Download as PDF, PPTX











![CONFIDENTIAL. Copyright © 22
2nd : Easy integration into existing tech stacks
from dagster import materialize
if __name__ == "__main__":
result = materialize(assets=[my_first_asset])
pip install dagster dagit
Just install
And materialize your assets
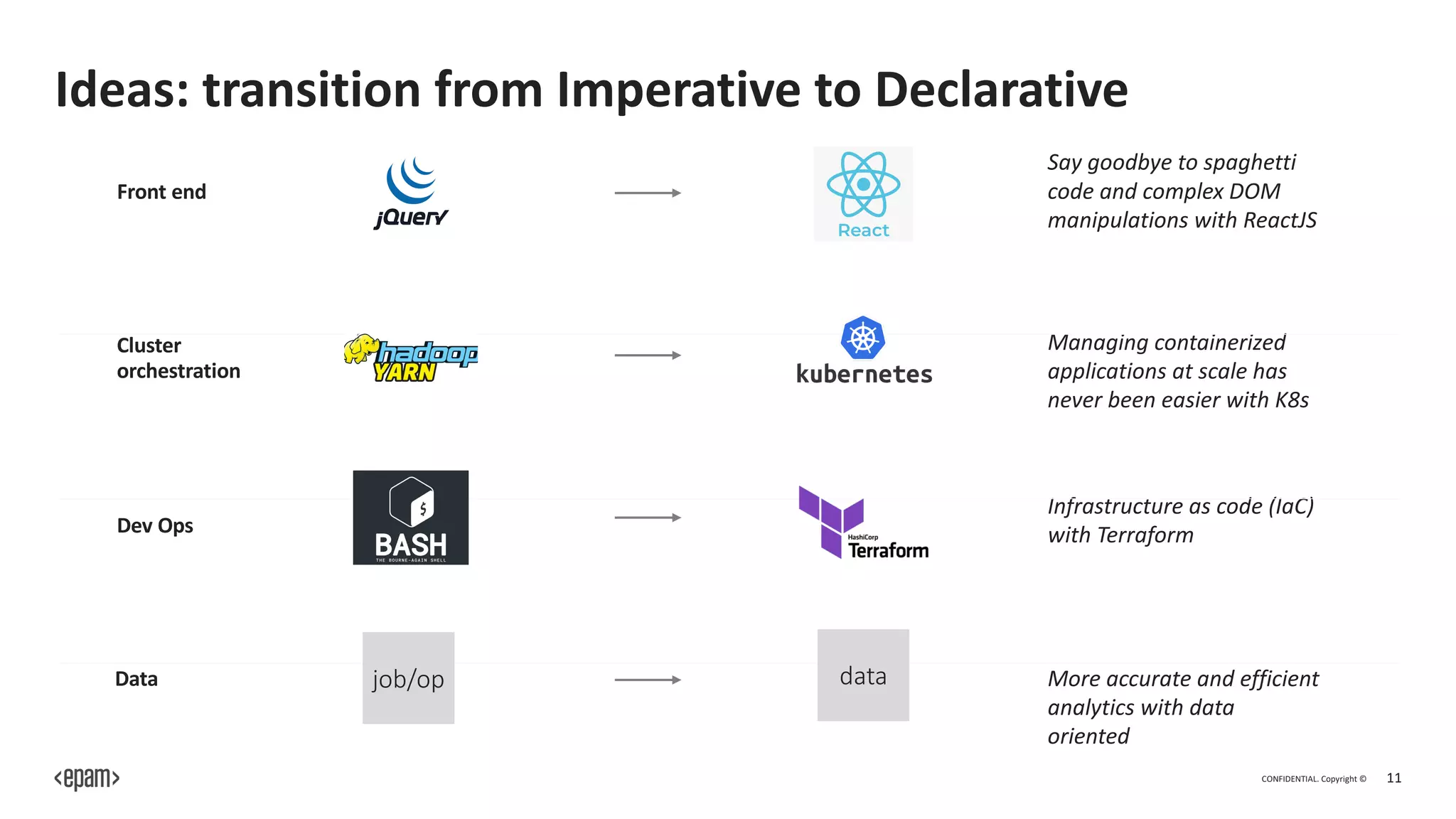
Extensibility and integration: Dagster has a rich ecosystem
of libraries and plugins that support various tools and
platforms related to machine learning, data processing,
and infrastructure. This extensibility allows ML engineers
to integrate Dagster with existing tools and systems.](https://image.slidesharecdn.com/dagster-dataopsandmlopsformachinelearningengineers-230814084609-92abfc05/75/Dagster-DataOps-and-MLOps-for-Machine-Learning-Engineers-pdf-22-2048.jpg)



![CONFIDENTIAL. Copyright © 32
5th : Debug, test data pipeline
from dagster import asset
@asset
def my_first_asset(context):
context.log.info("This is my first asset")
return 1
from dagster import materialize, build_op_context
def test_my_first_asset():
result = materialize(assets=[my_first_asset])
assert result.success
context = build_op_context()
assert my_first_asset(context) == 1
my_assets.py
test_my_assets.py
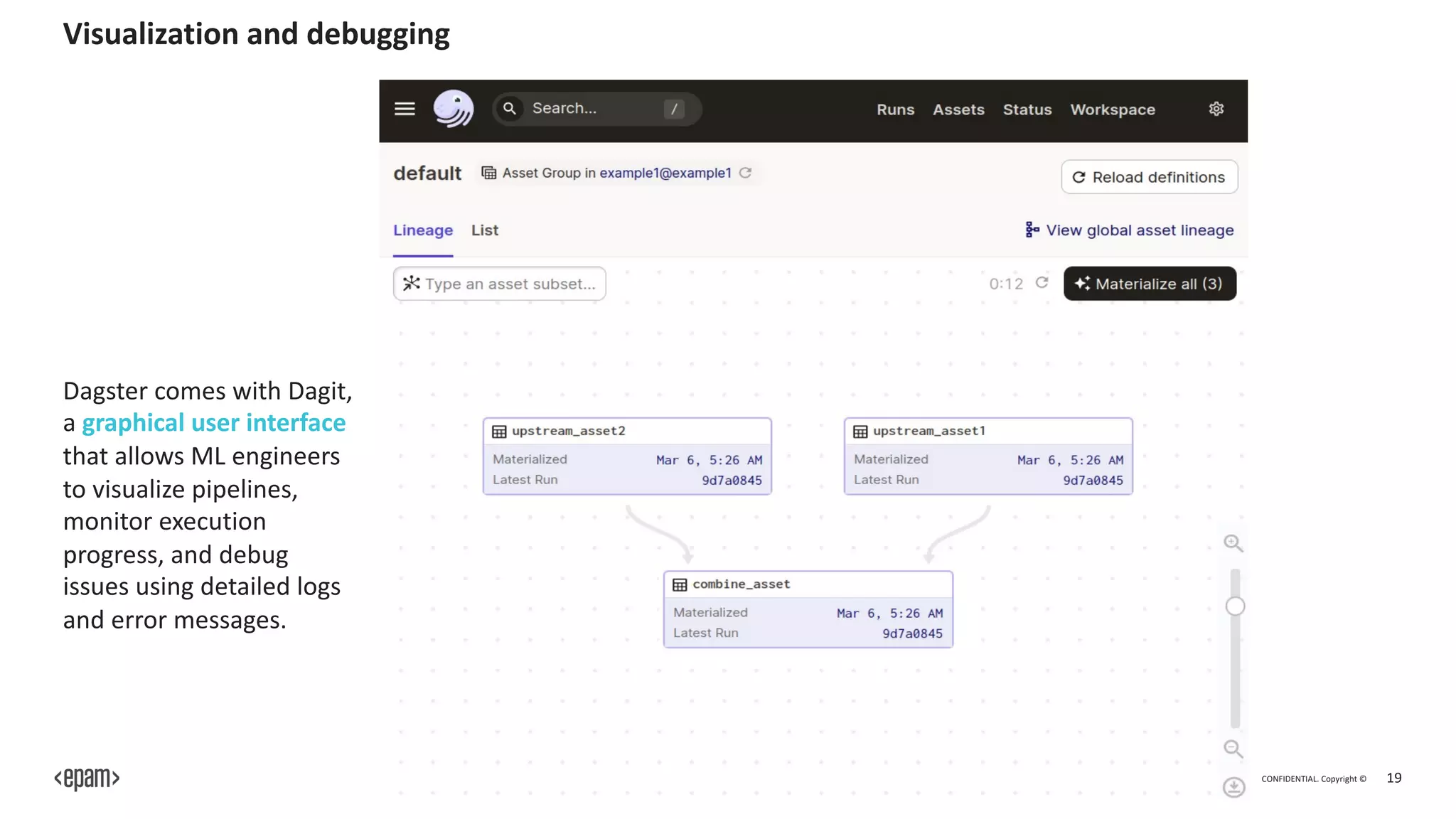
Testing and development: Dagster supports
local development and testing by enabling
execution of individual assets or entire
pipelines independent of the production
environment, fostering faster iteration and
experimentation.](https://image.slidesharecdn.com/dagster-dataopsandmlopsformachinelearningengineers-230814084609-92abfc05/75/Dagster-DataOps-and-MLOps-for-Machine-Learning-Engineers-pdf-32-2048.jpg)





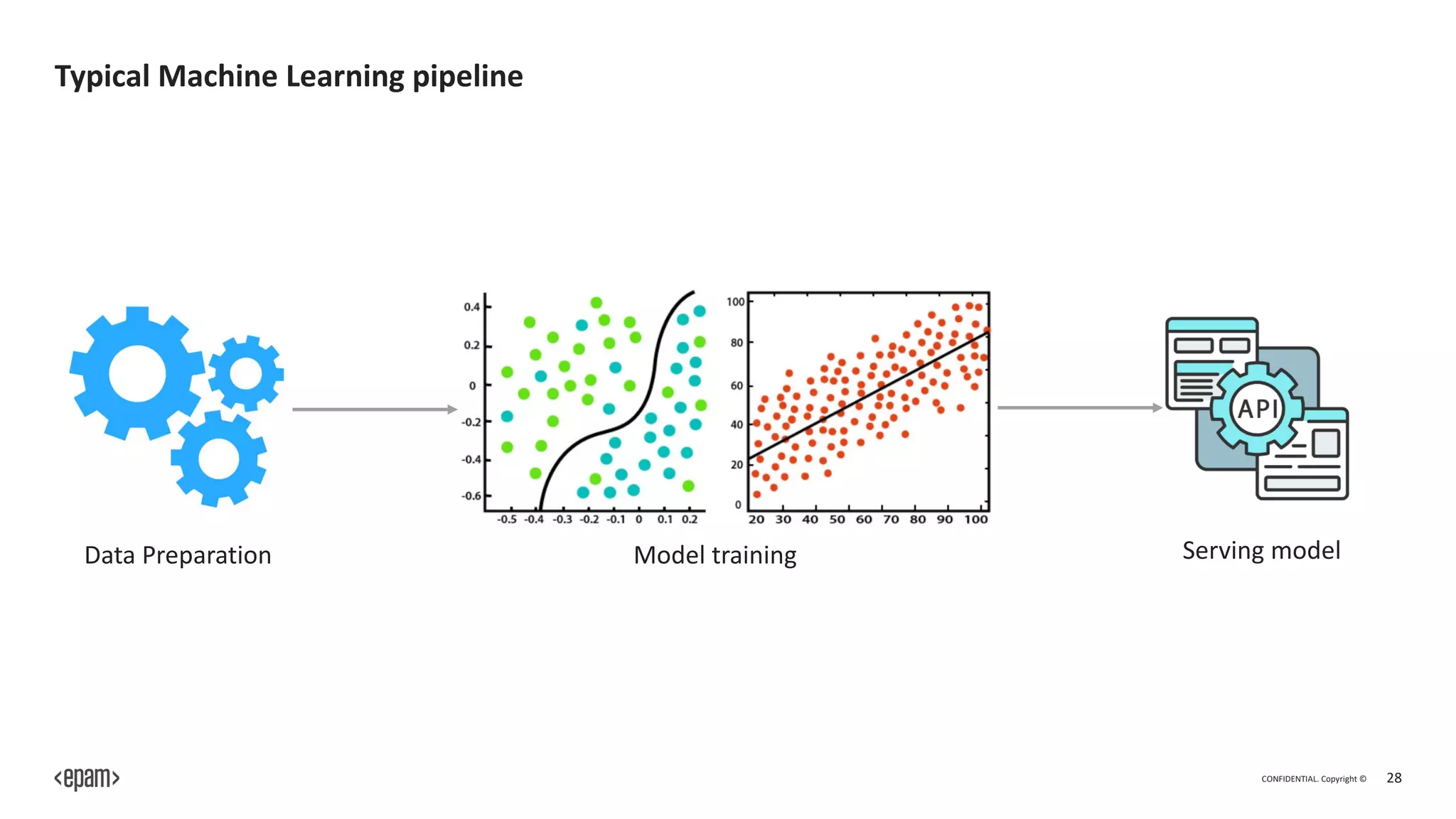
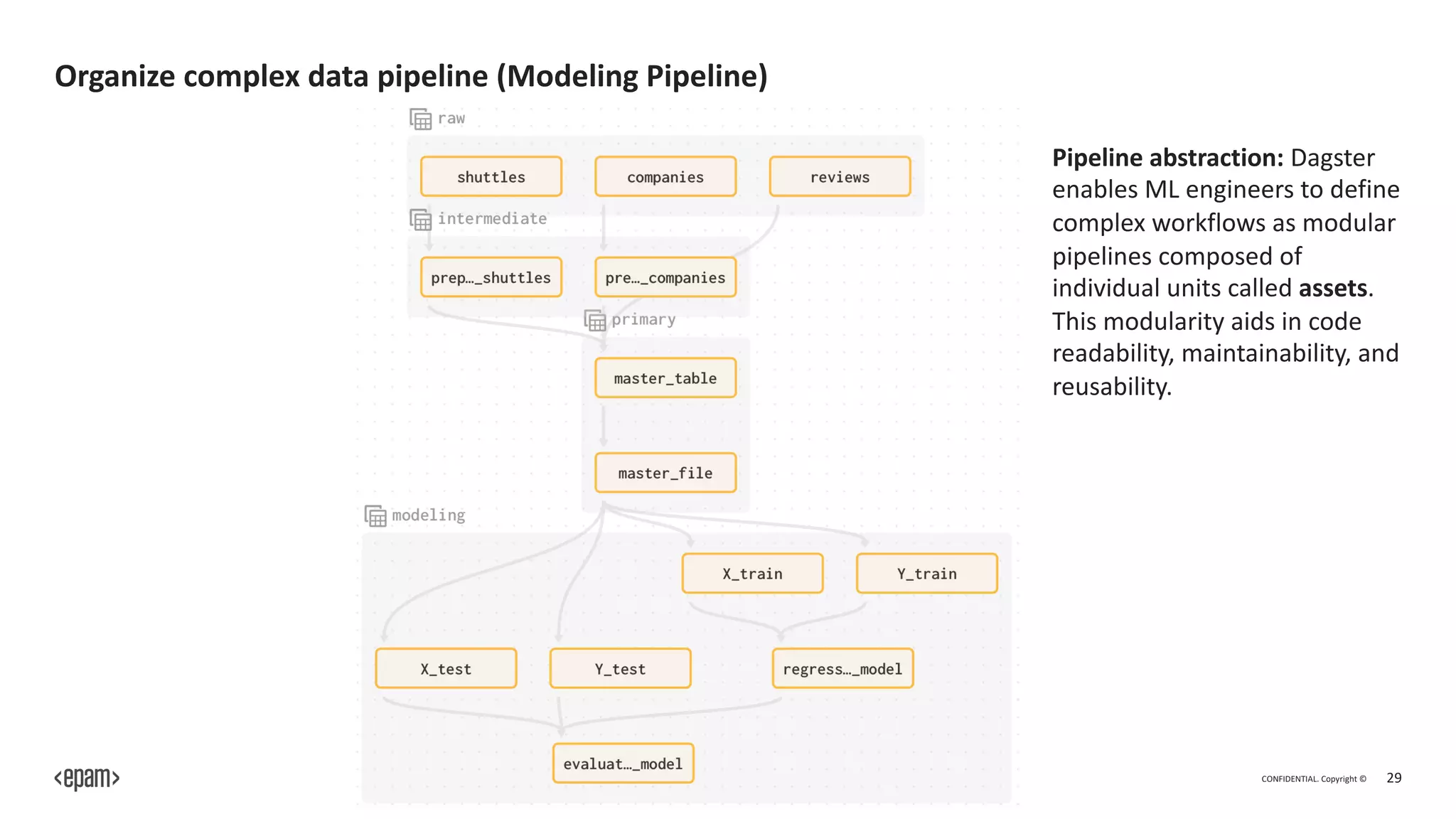
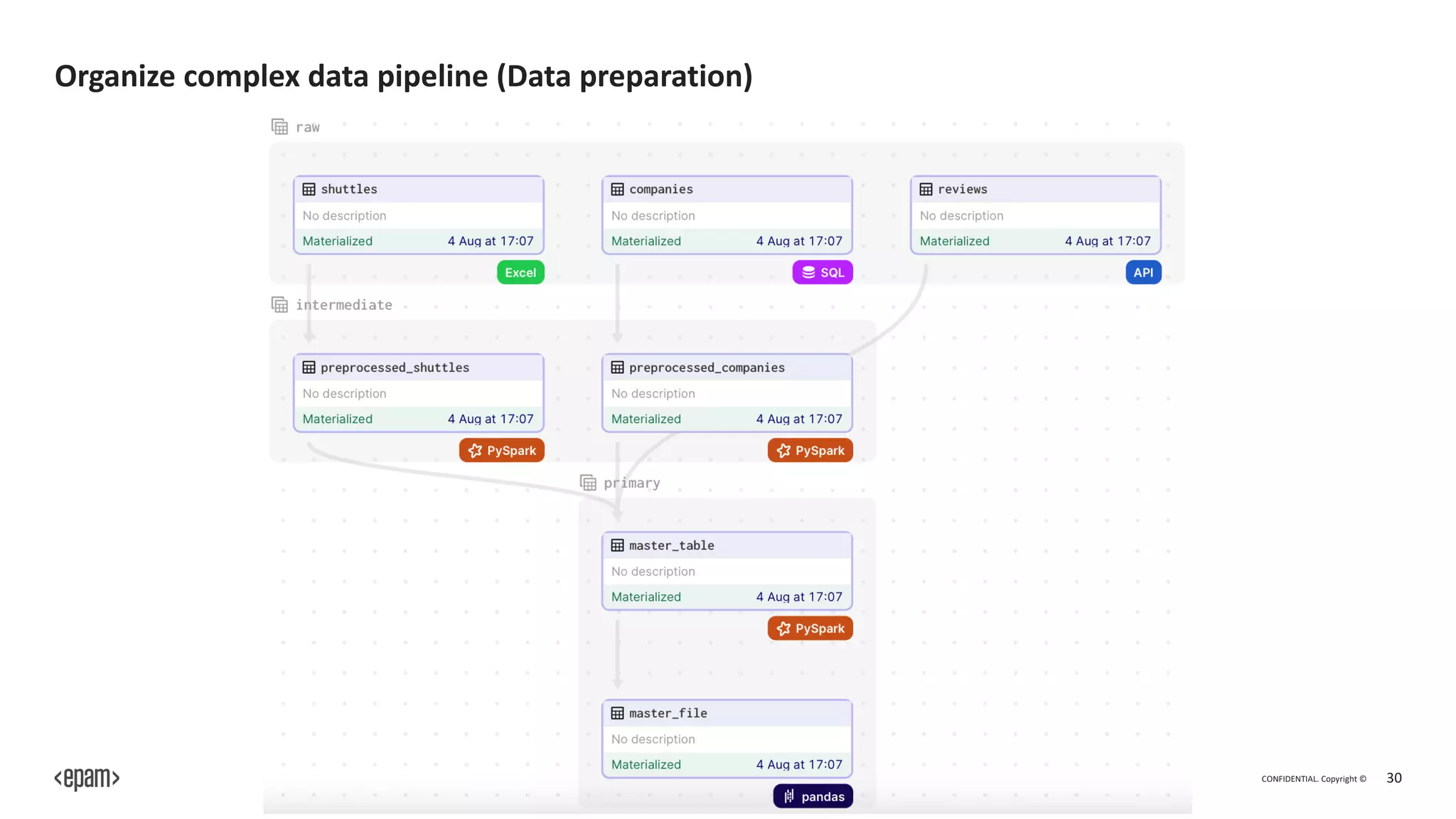
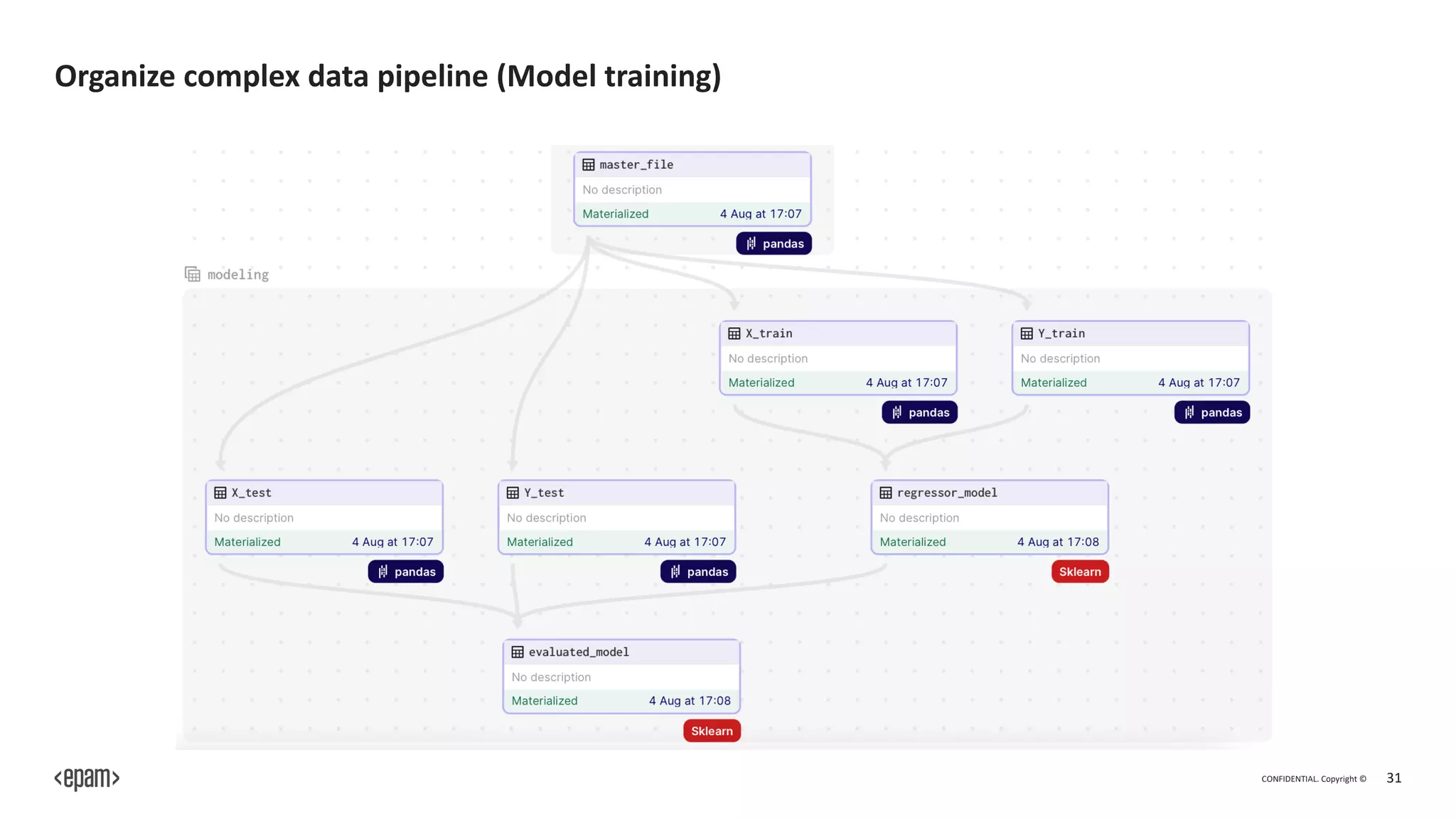
The document outlines Dagster, an open-source library for building ETL and machine learning systems, emphasizing its modular architecture, integration capabilities, and benefits for managing complex data pipelines. It presents features like orchestration, monitoring, and error handling, which facilitate the orchestration and execution of data workflows, as well as debugging and testing tools for machine learning engineers. The document also discusses the community support and extensibility of Dagster, along with its advantages and disadvantages.























































![[DSC Europe 25] Goran Obradovic - The Rise of Sovereign AI: Building the Regi...](https://cdn.slidesharecdn.com/ss_thumbnails/7nw2xxixrxqdxvrb5wca-6-251205085714-ab09a2ac-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)