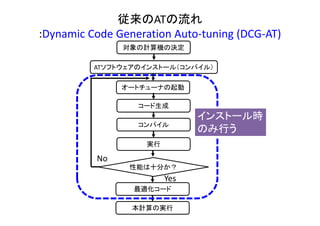
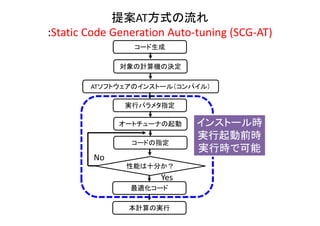
本報告では,自動チューニング(AT)を実行するに当たり,コード最適化時に動的なコード生成とコンパイルを行わず,実行前に静的に生成したコードのみを利用するATソフトウェア構成方式のStatic Code Generation Auto-tuning (SCG-AT)を提案する.SCG-ATによるATを評価するにあたり「階層型AT処理」を実装した.差分法による地震波シミュレーションppOpen-APPL/FDMにおいて,従来のベクトル計算機向けコードと新規開発したスカラ計算機向けコードのコード選択処理を実装した.Xeon Phi,Ivy Bridge,およびFX10の3種の全く異なる計算機でSSG-ATによるコード選択のATを評価した.評価の結果,Xeon PhiとIvy Bridgeにおいてはスカラ計算機向けコードの選択により,従来行われていたAT方式では達成できない速度向上が達成できることを明らかにした.
------
ここに掲載した著作物の利用に関する注意 本著作物の著作権は情報処理学会に帰属します。本著作物は著作権者である情報処理学会の許可のもとに掲載するものです。ご利用に当たっては「著作権法」ならびに「情報処理学会倫理綱領」に従うことをお願いいたします。
Notice for the use of this material The copyright of this material is retained by the Information Processing Society of Japan (IPSJ). This material is published on this web site with the agreement of the author (s) and the IPSJ. Please be complied with Copyright Law of Japan and the Code of Ethics of the IPSJ if any users wish to reproduce, make derivative work, distribute or make available to the public any part or whole thereof.
All Rights Reserved, Copyright (C) Information Processing Society of Japan.
Comments are welcome. Mail to address editj@ipsj.or.jp, please.




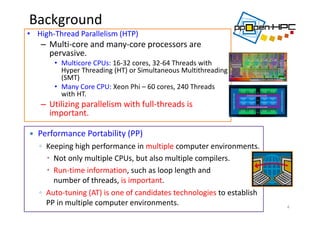

![ppOpen‐APPL/FDMへの適用シナリオ
9
AT無しで、最適化された
カーネルの実行
ライブラリ
利用者
ATパラメタの指定と
ライブラリの実行
(OAT_AT_EXEC=1)
■オートチューナの実行
固定ループ長での実行
(行列サイズ、MPIプロセス数、
OpenMPスレッド数の固定による)
対象カーネルの実行時間の計測
最適パラメタ情報の収納
ATパラメタの指定と
ライブラリの実行
(OAT_AT_EXEC=0)
最速カーネル情報の
収納
ATなしで最速カーネルを使う
(行列サイズ、MPIプロセス数、
OpenMPスレッド数を変えない限り有効)
行列サイズ、
MPIプロセス数、
OpenMPスレッド数の指定
[FIBER方式、2003]
実行起動前時AT](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-8-320.jpg)




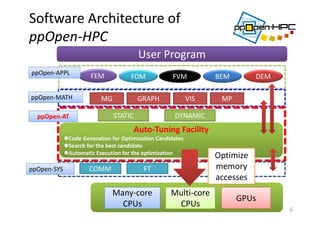
![ppOpen‐APPL/FDMの
手続き間流れ図
19
),,,(
}],,,)
2
1
({},,)
2
1
({[
1
),,(
2/
1
zyxqp
zyxmxzyxmxc
x
zyx
dx
d
pqpq
M
m
m
pq
中心差分近似による空間微分の評価
),,(,
12
1
2
1
zyxptf
zyx
uu n
p
n
zp
n
yp
n
xpn
p
n
p
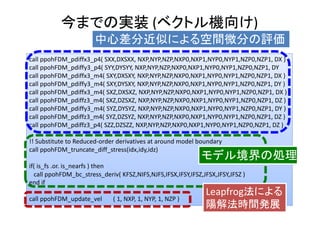
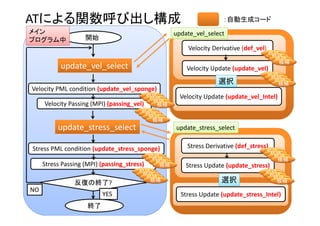
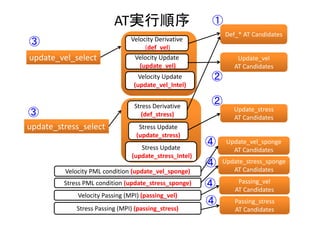
Leapfrog法による陽解法時間発展
開始
Velocity Derivative (def_vel)
Velocity Update (update_vel)
Stress Derivative (def_stress)
Stress Update (update_stress)
反復の終了?
NO
YES
終了
Velocity PML condition (update_vel_sponge)
Velocity Passing (MPI) (passing_vel)
Stress PML condition (update_stress_sponge)
Stress Passing (MPI) (passing_stress)](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-16-320.jpg)

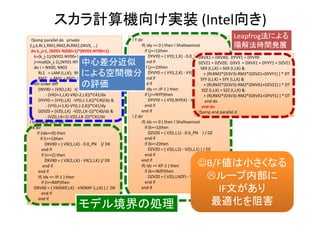










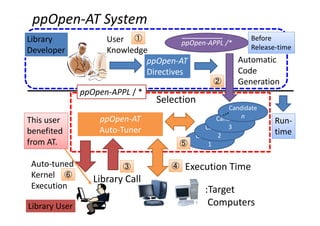
![0
200
400
600
800
1000
1200
1400
P8T240 P16T120 P32T60 P64T30 P128T15 P240T8 P480T4
Others
IO
passing_stre
ss
passing_velo
city
update_vel_
sponge
update_vel
update_stre
ss_sponge
update_stre
ss
Whole Time (2000 time steps)
[Seconds]
Comp.
Time
Comm.
Time
NX*NY*NZ = 1536x768x240/ 8 Node
Hybrid MPI/OpenMP
Phi : 8 Nodes (1920 Threads)
Original Code
AT without code selection
Full AT](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-36-320.jpg)
![1.12
1.31
1.04
1.17
1.55
1.78
0.95
1.48
1.15
1.50
1.09
1.71
1.17
1.68
0.80
1.00
1.20
1.40
1.60
1.80
2.00
P8T240 P16T120 P32T60 P64T30 P128T15 P240T8 P480T4
Speedups
Whole Time (Speedups)
[Speedups]
NX*NY*NZ = 1536x768x240/ 8 Node
Original Code
AT without code selection
Full AT
Hybrid MPI/OpenMP
Phi : 8 Nodes (1920 Threads)
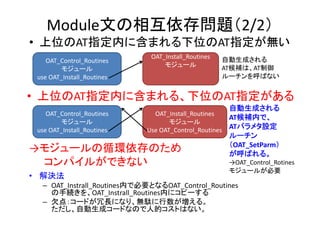
今までのATとコード選択で
最大1.78x](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-37-320.jpg)
![0
50
100
150
200
250
300
350
400
P8T240 P16T120 P32T60 P64T30 P128T15 P240T8 P480T4
update_stre
ss
update_stress (2000 time step)[Seconds]
NX*NY*NZ = 1536x768x240/ 8 Node
Hybrid MPI/OpenMP
Phi : 8 Nodes (1920 Threads)
Original Code
AT without code selection
Full AT](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-38-320.jpg)
![1.47
2.09
1.03
1.46
3.93
6.44
0.81
3.35
1.73
3.21
1.12
4.39
1.18
3.44
0.00
1.00
2.00
3.00
4.00
5.00
6.00
7.00
P8T240 P16T120 P32T60 P64T30 P128T15 P240T8 P480T4
Speedups
update_stress (speedups)[Seconds]
NX*NY*NZ = 1536x768x240/ 8 Node
Original Code
AT without code selection
Full AT
Hybrid MPI/OpenMP
Phi : 8 Nodes (1920 Threads)
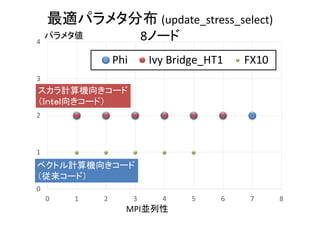
コード選択で
最大6.44x](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-39-320.jpg)
![0
50
100
150
200
250
300
350
400
P8T240 P16T120 P32T60 P64T30 P128T15 P240T8 P480T4
update_vel
update_vel (2000 time step)[Seconds]
NX*NY*NZ = 1536x768x240/ 8 Node
Hybrid MPI/OpenMP
Phi : 8 Nodes (1920 Threads)
Original Code
AT without code selection
Full AT](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-40-320.jpg)
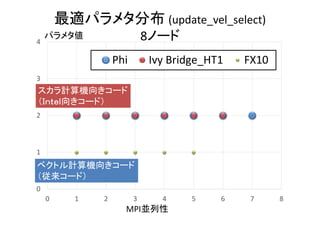
![1.11 1.11
1.00
1.00
0.99
1.01
1.04
0.97
1.09
1.19 1.18
1.18 1.21
1.25
0.50
0.60
0.70
0.80
0.90
1.00
1.10
1.20
1.30
1.40
1.50
P8T240 P16T120 P32T60 P64T30 P128T15 P240T8 P480T4
speedups
update_vel (speedups)[Seconds]
NX*NY*NZ = 1536x768x240/ 8 Node
Original Code
AT without code selection
Full AT
Hybrid MPI/OpenMP
Phi : 8 Nodes (1920 Threads)](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-41-320.jpg)



![0
500
1000
1500
2000
2500
P8T20 P16T10 P32T5 P40T4 P80T2 P160T1
Others
IO
passing_stress
passing_veloci
ty
update_vel_s
ponge
update_vel
update_stress
_sponge
update_stress
Whole Time (2000 Time Steps)[Seconds]
Comp.
Time
Comm.
Time
Original Code
AT without code selection
Full AT](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-45-320.jpg)
![1.02
1.38
1.01
1.36
0.97
1.15
1.06
1.23
1.01
1.11
0.96
1.04
0.50
0.60
0.70
0.80
0.90
1.00
1.10
1.20
1.30
1.40
1.50
P8T20 P16T10 P32T5 P40T4 P80T2 P160T1
Speedups
Whole Time (speedups)[Speedups]
Original
Code
AT without code selection
Full AT
今までのATとコード選択で
最大1.38x](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-46-320.jpg)
![0
50
100
150
200
250
300
350
P8T20 P16T10 P32T5 P40T4 P80T2 P160T1
update_stre
ss
Update_stress (2000 Time Steps)[Seconds]
Original Code
AT without code selection
Full AT](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-47-320.jpg)
![1.02
1.80
1.04
2.27
1.08
1.71
0.98
1.74
1.07
2.09
1.10
2.05
0.00
0.50
1.00
1.50
2.00
2.50
P8T20 P16T10 P32T5 P40T4 P80T2 P160T1
speedups
Update_stress (speedups)
[Speedups]
Original Code
AT without code selection
Full AT
コード選択で
最大2.27x](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-48-320.jpg)
![0
50
100
150
200
250
300
P8T20 P16T10 P32T5 P40T4 P80T2 P160T1
update_
vel
Update_vel (2000 Time Steps)[Seconds]
Original Code
AT without code selection
Full AT](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-49-320.jpg)
![1.00
1.03
1.04
1.09
1.04
0.76
0.95
0.82
1.02
1.02
1.06
0.95
0.50
0.60
0.70
0.80
0.90
1.00
1.10
1.20
P8T20 P16T10 P32T5 P40T4 P80T2 P160T1
speed
ups
Update_vel (speedups)[Speedups]
Original Code
AT without code selection
Full AT](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-50-320.jpg)


![0
100
200
300
400
500
600
700
800
900
1000
P8T16 P16T8 P32T4 P64T2 P128T1
Others
IO
passing_stress
passing_velocit
y
update_vel_sp
onge
update_vel
update_stress_
sponge
update_stress
Whole Time (2000 time steps)
[Seconds]
Comp.
Time
Comm.
Time
Original Code
AT using scalar CPU code
Full AT](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-54-320.jpg)
![1.02
0.73
1.01
0.76
1.00
0.66
1.02
0.66
1.01
0.69
0.00
0.20
0.40
0.60
0.80
1.00
1.20
P8T16 P16T8 P32T4 P64T2 P128T1
Speedups
Whole Time (speedups)
[Speedups]
Original Code
AT using scalar CPU code
Full AT
スカラ計算機向けコード
を選択すると
最大0.66xの速度低下](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-55-320.jpg)
![0
50
100
150
200
250
300
350
400
P8T16 P16T8 P32T4 P64T2 P128T1
update_
stress
Update_stress (2000 time steps)
[Seconds]
Original Code
AT using scalar CPU code
Full AT](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-56-320.jpg)
![1.00
0.87
1.00
0.97 1.00
0.82
0.95
0.68
0.89
0.81
0.00
0.20
0.40
0.60
0.80
1.00
1.20
P8T16 P16T8 P32T4 P64T2 P128T1
speed
ups
Update_stress (speedups)
[Speedups]
Original Code
AT using Intel CPU code
Full AT
スカラ計算機向けコード
を選択すると
最大0.68xの速度低下](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-57-320.jpg)
![0
50
100
150
200
250
300
350
400
450
500
P8T16 P16T8 P32T4 P64T2 P128T1
update
_vel
Update_vel (2000 time steps)
[Seconds]
Original Code
AT using scalar CPU code
Full AT](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-58-320.jpg)
![1.01
0.61
1.01
0.64
1.01
0.52
0.98
0.50
0.90
0.42
0.00
0.20
0.40
0.60
0.80
1.00
1.20
P8T16 P16T8 P32T4 P64T2 P128T1
Speed
ups
Update_vel (speedups)
[speedups]
Original Code
AT using scalar CPU code
Full AT](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-59-320.jpg)
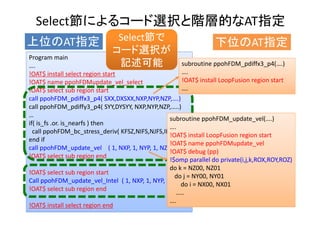
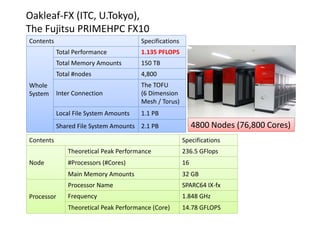
![Profiling Results (FX10, P64T2)
カーネル
種別
L1 miss
dm [%]
L1 miss
swpf
[%]
SIMD
Operati
on [%]
Theo‐
retical
Peak
[%]
Memory
Through
put
[GB/s] /
2 Threads
ベクトル
計算機
向きコード
35.7 1.56 82.5 8.99 8.89
スカラ
計算機
向き
コード
59.5 15.5 0.00 6.07 3.06
Update_stress
スカラ計算機向けコードは、L1ソフトウェア・プリフェッチ・
ミスヒット増加+SIMDコードが生成されない
→ループ内のIF文がコンパイラ最適化を阻害](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-60-320.jpg)
![Profiling Results (FX10, P64T2)
カーネル
種別
L1 miss
dm [%]
L1 miss
swpf
[%]
SIMD
Operati
on [%]
Theo‐
retical
Peak
[%]
Memory
Through
put
[GB/s] /
2 Threads
ベクトル計
算機向き
コード
35.6 0.00 86.6 12.2 9.85
スカラ計算
機向き
コード
48.7 5.73 0.00 5.45 2.35
Update_vel](https://image.slidesharecdn.com/hpc150-rev0-hp-150806015725-lva1-app6892/85/SCG-AT-61-320.jpg)