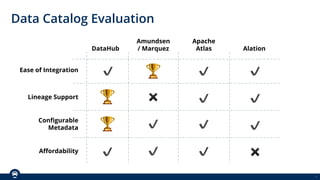
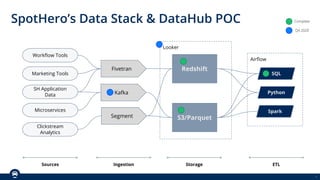
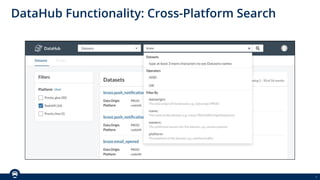
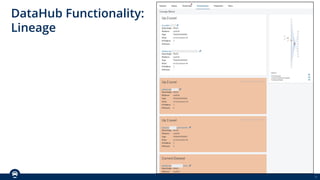
The document outlines Spothero's current state of data discoverability, highlighting challenges with data lineage and the reliance on tribal knowledge. It evaluates several data catalog tools, including Datahub and Amundsen/Marquez, and details the progress and effort involved in a Datahub proof of concept (POC). The POC aims to enhance data discoverability through improved integration, metadata management, and lineage tracking.