(Stateful distributed system의 req)
ReplicaSet과 Service만으로 문제 풀기 ⇒ Hell이다.
75.
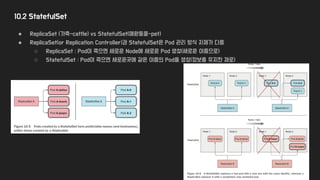
10.2 StatefulSet
● ReplicaSet(가축-cattle) vs StatefulSet(애완동물-pet)
● ReplicaSet(or Replication Controller)과 StatefulSet은 Pod 관리 방식 자체가 다름
○ ReplicaSet : Pod이 죽으면 새로운 Node에 새로운 Pod 생성(새로운 이름으로)
○ StatefulSet : Pod이 죽으면 새로운곳에 같은 이름의 Pod을 생성(정보를 유지한 채로)
76.
10.2 StatefulSet -Governing Service
● 문제 : stateful pod은 어떨때 hostname으로 접근해야 할 수 있음
○ Ex) 특정 Shard의 MasterNode와 같이 pod마다 들고 있는 state가 다를때,
● 방안
○ Headless Service를 이용, 각 pod의 주소로 직접 접근할 수 있게 한다.
○ 각 Pod은 DNS 각각 DNS Entry를 갖는다
○ StatefulSet의 각 node는 hostname으로 접근할 수 있는 체계를 갖는다.
■ 이름은 [statefulset name]-[index 0으로 시작]
■ domain name : a-0.foo.default.svc.cluster.local
77.
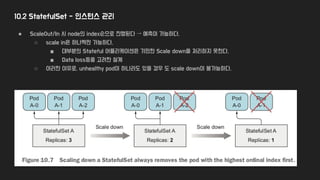
10.2 StatefulSet -인스턴스 관리
● ScaleOut/In 시 node의 index순으로 진행된다 → 예측이 가능하다.
○ scale in은 하나씩만 가능하다.
■ 대부분의 Stateful 어플리케이션은 기민한 Scale down을 처리하지 못한다.
■ Data loss등을 고려한 설계
○ 이러한 이유로, unhealthy pod이 하나라도 있을 경우 도 scale down이 불가능하다.
78.
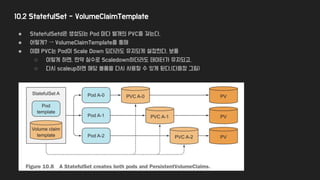
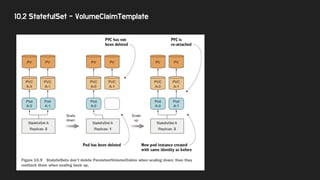
10.2 StatefulSet -VolumeClaimTemplate
● StatefulSetd은 생성되는 Pod 마다 별개의 PVC를 갖는다.
● 어떻게? → VolumeClaimTemplate를 통해
● 이때 PVC는 Pod이 Scale Down 되더라도 유지되게 설정한다. 보통
○ 이렇게 하면, 만약 실수로 Scaledown하더라도 데이터가 유지되고,
○ 다시 scaleup하면 해당 볼륨을 다시 사용할 수 있게 된다.(다음장 그림)
10.2 At-Most OneSemantic
● 앞서 본 2가지 특성에 추가로 StatefulSet의 추가 특이사항
● At Most one semantic : 동일 이름의 Pod이 최대 1개를 넘어가지 않도록 한다.
● 기존 Pod이 죽어 새로운 pod을 실행시키기 전에, 더 Detail한 확인을 거친 뒤에 실행시킨다.
○ 관리자가 명시적인 pod delete (or node delete)를 실행시켜 준 이후에 실패한 Pod의 복구 instance를 생성한다.
Node가 죽어 Kubelet이 상태 업데이트 불가 시 아래와 같이 강제 삭제 진행
● 만약 같은 이름이 2개의 pod이 실행될 경우
○ StatefulSet은 큰 문제가 된다.
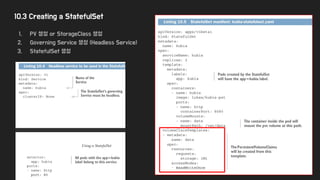
10.3 Creating aStatefulSet
1. PV 생성 or StorageClass 생성
2. Governing Service 생성 (Headless Service)
3. StatefulSet 생성
83.
10.3 StatefulSet 테스트하기
● 간단하게..
kubectl proxy를 이용해서 : kubectl proxy를 띄운 뒤 아래와 같이 접근
■ $ curl localhost:8001/api/v1/namespaces/default/pods/kubia-0/proxy/
84.
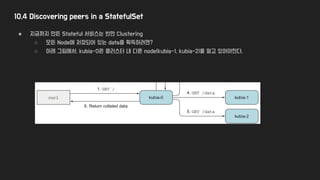
10.4 Discovering peersin a StatefulSet
● 지금까지 만든 Stateful 서비스는 반만 Clustering
○ 모든 Node에 저장되어 있는 data를 획득하려면?
○ 아래 그림에서, kubia-0은 클러스터 내 다른 node(kubia-1, kubia-2)를 알고 있어야한다.
85.
10.4 Discovering peersin a StatefulSet
● StatefulSet 을 구성하는 Peer들 간의 Discovery는?
○ Kubernetes-agnostic 한 방법, 즉, API Server를 통하지 않는 방법.
● 기존 방법
○ multicast (Aerospike, 등)
■ 동일 IP대역에 있어야 함.
■ IP대역에 두 개 이상 cluster 구성 시 오류발생 가능성
○ bootstrap (kafka 등)
○ Zookeeper 등 중재자 이용
● k8s
○ DNS의 SRV Record 이용
■ NGINX, HAProxy에서 이용
○ 이것도 일정부분 Kubernetes-agnostic하지 않나?
86.
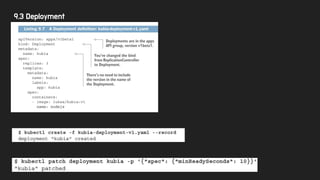
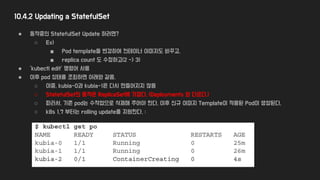
10.4.2 Updating aStatefulSet
● 동작중인 StatefulSet Update 하려면?
○ Ex)
■ Pod template을 변경하여 컨테이너 이미지도 바꾸고,
■ replica count 도 수정하고(2 -> 3)
● ‘kubectl edit’ 명령어 사용
● 이후 pod 상태를 조회하면 아래와 같음.
○ 이중, kubia-0과 kubia-1은 다시 만들어지지 않음
○ StatefulSet의 동작은 ReplicaSet에 가깝다. (Deployments 와 다르다.)
○ 따라서, 기존 pod는 수작업으로 삭제해 주어야 한다, 이후 신규 이미지 Template이 적용된 Pod이 생성된다.
○ k8s 1.7 부터는 rolling update를 지원한다. :
87.
k8s 1.7에서 갱신된내용 (링크)
● .spec.podManagementPolicy : 순서 보장여부정도를 조정할 수 있다.
○ OrderedReady(Default) : 기본 동작
○ Paraller : 동시에 Scaling 진행, 다음 동작 진행 전, Ready, Running, Completely Terminate 등의 상태까지 대기
하지 않는다.
■ Scaling 시에만 해당함,
■ Upgrade시에는 해당하지 않음
● .spec.updateStrategy
○ OnDelete : 1.6 이전의 동작과 동일
○ RollingUpdate(Default) : 한대씩 진행, index 큰 순부터 작은 순으로
■ Partition : 지정된 숫자의 Pod에만 배포 → canary release, phased release 등에서 활용
88.
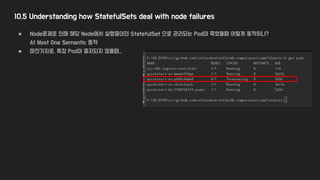
10.5 Understanding howStatefulSets deal with node failures
● Node문제로 인해 해당 Node에서 실행중이던 StatefulSet 으로 관리되는 Pod이 죽었을때 어떻게 동작하나?
At Most One Semantic 동작
● 마찬가지로, 특정 Pod이 중지되지 않을때..
시작하기 전에..
● 앞장까지는 바깥에서 보이는 동작에 대해서만 설명했다..
● 내부를 들어가기 전에 해당 시스템이 어떤 기능을 제공하는지에 대한 이해가 선행되어야 한다. (굉장히 공감)
● K8S가 아니라 업무적으로 새로운 시스템을 파악할때도 마찬가지다.
● 개발할때도 마찬가지의 흐름을 갖는다.
○ Context Diagram
○ Architecture
○ Detailed Design
92.
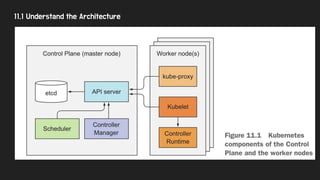
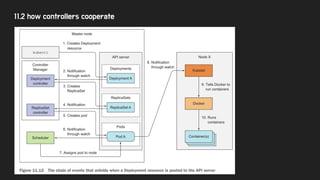
11.1 Understand theArchitecture
● K8S 를 구성하는 주요 컴포넌트
○ K8S Control Plane : container를 실행/관리 하는 역할을 한다.
■ etcd
■ api server
■ scheduler
■ controller manager
○ Worker Node : 실제로 container를 실행시키는 역할을 한다.
■ kublet
■ k8s service proxy
■ container runtime
○ AddOn Components
■ k8s DNS Server
■ Dashboard
■ An Ingress Controller
■ Heapster (14장에서 다룸)
■ Container network interface network plugin
93.
11.1 Understand theArchitecture
● 각 컴포넌트들은 별도의 프로세스로 동작한다.
● 모든 컴포넌트는 API Server하고만 통신한다. (직접 Comm하지 않는다.)
○ 통신의 시작은 각 컴포넌트에서 진행한다. (log를 가져올때나 Proxy등 세팅은 제외)
● Control Plane의 컴포넌트들은 H/A를 위해 2개 이상 실행될 수 있다.
○ ETCD, API Server는 여러 Node가 실행되어 Clustering됨
○ Scheduler, Controller Manager : Active/Stand by
● Control Plane 컴포넌트와, Kube Proxy는 Pod 형태로 실행되거나, OS에 바로 실행될 수 있다.
○ Kubelet만 예외 → 항상 OS에 직접 뜬다. Kublet이 pod을 실행하는 주체이다. (현재 우리 클러스터는? k8s 버전업은
어떻게 하나?)
94.
11.1.2 etcd는 어떻게사용되나?
● Cluster의 상태를 persistent 하게 저장하는 용도
● etcd의 접근은 오직 api-server만 한다.
● 이유는?
○ Optimistic locking, validation을 api server 끼리만 하면 됨 → 복잡도 감소
■ metadata.resourceVersion
■ Compare-And-Set
■ k8s의 전신인 Borg에서는 ControlPlane 컴포넌트가 직접 업데이트/optimist locking을 구현 → 버그가
만들어질 여지가 더 컸음
○ 저장소 추상화 → 향후 etcd 변경을 더 쉽게
● Key/value 구조 → 발표자료
● Ensuring consistency
○ RAFT 컨센서스 알고리즘을 사용함 ( zookeeper는 zab 알고리즘 : 링크 )
○
11.1.3 api server는어떻게 resource 변경을 알리나?
● https://github.com/kubernetes-client
○ https://github.com/kubernetes-client/java/tree/master/util/src/main/java/io/kubernetes/client/util
● k8s api concepts : https://kubernetes.io/docs/reference/using-api/api-concepts/
97.
11.1.5 Scheduler 이해하기
●Pod이 어떤 Node에서 실행될 지를 컨트롤 한다.
● api server의 watch 메커니즘을 통해 새로운 pod 생성을 기다린다.
○ 새롭게 생성된 pod 중 node가 assign되지 않은 pod에 node를 assign한 정보를 api server에 업데이트 한다.
● 이때 node를 선택하는 다양한 방법이 있을 수 있다. k8s의 현재버전은
○ 1. filtering : 자원상황, node 특성 등을 고려하여 pod이 실행가능한 node를 추린다.
○ 2. prioritizing : 실행가능한 node중 실제로 실행할 node를 선택한다.
■ resource 기준?
■ cloud 상황을 고려한 resource 기준?
● Scheduling 정책이 다양할 수 있다. 때문에 아래 옵션을 제공한다.
○ 여러개 Scheduler 사용 → pod을 띄울 때 scheduler를 지정할 수 있다.
○ Scheduler 사용하지 않음 → manual로 실행될 node 지정
○ Scheduler 커스터마이징 → 원하는 정책을 구현 가능하다.
●
98.
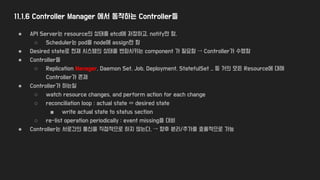
11.1.6 Controller Manager에서 동작하는 Controller들
● API Server는 resource의 상태를 etcd에 저장하고, notify만 함.
○ Scheduler는 pod을 node에 assign만 함
● Desired state로 현재 시스템의 상태를 변화시키는 component 가 필요함 → Controller가 수행함
● Controller들
○ Replication Manager, Daemon Set, Job, Deployment, StatefulSet .. 등 거의 모든 Resource에 대해
Controller가 존재
● Controller가 하는일
○ watch resource changes, and perform action for each change
○ reconciliation loop : actual state ⇔ desired state
■ write actual state to status section
○ re-list operation periodically : event missing을 대비
● Controller는 서로간의 통신을 직접적으로 하지 않는다. → 향후 분리/추가를 효율적으로 가능
99.
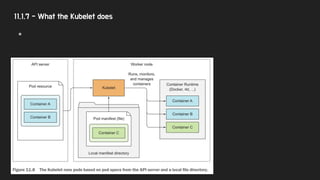
11.1.7 - Whatthe Kubelet does
● Kubelet → worker node에서 동작하는 모든것에 대한 책임
○ 가장 처음 하는일은 apiserver에 node resource를 등록하는 것
○ 그 이후 pod의 변경사항에 대해 api server 를 통하여 monitoring
○ 실행중인 container에 대해 모니터링 및 상태를 api server를 통해 reporting
■ status, event, resource consumption 정보
○ liveness prove 실행
○ pod 삭제 및 terminate event reporting
● Static Pods 실행 (without the api server)
○ 컨테이너 형태의 Control Plane 컴포넌트 실행에 사용
○ 정해진 local directory에 위치한 pod manifest 파일을 이용
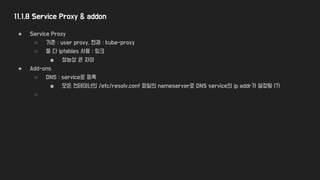
11.1.8 Service Proxy& addon
● Service Proxy
○ 기존 : user proxy, 현재 : kube-proxy
○ 둘 다 iptables 사용 : 링크
■ 성능상 큰 차이
● Add-ons
○ DNS : service로 등록
■ 모든 컨테이너의 /etc/resolv.conf 파일의 nameserver로 DNS service의 ip addr가 설정됨 (?)
○
11.2.3 Observing clusterevents
● Control Plane 및 Kubelet 모두 API Server를 통해 event를 emit 한다.
○ 이때 Event resource를 생성한다. (다른 resource와 동일)
●
104.
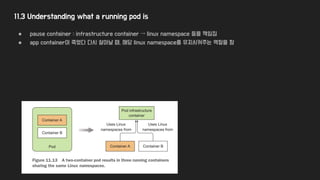
11.3 Understanding whata running pod is
● pause container : infrastructure container → linux namespace 등을 책임짐
● app container이 죽었다 다시 살아날 때, 해당 linux namespace를 유지시켜주는 역할을 함
105.
11.4 Inter-pod networking
●k8s 내 각 pod이 그 고유의 ip addr을 갖고, flat(nat-less) network을 가질 수 있는 이유
● System admin이 세팅하거나, CNI(Container Network Interface)를 통해 설정됨
●
추가된 Resource
● Localephemeral storage : 링크
○ Node 내에 Container간 공유하는 자원에 대한 Request/Limit 정의
■ Ex) /var/lib/kubelet : root dir
/var/log
○ How they are scheduled?
■
○ How limit run?
■ limit을 넘어가면, pod이 evic 된다.
Contents
● Automatic HorizontalScaling of Pods based on
○ CPU Utilization
○ Custom metrics
● Vertical scaling
○ not supported yet.
● Automatic Horigontal Scaling of Cluster nodes
● Autoscale 로직이 1.6, 1.7에서 완전히 새로 개발되었다.
110.
15.1. Horizontal podautoscaling
● HorizontalPodAutoscaler 를 통해 autoscale 기능을 설정할 수 있음
● Autoscaling은 다음 3단계로 이루어짐
○ 1. Scaled resource object에 의해 관리되는 모든 resource의 metric을 수집
○ 2. 지정한 Target value를 맞추기 위해 필요한 pod의 수를 계산
○ 3. 계산된 결과 값을 Replicas 필드에 업데이트
111.
15.1.1 - ObtainingPod Metrics
● Autoscaler가 metric을 직접 취득하지 않고, 앞장에서 언급한 cAdvisor를 통해 취합된 Metric을 heapster의 Rest API를
통해 요청한다. (Auto scale을 위해 Heapster가 필수인가?)
○ auto-scale 공식문서 ; 링크
● v 1.6 이전에는 HPAS가 metric을 heapster를 통해 직접 얻어왔었음
● v 1.8 이후 부터 Resource Metric API를 통해 얻어오도록 변경 가능(Optional)
● v 1.9 부터 해당 Option이 Default
112.
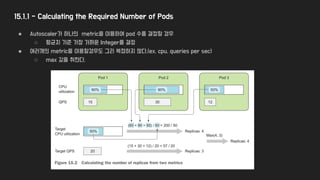
15.1.1 - Calculatingthe Required Number of Pods
● Autoscaler가 하나의 metric을 이용하여 pod 수를 결정할 경우
○ 평균치 기준 가장 가까운 Integer를 결정
● 여러개의 metric을 이용할경우도 그리 복잡하지 않다.(ex, cpu, queries per sec)
○ max 값을 취한다.
113.
15.1.1 - Updatingthe desired replica count on the scaled resource
● 앞 단계에서 계산된 값을 replicas field에 반영(Scaled Resource의)
○ 해당 Resource의 상세 내용을 몰라도 Autoscaler가 조작 할 수 있게 한다.
● 현재 Scale sub-resource를 노출하는 Resource
○ Deployments
○ ReplicaSets
○ ReplicationController
○ StatefulSets
●
114.
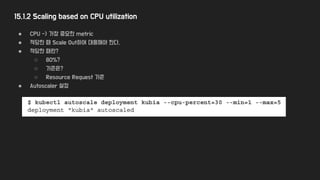
15.1.2 Scaling basedon CPU utilization
● CPU -> 가장 중요한 metric
● 적당한 때 Scale Out하여 대응해야 한다.
● 적당한 때란?
○ 80%?
○ 기준은?
○ Resource Request 기준
● Autoscaler 설정
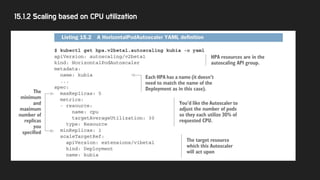
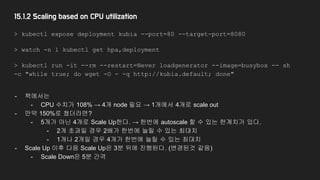
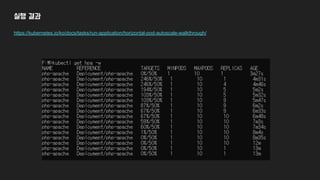
15.1.2 Scaling basedon CPU utilization
> kubectl expose deployment kubia --port=80 --target-port=8080
> watch -n 1 kubectl get hpa,deployment
> kubectl run -it --rm --restart=Never loadgenerator --image=busybox -- sh
-c "while true; do wget -O - -q http://kubia.default; done"
- 책에서는
- CPU 수치가 108% → 4개 node 필요 → 1개에서 4개로 scale out
- 만약 150%로 쳤더라면?
- 5개가 아닌 4개로 Scale Up한다. → 한번에 autoscale 할 수 있는 한계치가 있다.
- 2개 초과일 경우 2배가 한번에 늘릴 수 있는 최대치
- 1개나 2개일 경우 4개가 한번에 늘릴 수 있는 최대치
- Scale Up 이후 다음 Scale Up은 3분 뒤에 진행된다. (변경된것 같음)
- Scale Down은 5분 간격
15.1.3 Scaling basedon memory consumption and other metrics
● Memory 기반 Scaling 은 좀 더 고려해야 할 사항이 많다.
● k8s가 해준는 일은 POD을 죽이고, 새로 띄우는일 뿐이다.
● App 자체가 동일한 메모리를 소비한다면 지속적인 Scaling 이 발생할 수 밖에 없다.
● 결국 App이 Scale Out 될 수 있게 만들어 져야 한다.
119.
15.1.5 Determining whichmetrics are appropriate for autoscaling
● Autoscale metric 선정
○ 원하는 Autoscaling을 위해서는 metric 선정을 신중히 해야 한다.
■ memory 소모량은 그다지 좋은 metric이 아니다.
○ pod의 증가에 따라 선형적으로 감소하는 metric을 Autoscaler의 기준값으로 삼아야 한다.
● Auto scale down to zero
○ Ideling/unideling
○ 현재 k8s은 ideling을 지원하지 않음
○ k8s의 이슈로 논의되고 있음 : https://github.com/kubernetes/kubernetes/issues/69687
120.
15.2 Vertical podautoscaling (Scale Up?)
● 결론 : 글 쓰는 시점에 불가능했다.
● 왜?
○ 현재, 실행중인 pod의 resource request/limt 수정이 불가능하다. (글 쓰는 시점)
○ Proposal이 Finalize 되었다고 함
● VPA : https://cloud.google.com/kubernetes-engine/docs/concepts/verticalpodautoscaler
○ 특징 : Autoscaler가 기존 사용량을 보고 cpu/memory 사용량을 추천 or update
■ 적절한 request/limit 수치를 위해 성능 테스트를 돌리지 않아도 된다.
○ 한계점
■ cluster 당 500개 VPA object만 허용함
■ 1.12.6 이후 regional cluster에서만 허용함
■ VPA와 HPA(CPU, Memory 기반)같이 쓰지 않아야 한다.
● custom/external metric 기반의 HPA와는 같이 쓸 수 있다.
■ Java workload에 사용할 수 없다.(actual memory usage를 파악하기 힘든 제약 때문)
121.
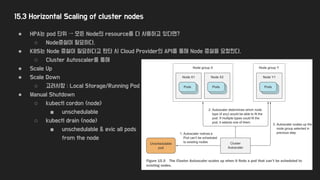
15.3 Horizontal Scalingof cluster nodes
● HPA는 pod 단위 → 모든 Node의 resource를 다 사용하고 있다면?
○ Node증설이 필요하다.
● K8S는 Node 증설이 필요하다고 판단 시 Cloud Provider의 API를 통해 Node 증설을 요청한다.
○ Cluster Autoscaler를 통해
● Scale Up
● Scale Down
○ 고려사항 : Local Storage/Running Pod
● Manual Shutdown
○ kubectl cordon <node>
■ unschedulable
○ kubectl drain <node>
■ unschedulable & evic all pods
from the node
Contents
● How todefine our own API
● K8S를 확장하여 Platform-as-a-Service를 만든 예시를 통해 어느정도까지 확장하고 활용할 수 있는지?
125.
18.1 Defining customAPI objects
● 앞 서 나온 Resource(Pod, Deployments.. 등) 들은 Low Level Resource
● 이를 그대로 쓸 수도 있지만, Application 전체 또는 S/W를 나타내는 Object를 정의해 사용할 수 있음
○ Ex) Queue (Deployments, Service 등)
● Custom Resource Definition (CRD)
○ Description of custom resource type
○ Resource를 확장하려면 CRD를 K8S Api를 통해 Post 해야 함
○ 1.7 이전에는 ThiredPartyResource object를 통해 확장했었음
126.
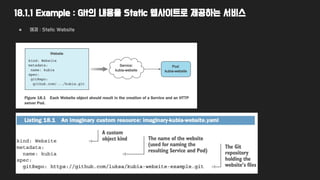
18.1.1 Example :Git의 내용을 Static 웹사이트로 제공하는 서비스
● 예제 : Static Website
127.
18.1.1 Example :CRD
● apiVersion 항목은 api group과 version으로 되어 있음
● CRD를 기술하는 항목도 4가지로 동일함
● Singular, plural 은 어디에 쓰일까?
● Scope : namespaced / cluster-scoped
128.
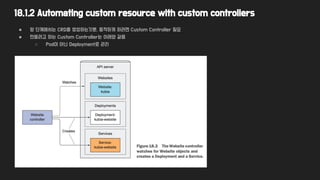
18.1.2 Automating customresource with custom controllers
● 앞 단계에서는 CRD를 생성하는것뿐, 동작하게 하려면 Custom Controller 필요
● 만들려고 하는 Custom Controller는 아래와 같음
○ Pod이 아닌 Deployment로 관리
129.
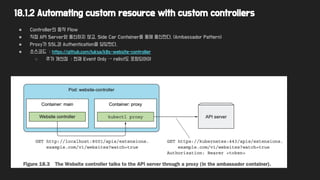
18.1.2 Automating customresource with custom controllers
● Controller의 동작 Flow
● 직접 API Server와 통신하지 않고, Side Car Container를 통해 통신한다. (Ambassador Pattern)
● Proxy가 SSL과 Authentication을 담당한다.
● 소스코드 : https://github.com/luksa/k8s-website-controller
○ 추가 개선점 : 현재 Event Only → relist도 포함되어야
130.
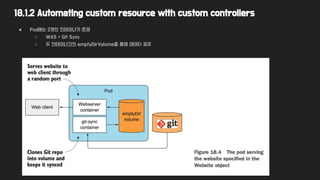
18.1.2 Automating customresource with custom controllers
● Pod에는 2개의 컨테이너가 존재
○ WAS + Git Sync
○ 두 컨테이너간의 emptyDirVolume을 통해 데이터 공유
131.
18.1.2 Running thecontroller as a pod
● Controller 개발 tip
○ Kubectl proxy를 local에 띄워 매번 컨테이너 이미지로 만들지 않아도 되게 함
● 배포시
○ Controller를 Deployment로 배포함
132.
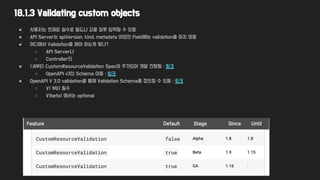
18.1.3 Validating customobjects
● 사용자는 언제든 실수로 필드나 값을 잘못 입력할 수 있음
● API Server는 apiVersion, kind, metadata 이외의 Field에는 validation을 하지 않음
● 어디에서 Validation을 해야 하는게 맞나?
○ API Server나
○ Controller단
● 1.8부터 CustomResourceValidation Spec이 추가되어 개발 진행됨 : 링크
○ OpenAPI v3의 Schema 이용 : 링크
● OpenAPI V 3.0 validation을 통해 Validation Schema를 정의할 수 있음 : 링크
○ V1 부터 필수
○ V1beta1 에서는 optional
133.
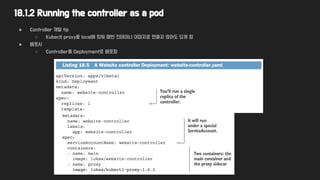
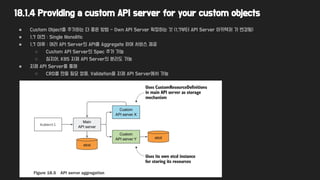
18.1.4 Providing acustom API server for your custom objects
● Custom Object를 추가하는 더 좋은 방법 - Own API Server 확장하는 것 (1.7부터 API Server 아키텍처 가 변경됨)
● 1.7 이전 : Single Monolitic
● 1.7 이후 : 여러 API Server의 API를 Aggregate 하여 서비스 제공
○ Custom API Server의 Spec 추가 가능
○ 심지어, K8S 자체 API Server의 분리도 가능
● 자체 API Server를 통해
○ CRD를 만들 필요 없음, Validation을 자체 API Server에서 가능
134.
18.1.4 Registering acustom API servers
● Pod 형태로 Deploy + Service로 Expose
● APIService 배포
● 그 외 CLI도 만들 수 있음
135.
조금 복잡한 예제
●https://github.com/elastic/cloud-on-k8s/blob/master/config/crds/all-crds.yaml#L412
● https://download.elastic.co/downloads/eck/1.0.0-beta1/all-in-one.yaml
●
136.
18.1.4 Registering acustom API servers
● Pod 형태로 Deploy + Service로 Expose
● APIService 배포
● 그 외 CLI도 만들 수 있음
137.
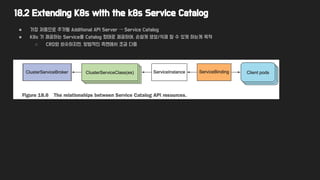
18.2 Extending K8swith the k8s Service Catalog
● 가장 처음으로 추가될 Additional API Server → Service Catalog
● K8s 가 제공하는 Service를 Catalog 형태로 제공하여, 손쉽게 생성/삭제 할 수 있게 하는게 목적
○ CRD와 비슷하지만, 방법적인 측면에서 조금 다름
138.
18.2 Extending K8swith the k8s Service Catalog
● 최근 CRD Based Architecture로 변경됨 - 기존 아키텍처는 2020년 July까지만 Bug fix를 지원함
○ https://github.com/kubernetes-sigs/service-catalog
● Open Service Broker API
○ https://svc-cat.io/
● GCP Service Broker
○ https://github.com/GoogleCloudPlatform/gcp-service-broker
○ https://cloud.google.com/kubernetes-engine/docs/how-to/add-on/service-broker-overview
139.
18.3 Platforms builton top of Kubernetes - OpenShift
● PaaS Solution (2011년 4월 최초 릴리즈) : wikipedia
○ 개발/운영을 편하게 하기 위한 기능들 제공
○ Rapid dev, easy deployment, scaling, and long-term maintenance
● Ver1, 2에서는 맨바닥에서 K8S 맨바닥에서 container/container orchestration 부분을 자체 구현
● Ver3부터 기존 코드를 버리고 Kubernetes 위에서 새롭게 구현함
● Additional Resources
○ Users & Group, Projects
■ User별 Group 별 Project 권한을 관리함 → RBAC 를 만드는데 기여했다고 함
○ Templates
■ Kubernetes의 Yaml을 변수화 함
■ Template API Server에 저장될 수 있음
■ 자주 사용하는 Template을 제공함
■ ex) Java EE Application을 동작하기
위한 모든 Resource 들
140.
18.3 Platforms builton top of Kubernetes - OpenShift
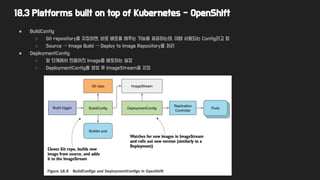
● BuildConfig
○ Git repository를 지정하면, 바로 배포를 해주는 기능을 제공하는데, 이때 사용되는 Config라고 함
○ Source → Image Build → Deploy to Image Repository를 처리
● DeploymentConfig
○ 앞 단계에서 만들어진 Image를 배포하는 설정
○ DeploymentConfig를 생성 후 ImageStream을 지정
141.
18.3 Platforms builton top of Kubernetes - OpenShift
● Route
○ Ingress가 있기 전 OpenShift에서 Server Expose하는 방법이었음
○ Ingress와 비슷하다고 함
142.
18.3.2 Deis Workflowand Helm
● Deis Workflow
○ DevOps Workflow를 지원하는 프로젝트
○ OpenShift와 비슷하지만, 구조는 다름
○ MS에 판매되었다고 함
○ 프로젝트는 현재 관리되고 있지 않음
○ Helm도 여기서 만들었음
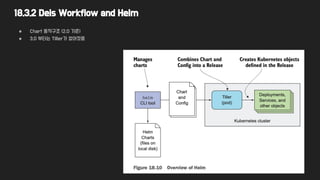
● Helm : Package Manager for Kubernetes (similar to yum or apt)
○ K8s application을 설치할 때 Manifest를 써야 하는데, Helm을 통하면 그러지 않아도 된다.
○ 2가지 컴포넌트로 구성됨 : Helm Cli Tool, Tiller
○ 2가지 개념 정의
■ Chart : Application Package
■ Config : 설정정보
○ Chart는 Local에 만들 수도 있고 Repository에 저장할 수도 있음
■ https://github.com/helm/charts


















![5.1 서비스는 어떻게 정의하나?
● ReplicationController와 동일한 방법 (Label Selector). (default type : ClusterIP)
● 실습 : 서비스에서 생성된 ip로 접근해보기
○ > kubectl exec [pod_id] -- curl -s http://[service ip]
○ 여기서 ‘--’ 는 kubectl 명령어의 끝을 명시적으로 표시한다. 이게 없으면 뒷 부분 -s를 옵션으로 인식 한다.](https://image.slidesharecdn.com/kubernetesinaction-200712053350/85/Kubernetes-in-action-33-320.jpg)
![5.1 서비스 Discovery
● 기본적으로 환경 변수를 통해 Discovery함
● K8S 내부 DNS를 이용할 수도 있음
○ kube-system namespace 내 kube-dns Pod
○ Pod 내의 dnsPolicy 프로퍼티로 설정 가능
● Domain 규칙
○ [service명].[namespace].[cluster domain(configurable)]
○ Ex), kubia.default.svc.cluster.local](https://image.slidesharecdn.com/kubernetesinaction-200712053350/85/Kubernetes-in-action-35-320.jpg)













![7.2 Command line arg 를 컨테이너에 전달하기
● Docker image에 cmd arg 정의하기
○ 두 가지 방법 존재
■ shell form : >ENTRYPOINT node app.js
● invoked inside a shell
■ exec form : ENTRYPOINT ["node", "app.js"].
● Directly invoked
○ shell process는 불필요함 → 대부분 exec 형식을 쓴다.](https://image.slidesharecdn.com/kubernetesinaction-200712053350/85/Kubernetes-in-action-65-320.jpg)





![10.2 StatefulSet - Governing Service
● 문제 : stateful pod은 어떨때 hostname으로 접근해야 할 수 있음
○ Ex) 특정 Shard의 MasterNode와 같이 pod마다 들고 있는 state가 다를때,
● 방안
○ Headless Service를 이용, 각 pod의 주소로 직접 접근할 수 있게 한다.
○ 각 Pod은 DNS 각각 DNS Entry를 갖는다
○ StatefulSet의 각 node는 hostname으로 접근할 수 있는 체계를 갖는다.
■ 이름은 [statefulset name]-[index 0으로 시작]
■ domain name : a-0.foo.default.svc.cluster.local](https://image.slidesharecdn.com/kubernetesinaction-200712053350/85/Kubernetes-in-action-76-320.jpg)



















































![[오픈소스컨설팅]쿠버네티스를 활용한 개발환경 구축](https://cdn.slidesharecdn.com/ss_thumbnails/opensourceconsutingkubernetesv0-191010000815-thumbnail.jpg?width=640&height=640&fit=bounds)



![[2019.04] 쿠버네티스 기반 하이퍼레저 패브릭 네트워크 구축하기](https://cdn.slidesharecdn.com/ss_thumbnails/hyperledgerfabriconk8s-190418042054-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NDC17] Kubernetes로 개발서버 간단히 찍어내기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-170529041601-thumbnail.jpg?width=640&height=640&fit=bounds)

![[OpenInfra Days Korea 2018] Day 2 - E5: Mesos to Kubernetes, Cloud Native 서비스...](https://cdn.slidesharecdn.com/ss_thumbnails/e60930openinfraday2018dennis-180705030830-thumbnail.jpg?width=640&height=640&fit=bounds)





![[slideshare]k8s.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/slidesharek8s-230220092542-d3b7cf4c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[OpenInfra Days Korea 2018] K8s workshop: with containers & K8s on OpenStack ...](https://cdn.slidesharecdn.com/ss_thumbnails/oidk2018-day2-k8s-180701165541-thumbnail.jpg?width=640&height=640&fit=bounds)