17
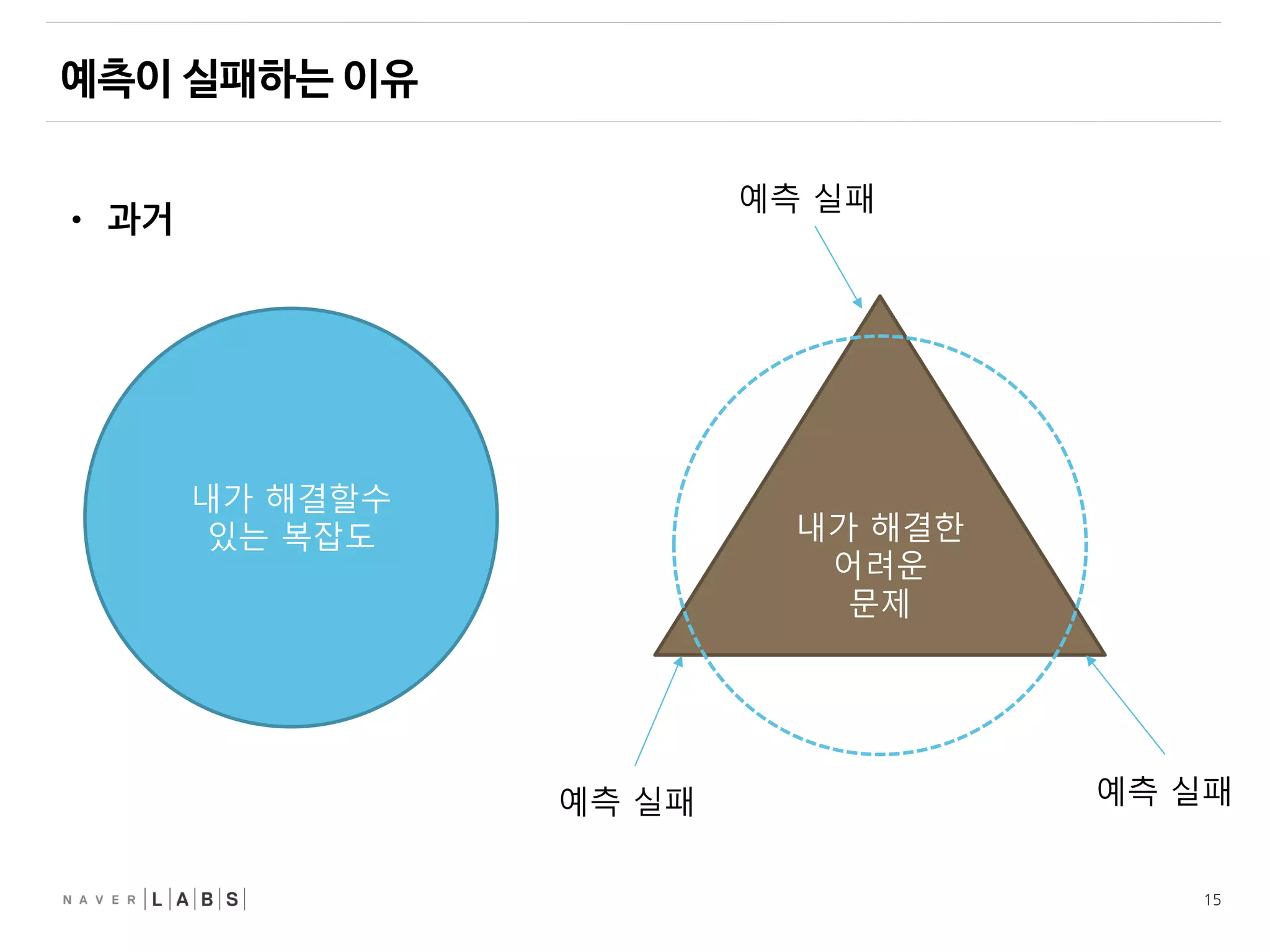
발생한 현상
• 설계실패
• 예측한 내용이 맞지 않는 빈도가 대폭 상승.
• 예측의 정확도가 낮아짐.
• 방안 A : 정확도 35%
• 방안 B : 정확도 30%
• A, B말고 다른 방안을 더 찾아낸다. : 30%
• 확신이 들지 않음
• 정확도가 낮으니 어떤 선택이 최적인지 모르겠음.
• 그냥 어떻게 해야 될지 모르겠음.
19
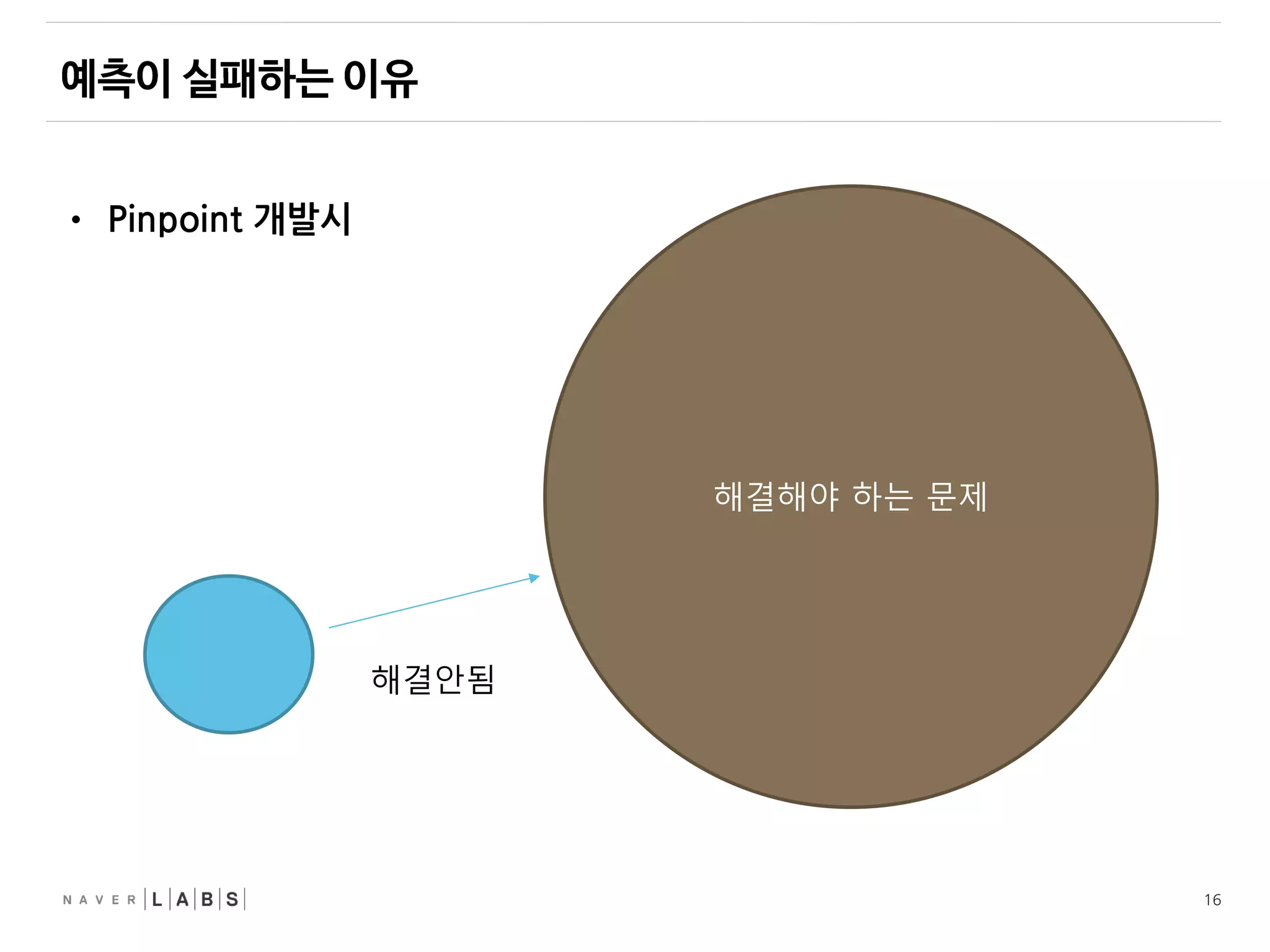
• 택도 없음.
•좀 더 많이 생각하고 신중하게 접근했으나 별반 차이 없음
• 사람의 인지 능력에는 한계가 있음.
• 이걸 갑자기 극단적으로 키우는것은 불가능.
• 사람이 처리할수 있는 복잡도에는 한계가 있다.
• 이 방법으로 안될것을 실감.
• 극소수의 선택받은 자는 할수 있을지도 모름.
중요한 점 : 내가 선택받은 자가 아님
20.
20
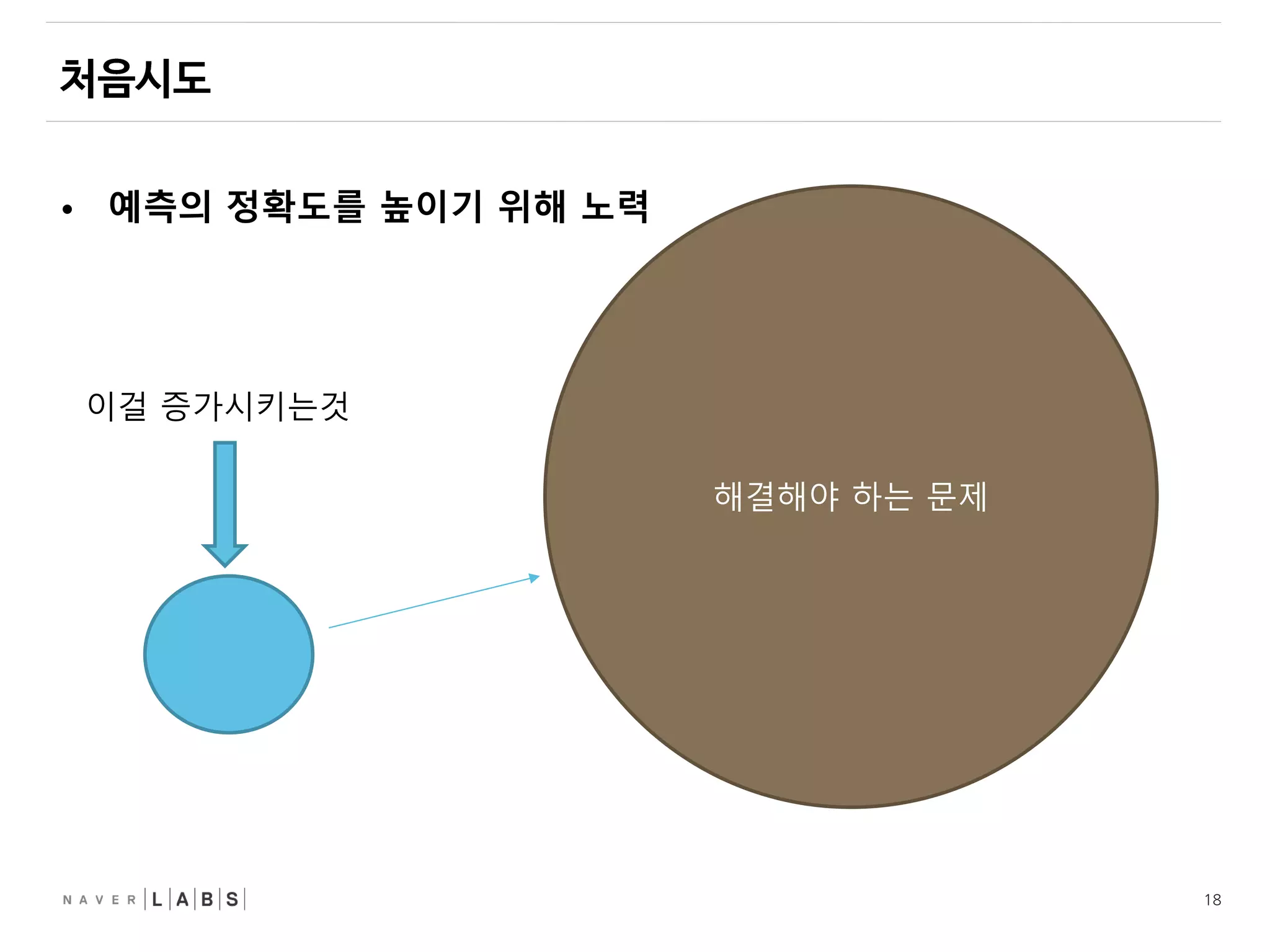
• 실패가 아니고시행착오
• 시행착오는 이제 설계의 일부.
• 내 능력에는 한계가 있기 때문에, 필연적으로 발생함.
• 조금만 실패하고, 실패시의 비용을 낮추야 한다.
• 틀릴것을 가정하고 일을 진행한다.
• 내가 감당할 수 있는 부분만 예측
• 가까운 미래만 예측한다.
• 먼 미래를 예측 할수록 정확도가 떨어짐.
21.
21
• 완벽한 코드X
• 변경에 유연하게 대처할 수 있는 코드
• 연관성있는 코드와 자료구조를 집약
변경이 필요할때 리팩토링을 할수 있는 코드면 충분히 멋지다.
• 변경 비용이 100이 들었을때, 30만 들게 해도 충분하다.
• Interface의 구현체를 변경하면 돌아가는것이 반드시 필요한것은 아님.
• 단순(Simple)해야 함
• 변경을 빠르게 하려면 단순해야 함
• 핵심이 아닌 기능 추가는 뒤로 미름
• 문제의 핵심을 완전하게 이해할때까지
• 판단에 확신이 들때까지
• 방법을 찾기 위해 개발을 시도
22.
22
• 실패하는 것은자체는 문제가 아님
• 올바로 작동하지 않는다고 걱정하지 마라.
만일 모든 게 잘 된다면, 굳이 당신이 일할 이유가 없다
(Mosher’s Law of Software Engineering)
https://subokim.wordpress.com/2015/03/12/101-great-computer-programming-quotes
• 문제를 해결하지 못하는것이 문제
• 완벽한 해결책이 필요한 것도 아니다.
• 문제가 100생겼는데. 개선해서 30만 발생해도 충분히 멋지다.
23.
23
• Java Agent를어떻게 만들되는지?
• 해당 도메인의 직접적인 경험이 없다.
• 레퍼런스도 부족 : 간접경험
• 지금도 가장 어려운 부분
• 설계를 어떻게 해야 될지 잘모르겠음.
• Class를 어떻게 잡아야 되는지?
• 특정 기능을 구현하기 위해 뭐가 필요하지?
• 어설프게 머리로 생각하니깐 실패확율이 높다.
• 문제 자체를 관찰하고 원리를 이해하는게 중요함.
• Pinpoint의 API트레이스는 JAVA스택머신의 동작을 흉내낸것에 지나지 않음.
• 모르는 상태에서 대단한걸 만들려고 하면 대단한 실패를 한다.
24.
24
• 문제 해결을위한 도메인 모델은 우리가 만드는 것이 아니라 발견하는
것이다
• 도메인 모델 자체는 우리의 인식의 경계선에서 관찰하고 인지하여 그것
을 언어로 표현하는 것이므로 우리는 이러한 반복적인 탐구 과정을 통
해 모델을 정제해 나가는 것으로서 보다 정확한 모델을 얻는 것이 가능
해 진다.
• 이러한 이유로 처음부터 완벽한 모델을 얻기는 쉽지 않다. 여기서 발상
의 전환이 필요해진다. 처음 얻어지는 모델은 틀린 것일 수 있다는 가정
하에 일을 진행 시키는 것 이다.
문제 영역에 대한 올바른 이해
http://www.moreagile.net/2014/12/1.html
25.
25
• DDD에서 중요하다고한것을 상당수하지 않았다.
• JAVA 개발자
• 성능 분석 & 트러블슈팅업무 수행
• Network 라이브러리 개발 등을 개발
• Java Framework 패치 등등
• HBase는 Oracle동작 원리를 통해 간접이해
• Distributed Trace 도메인은 Dapper 문서 간접이해
• Pinpoint개발에 필요한 도메인 지식이 이미 있었음.
• 부족한 부분은 APM 도메인으로 한정
• 불편함을 느껴서 개선하고 싶은 분야의 고도화, 자동화를 추진하
면 복잡도를 내릴 수 있다.
26.
26
• 복잡도가 높고아는게 없는 신규 프로젝트
• 핵심 기능 & 가능성을 조사하고 안될거 같으면 포기하자
• 안하는게 방법일수도 있고, 다른 사람이 할수도 있다.
• Fail Fast
• 최초 개발 시도시
• 성공확율 -> 성공 3 : 실패 7
27.
27
• 진짜 만들어낼수 있는지 검증작업에 들어감.
• Bytecode Instrumentaion을 구현해 낼수 있나
• Google Dapper를 보고 Distributed Transaction Trace를 구현해 낼수 있나
• 안될거 같으면 빠르게 버릴려고 했는데
• 하나보니 됬다.
• 사실 계속 구현에 문제가 발생해서 엄청 긴장 많이했음.
• 다음부터 이런거 만들지 말아야지
31
• 극도로 기능을제한
• 제품개발의 성공에 크게 관여하지 않는 핵심이 아니라고 판단되면 다 삭제
• Ex : 알람 (중요한데 기능인데 안만들었네요. 꼭만들겠습니다.)
• 시간은 항상 모자름. 문제 도메인은 내생각보다 훨씬 어렵다.
• 개발이 가능한지 확인을 하기 위한 시간을 최대한 확보
• 적은 인원으로 시작
• 최초 2명
• 실패하면 회사입장에서는 다 $낭비
32.
32
• 시간 &리소스는 항상 부족하다.
• 개발의 성공가능성을 판가름하는 핵심 기능에 중점을 둬야 한다.
• 어디서 시간을 벌어야 하는가?
• 제일 만만한건 기능
• 품질 : 이걸 희생하는건 불가능.
• 돈&사람 : 내가 직접적으로 결정할 수 있는것이 아님.
• 일정 : 보통 변경이 힘드나, Pinpiont의 플랫폼 특성상 이것도 조정이 가능.
• 기능 몇 개 더 들어간다고 해서 성공하는게 아님
• 기능이 많으면 변경을 가하기 어려움.
33.
33
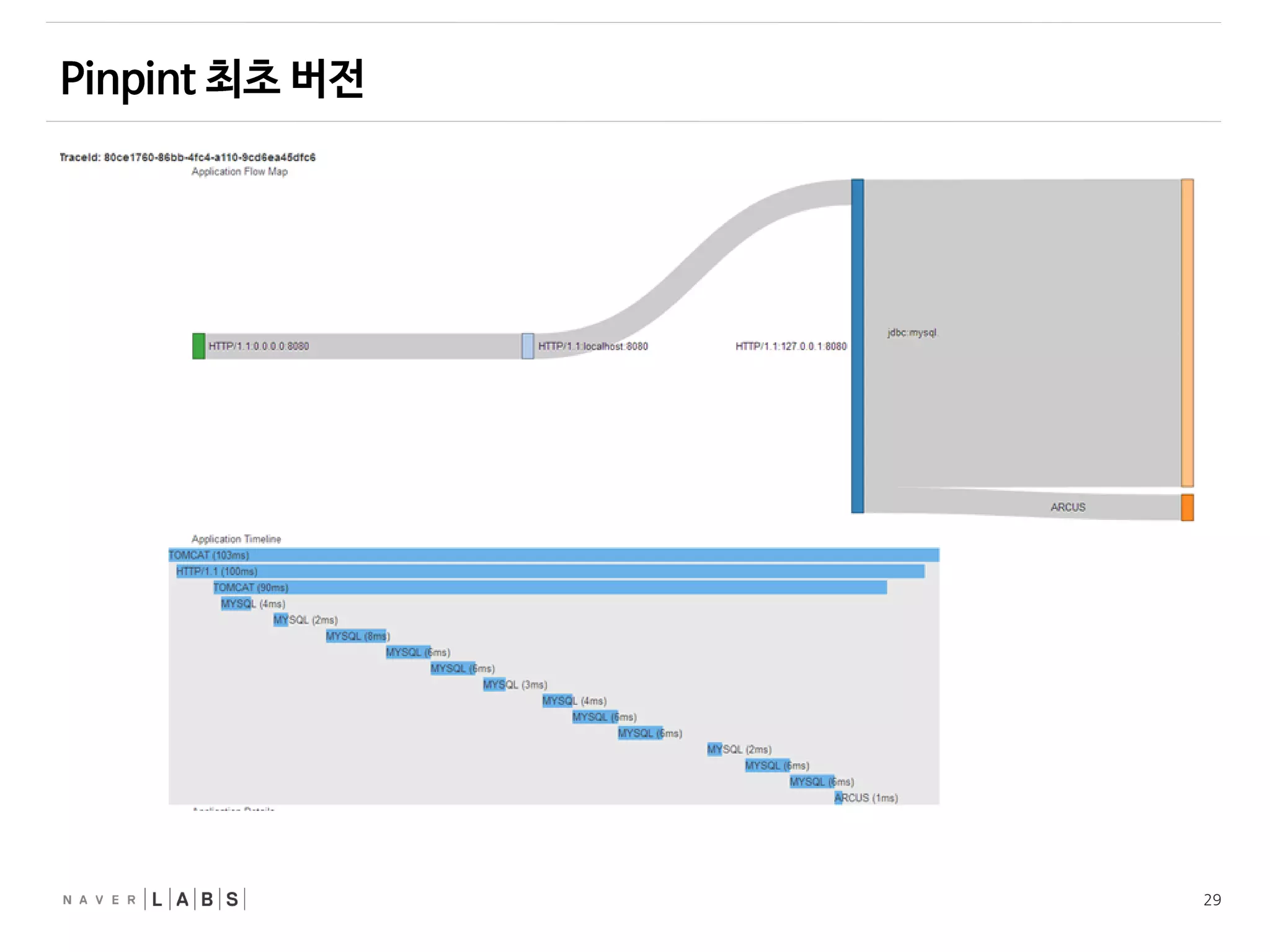
• Server MapSearch algorithm
Node A
Node B
Node C
Node D
Node F
Node E
Node G
탐색시작 지점
34.
34
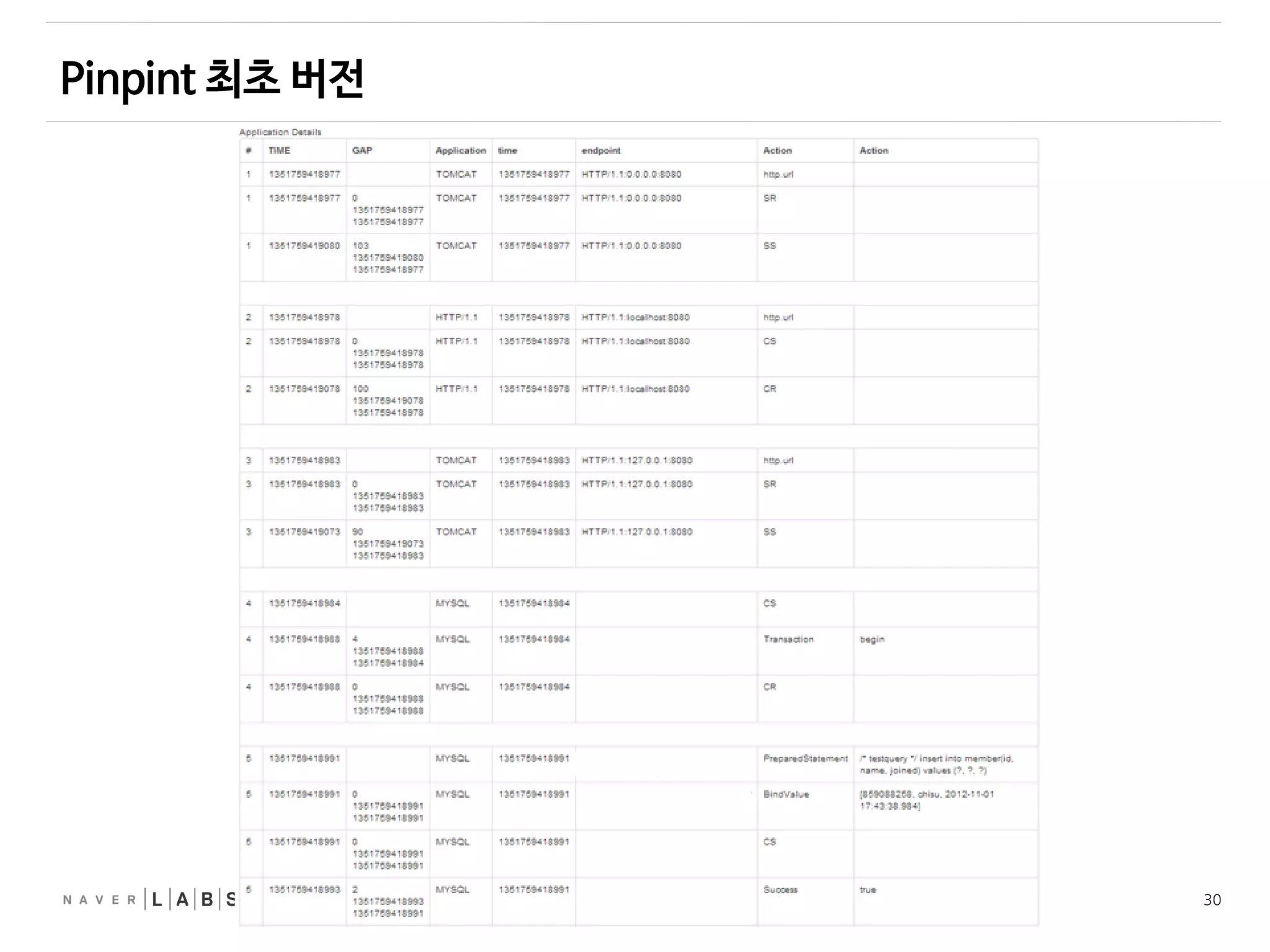
• Depth-fitst search(깊이우선탐색)
Node A
Node B
Node C
Node D
Node F
Node E
1
2
3
4
5
Node G
6
탐색시작 지점
35.
35
• Pinpoint를 사용하는서비스가 증가하면서
• 무제한으로 연관 노드를 탐색하니 조회속도가 느리고,
• 조회 노드가 많을 경우 OOM도 발생
• ServerMap이 너무 복잡해짐.
40
• 방안 강구
•이미 방문한 노드를 마크하는곳에 추가적인 탐색 깊이가 남겨두
고 더 탐색하게 할까?
• 점프 Table같은게 있어야 하나?
• 다른 경로를 따라서 추가적 루트가 있다면, 예외가 생기나?
• 이상하게 난이도 급격하게 상승함.
• 잘못된것 같아 다시 검토
41.
41
• 잘못된 탐색알고리즘을 선택
• 개발 당시에는 선택을 잘못했다는 것 자체를 인지하지 못했음.
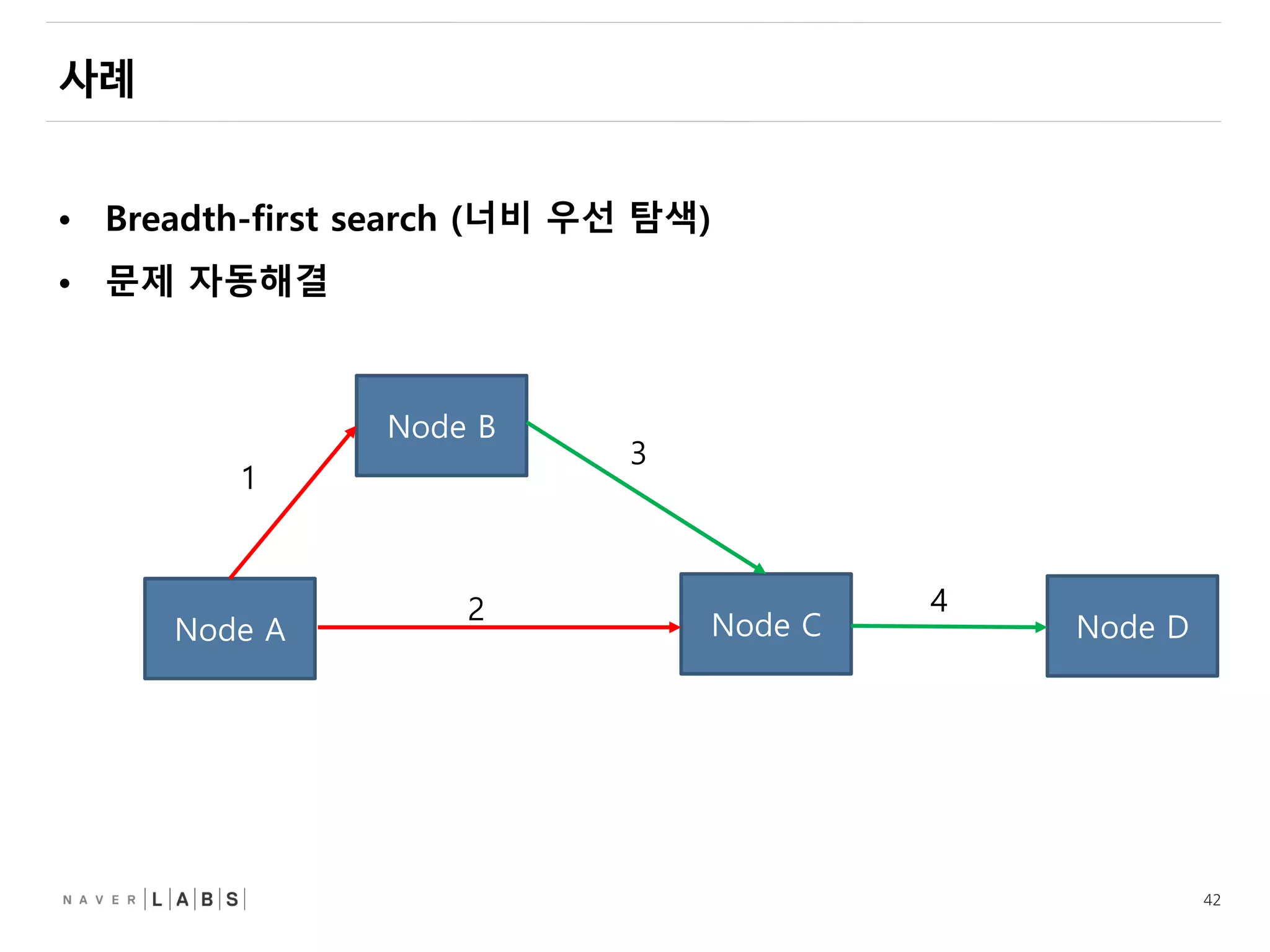
• Depth-fitst search 폐기
• Breadth-first search 로 변경.
• 탐색 로직이 별도 클래스로 분리되어 있었음
• 알고리즘 변경시 추가로 구현해야 기능이 없었다.
• 빠르게 변경가능
43
• 핵심선택에 의해서성능의 상당 부분은 이미 결정
• 샘플링
• Bytecode Instrumentation
• HBase 선택
• 나머지 선택은 부수적
• Binary 프로토콜
• UDP
• 비동기 처리
• 나머지 선택은 IO 부하를 줄이기 위한 기능
44.
44
• 하드웨어에서 CPU가과연 비싼자원인가?
• CPU도 램과 같이 싼자원이 되고있는것 같다.
• 8~9년전에는 고가의 HP Superdom이 24~32 core
• 200~300만원 짜리 표준 웹서버가 24 core
• IO작업은 CPU작업보다 더 비싸고 느리다.
• HBase 리전 서버 : CPU가 하는 일이 없음.
• Snappy 같은 압축 모듈은 반드시 사용하는게 좋다.
• 압축율 5:1 ~ 8:1
45.
45
• 오토 샤딩
•서버를 꼽기만 하면 용량이 늘어나게 하고 싶었음.
• Write-intensive workload
• RDB의 약점
• Read 성능은 캐시등으로 극복방법이 있으나, Write 성능은 마땅한 방법이 없다.
• Google Dapper 데이터 모델을 그대로 채용하기 위해
• Hadoop 패밀리들과의 연동
• 나중에 기능을 더 추가할수 있을것 같다.
• 운영&모니터링 툴이 좋음
• Cloudera 좋긴한데, 자체 버그도 있으니 주의
• CDH 5.4, 5.4.1 zkCli.sh 가 동작하지 않아 자체 패치.
• https://github.com/Xylus/zookeeper
46.
46
• SAAS 형태로서비스가 가능
• 사용자는 Agent만 다운로드하면 되니 편하다.
• 모니터링을 위해서 서버를 설치해야 되면 귀찮다.
47.
47
HBase 때문에 잃어버린가치
• SQL
• 기능이 정말 없다.
• 복잡한 조회로 기능은 그냥 안된다고 보면됨.
• DBA
• 서포트 조직을 잃어 버림.
• 전문가에서 요청하고 DB를 내가 다 알지 않아도 됬는데.
• 이제 개발팀이 다해야 됨. 이게 다 부하.
• RBD보다 검증, 경험도 부족
• 모르는게 많아서 운영하기 어렵다.
• 오래된 CDH 4.7.x 버전을 사용하니 버그가 많음
• HBASE 9.4.x 리전 서버 버그로 장애. HBASE-7711
• Hadoop 무한 루프. HDFS-5225
• 얼마전 HBase 1.0 업그레이드
48.
48
• 모니터링 시스템인데.Eventually consistency로 보이면 이상할
것 같다.
• Hadoop 패밀리쪽이 향후 기능을 더 추가할때 유리하다고 판단
• 모니터링&운영 툴이 부족한듯하다.
• 안될 건 없다.
49.
49
HBase 추천?
• NoSQL은만능이 아니다.
• Application의 저장소는 선택은 핵심 결정사항.
• 이 선택을 실패하는것은 치명적
• Application에 적합한지 신중히 생각해서 결정
• Pinpoint를 통해 간접경험해보고 결정.
• Pinpoint를 설치해서 운영해보고 판단해보는것도 방법이지 않을까?
• HBase도 개발실패시에 대한 보험중 하나였음.
• Hadoop, HBase의 사용이 증가하면서, 지원에 대한 수요가 자동으로 발생하고 있음.
• 이것만 잘해도 먹고 살수 있을지도 모름.
50.
50
기술 습득시 집중해야될부분
• 신기술에 관심을 갖는것은 좋다.
• 너무 유행만 따르지 말고 실제 가치가 있는지? 신중히 판단하자.
• 유행하는 기술에 시간+리소스를 투자했다가 망하면? 이게 다 낭비
• 기술에 대한 근본원리를 틈틈히 살펴보자.
• 자신이 사용하지 않는 코드를 보면 보면 어렵기만 하고 재미도 없다.
• 실제 사용하는 프레임워크, 라이브러의 코드를 보자.
• 특정기술은 죽어도 근본 원리는 안죽는다.
• 유행을 타는 기술의 경우 유행이 지났을 경우 감가상각이 매우 심하다.
• 근본 원리는 감가상각이 잘되지 않는다.
• 감가상각이 잘안되기 때문에, 누적치가 생긴다.
• HBase 를 살펴볼때 : RBD의 근본 원리에 빗대서 차이점을 살펴보면 금방.
• JDBC Driver 트러블슈팅 : Network lib와 별반 차이가 없다. 그냥 빗대서 살펴보면 금방.
51.
51
읽어보면 재미있는 링크
•근본적인 내용은 다 비슷하다.
• 내가 그렇게 못하는 것이 문제
• 소프트웨어 개발의 본질 (The Nature of Software Development)
• http://kwangshin.pe.kr/blog/2015/03/04/the-nature-of-software-development/
• SW 종사자들을 위한, 아주 작은 기여 하나
• http://blog.gorekun.com/?p=1623
• 개발자는 왜 야근을 해서 소중한 시간을 버리는가?
• http://okky.kr/article/279511














































![[D2] java 애플리케이션 트러블 슈팅 사례 & pinpoint](https://cdn.slidesharecdn.com/ss_thumbnails/d2javapinpoint-150522091509-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


![[164] pinpoint](https://cdn.slidesharecdn.com/ss_thumbnails/164pinpoint-150914054628-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)








![[211] HBase 기반 검색 데이터 저장소 (공개용)](https://cdn.slidesharecdn.com/ss_thumbnails/211hbase-171016101436-thumbnail.jpg?width=640&height=640&fit=bounds)
![신입 개발자 생활백서 [개정판]](https://cdn.slidesharecdn.com/ss_thumbnails/random-170208062532-thumbnail.jpg?width=640&height=640&fit=bounds)



![[NDC17] Kubernetes로 개발서버 간단히 찍어내기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-170529041601-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenInfra Days Korea 2018] Day 1 - T4-7: "Ceph 스토리지, PaaS로 서비스 운영하기"](https://cdn.slidesharecdn.com/ss_thumbnails/47openinfradaykorea2018hyun-ha-180705032301-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC18] 야생의 땅 듀랑고의 데이터 엔지니어링 이야기: 로그 시스템 구축 경험 공유 (2부)](https://cdn.slidesharecdn.com/ss_thumbnails/ndc2018-2-180430180517-thumbnail.jpg?width=640&height=640&fit=bounds)









![[D2]thread dump 분석기법과 사례](https://cdn.slidesharecdn.com/ss_thumbnails/d2threaddump-150522063949-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)



![[D2CAMPUS] Dotuator - 능동형 촉감 전달 점자 디스플레이 (BARAM)](https://cdn.slidesharecdn.com/ss_thumbnails/baram-161005063008-thumbnail.jpg?width=640&height=640&fit=bounds)



![[D2 CAMPUS] 안드로이드 오픈소스 스터디자료 - OkHttp](https://cdn.slidesharecdn.com/ss_thumbnails/nexters6-okhttp-160927092147-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D2]java 성능에 대한 오해와 편견](https://cdn.slidesharecdn.com/ss_thumbnails/d2java-150522063126-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 CAMPUS] 안드로이드 오픈소스 스터디자료 - java OOM, Reference API](https://cdn.slidesharecdn.com/ss_thumbnails/nexters6-reference-160927092413-thumbnail.jpg?width=640&height=640&fit=bounds)

![[D2 CAMPUS] 안드로이드 오픈소스 스터디자료 - Http Request](https://cdn.slidesharecdn.com/ss_thumbnails/nexters3httprequest-160927090840-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D2 campus seminar]개발자가 꼭 알아야 할 보안이야기](https://cdn.slidesharecdn.com/ss_thumbnails/d2campusseminar-150227011654-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[2014년 5월 20일] 바이오 및 의료산업동향](https://cdn.slidesharecdn.com/ss_thumbnails/201357tv-150907021112-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)











![[오픈소스컨설팅]Session 6. scrum과 jira 기반의 소프트웨어 개발 프로세스](https://cdn.slidesharecdn.com/ss_thumbnails/session6-161124012853-thumbnail.jpg?width=640&height=640&fit=bounds)








![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)
![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)