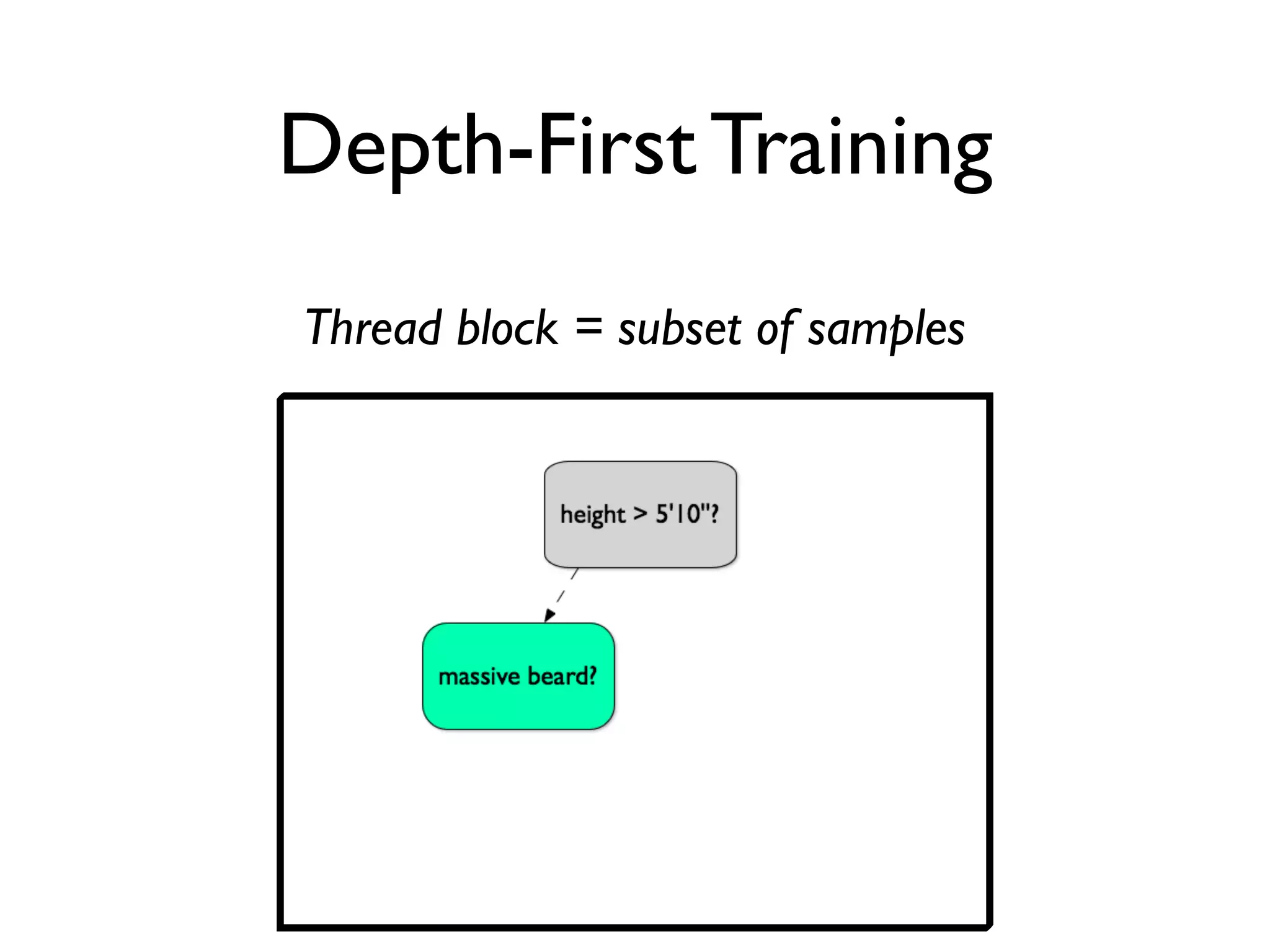
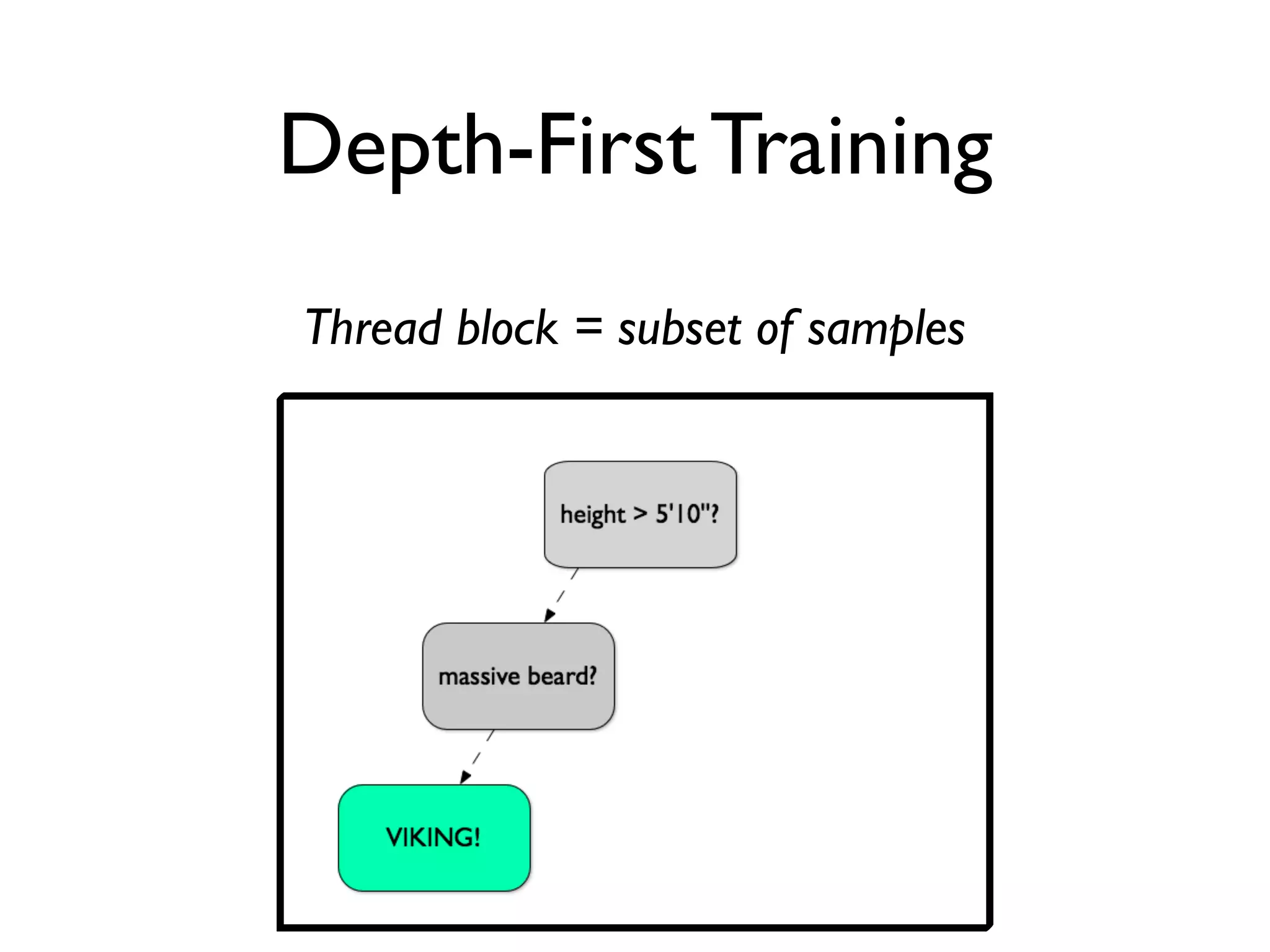
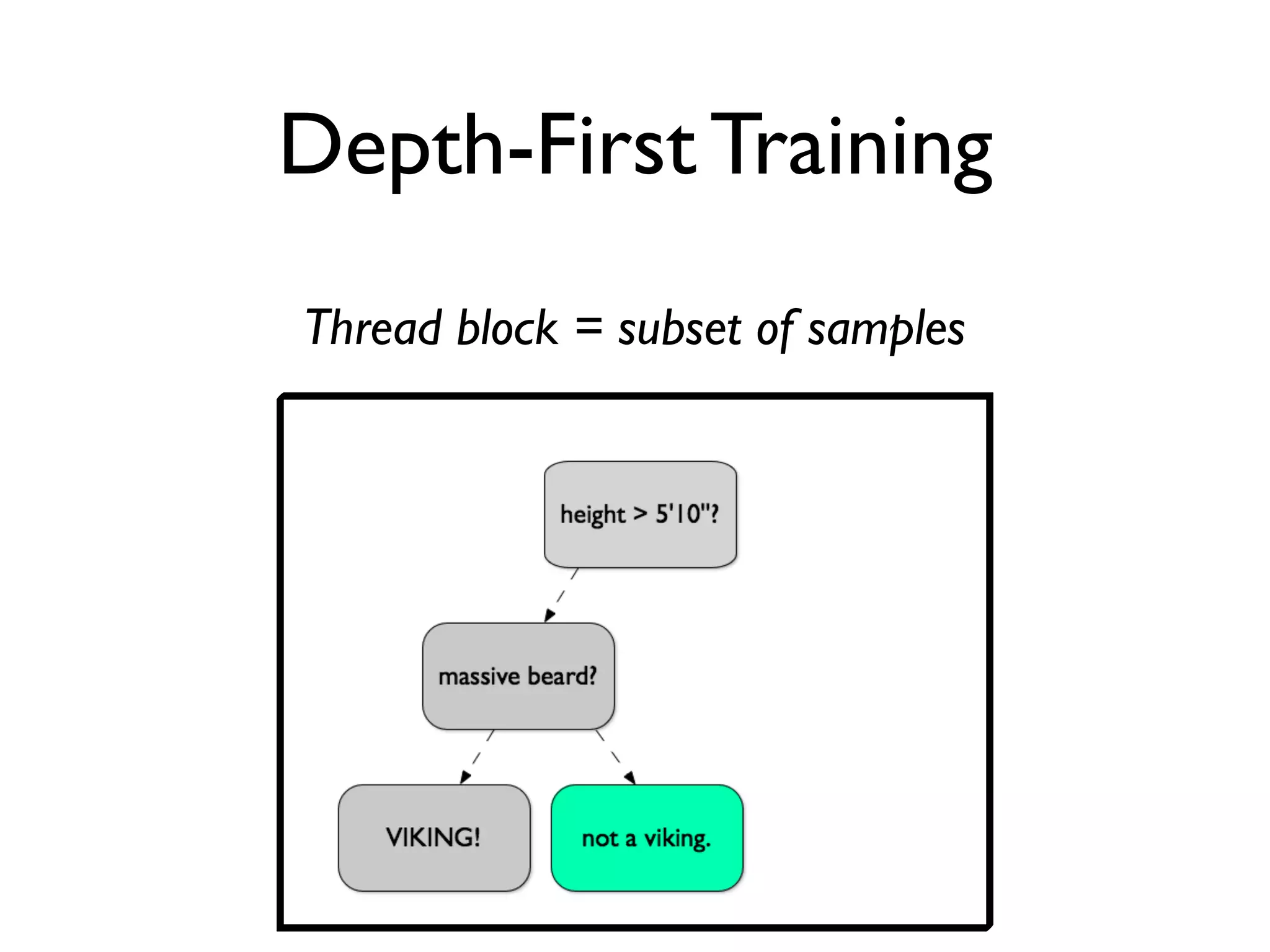
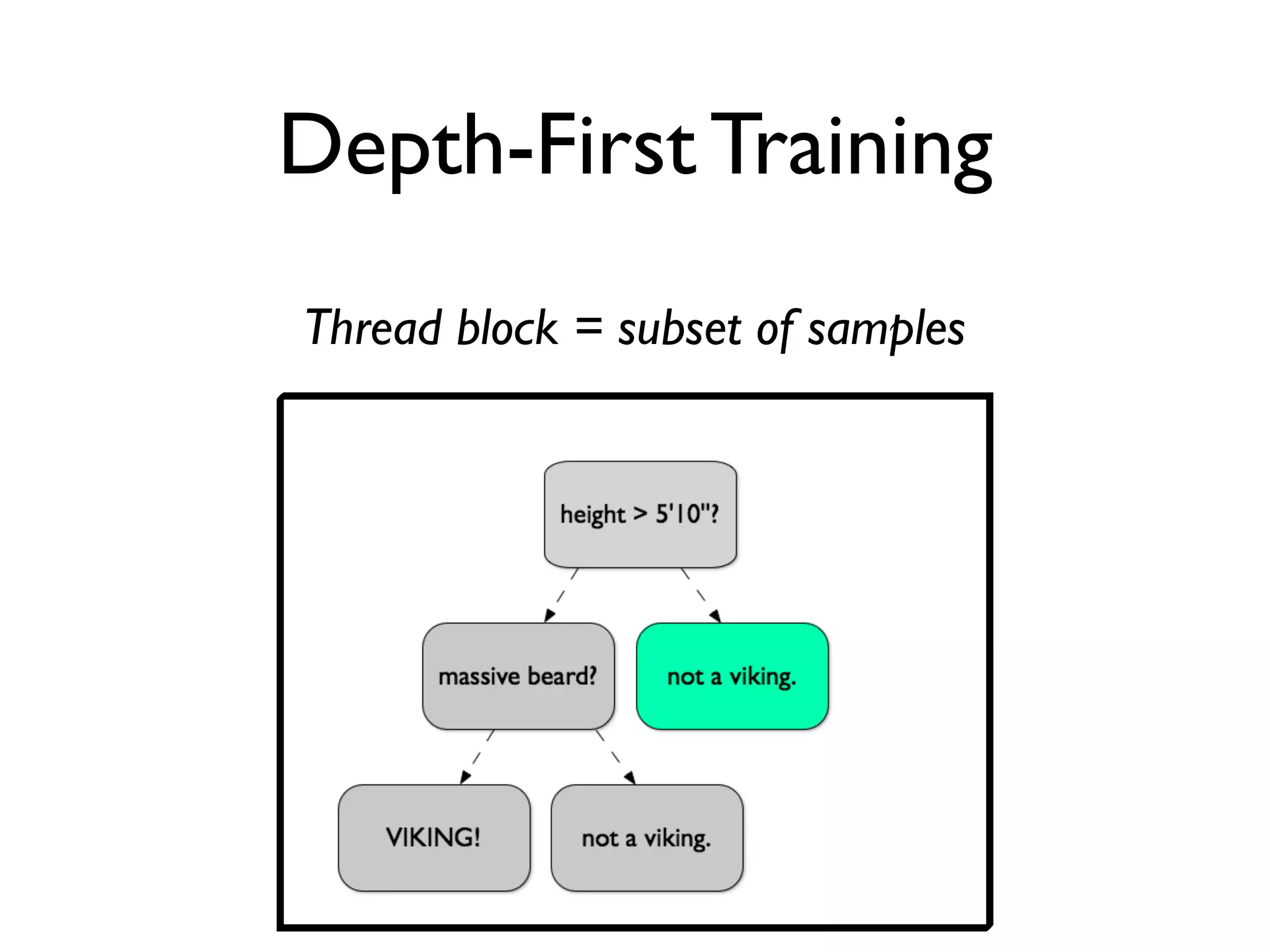
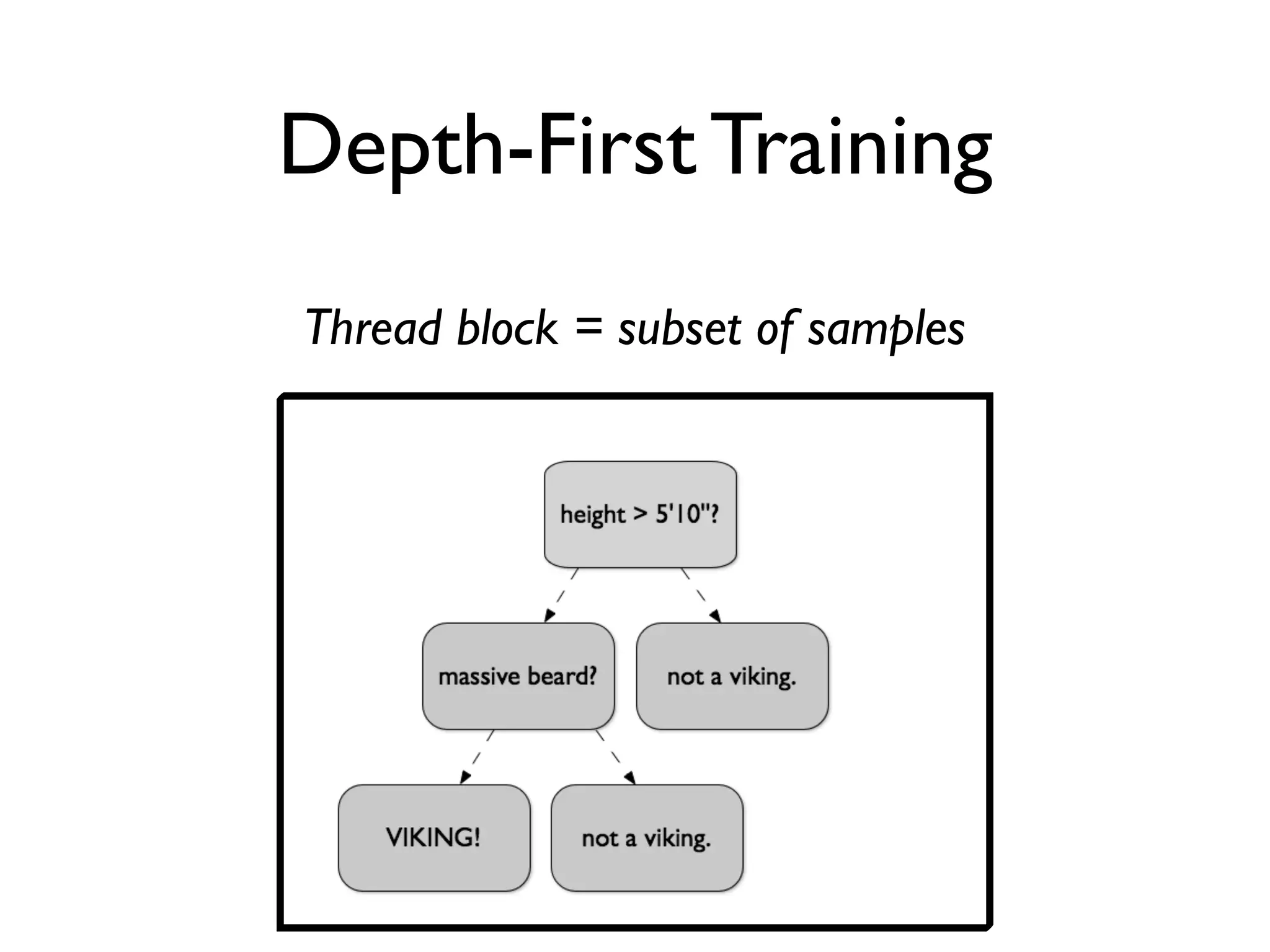
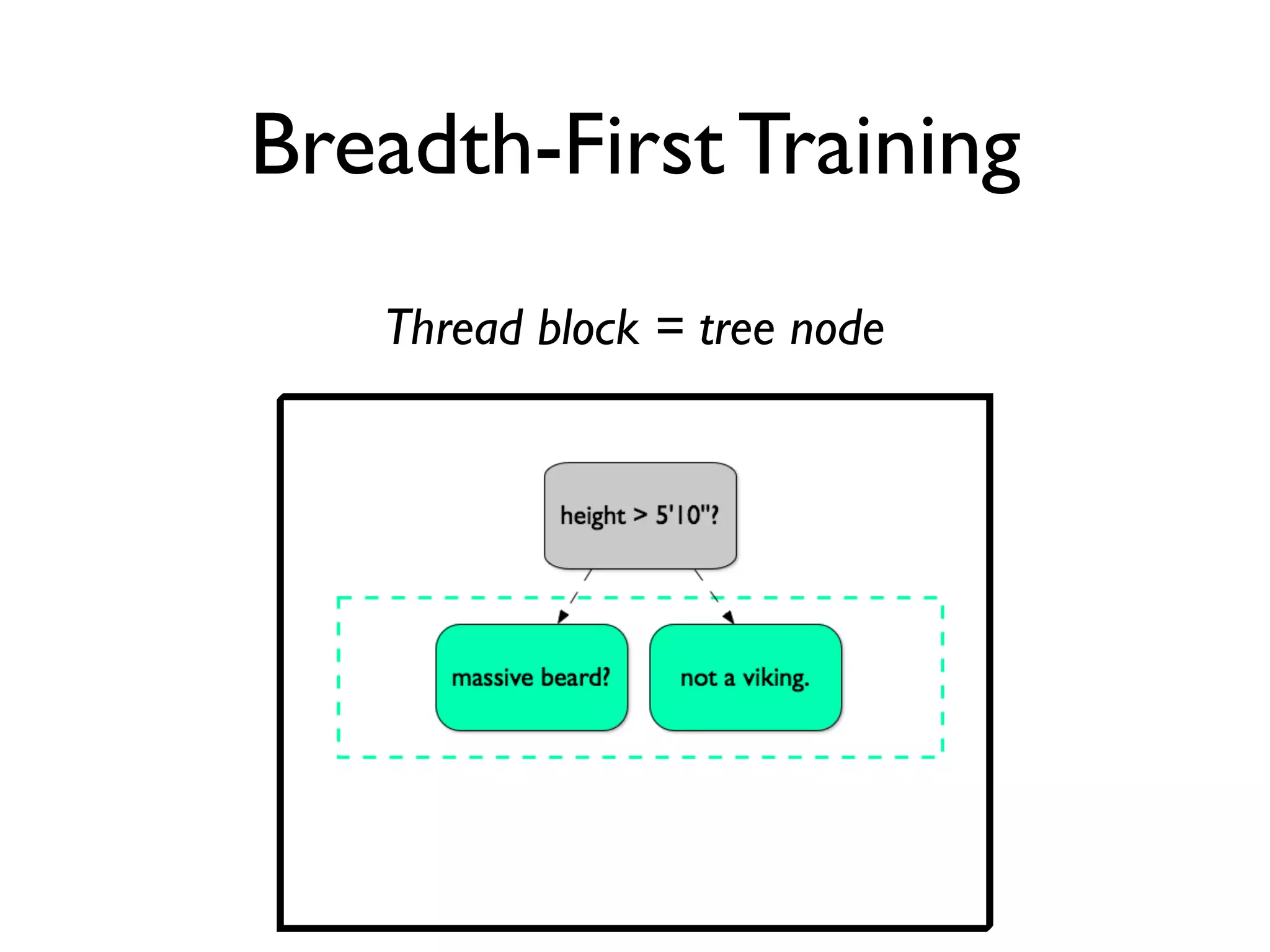
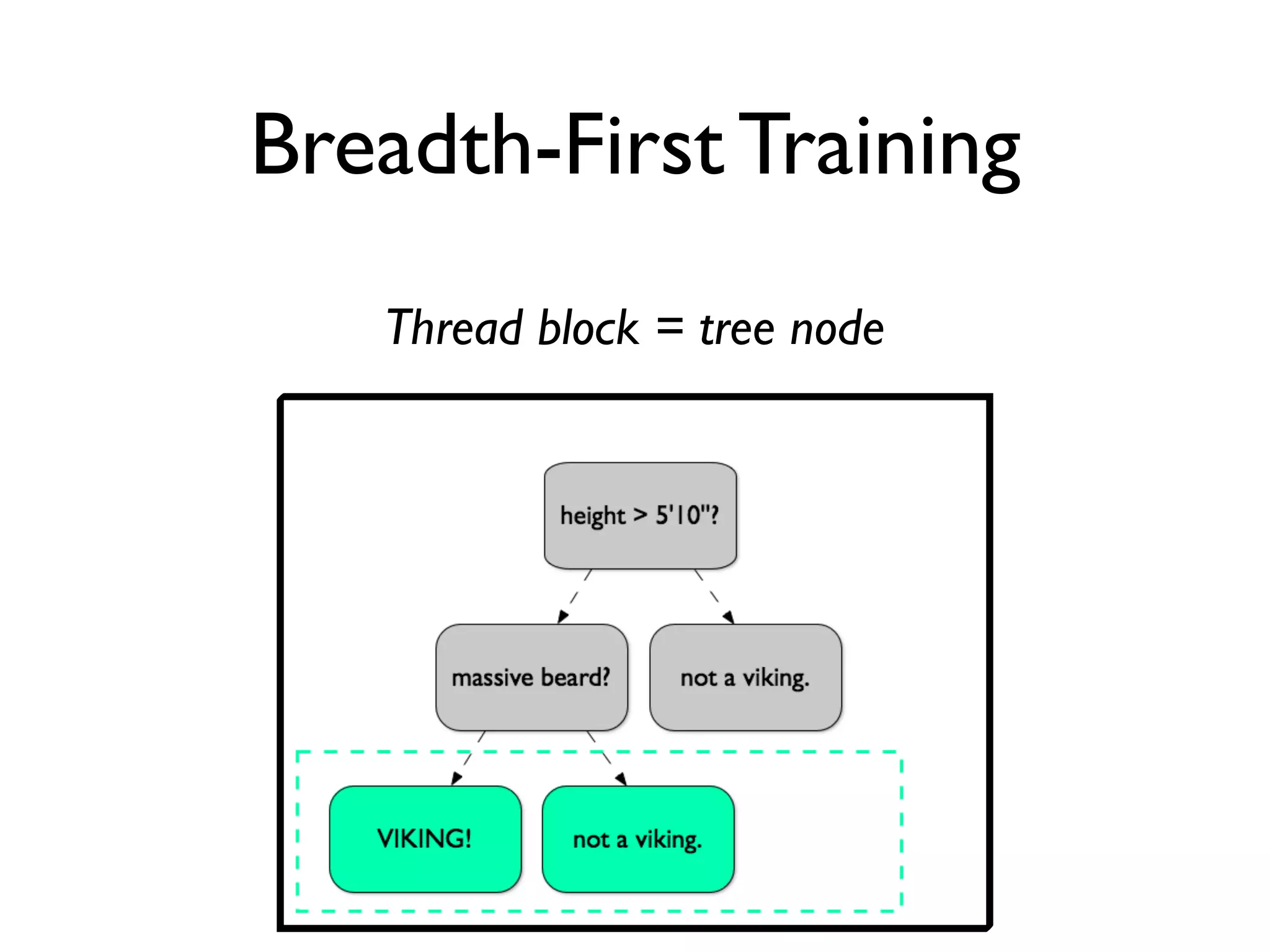
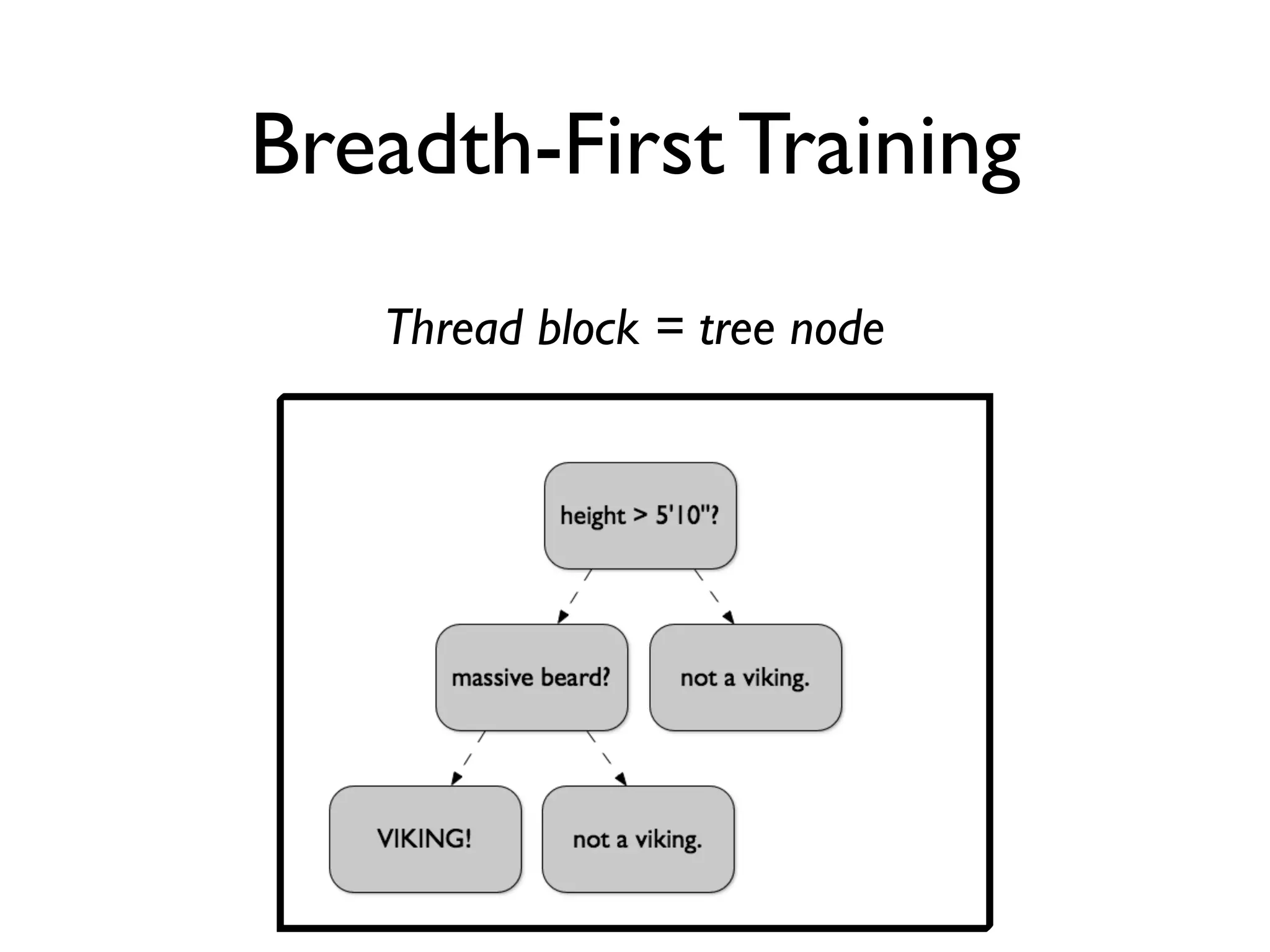
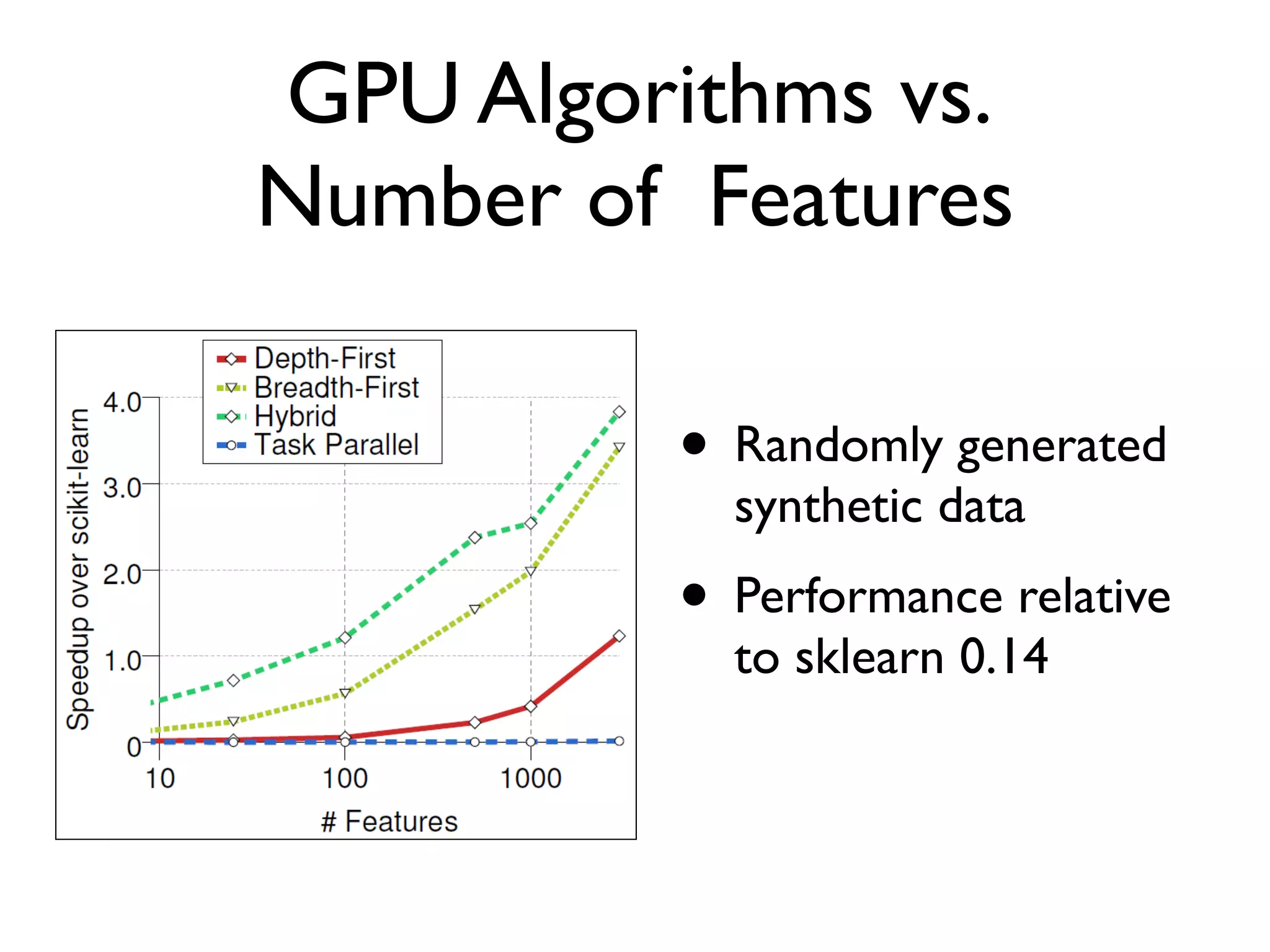
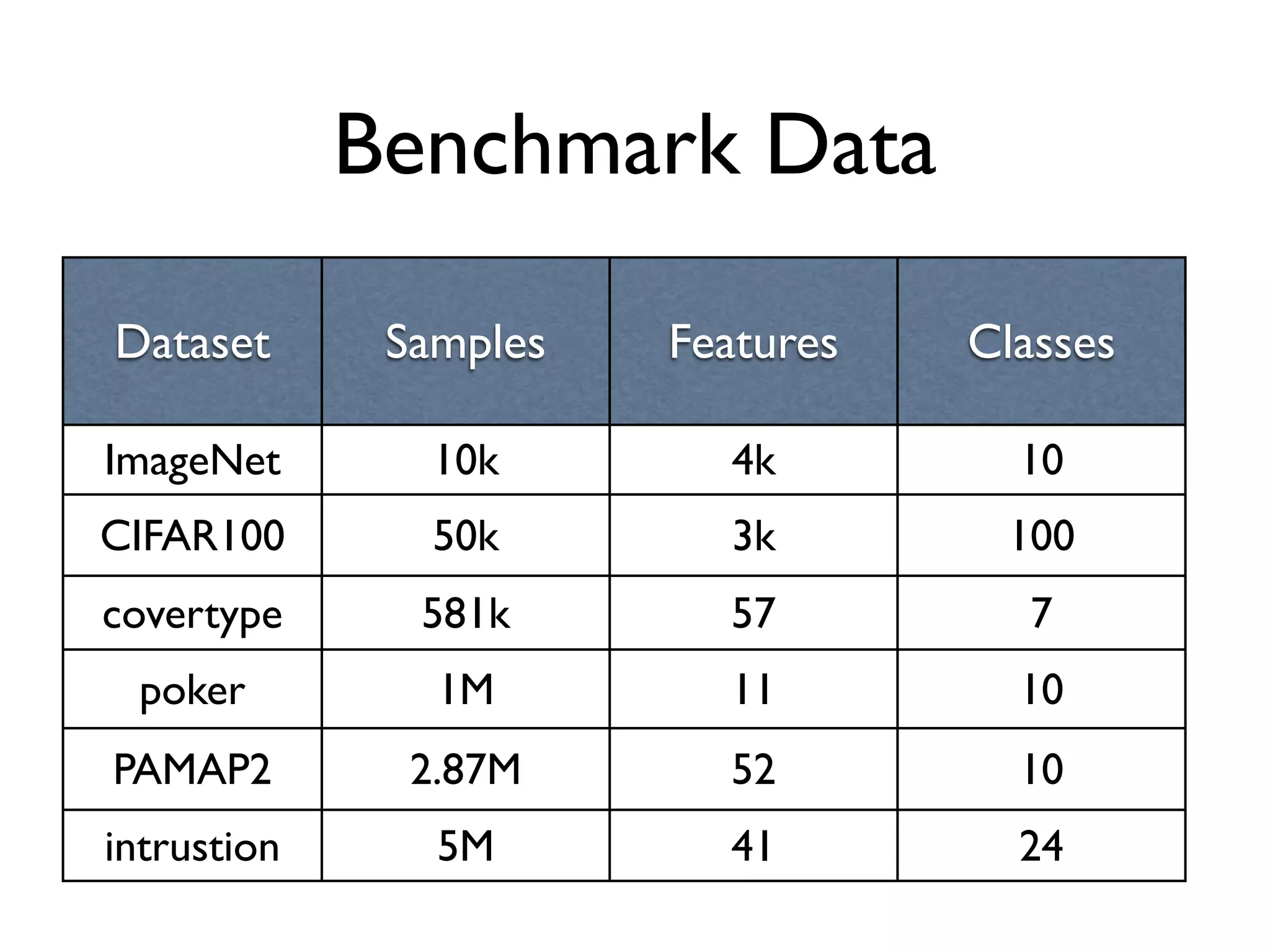
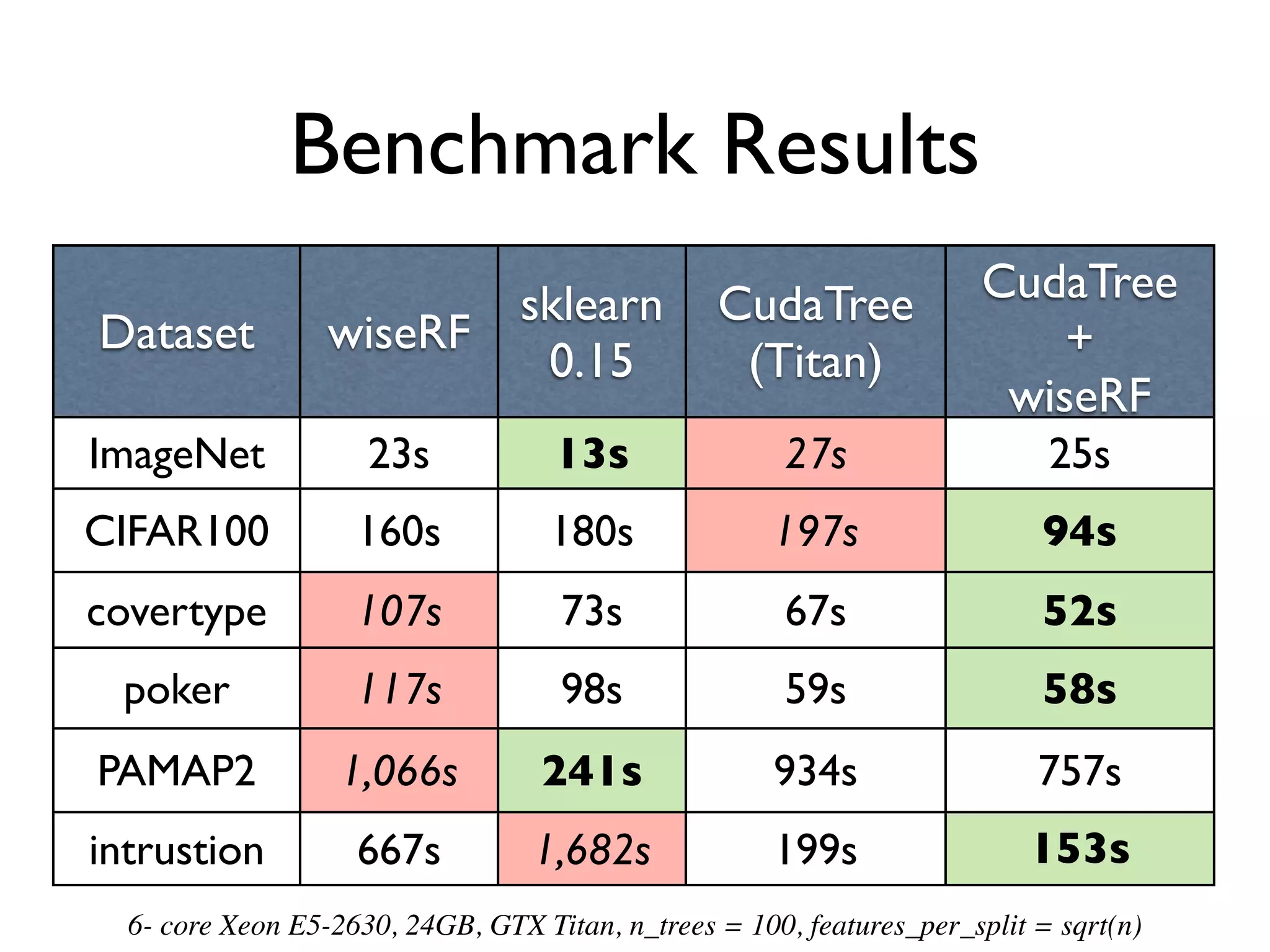
The document discusses the training of random forests on GPUs, highlighting the parallelization strategies for decision tree training, including depth-first and breadth-first approaches. It provides a comparative performance analysis of various GPU algorithms against the sklearn benchmark across multiple datasets. The summary also mentions the installation process for the cudatree library and credits contributors involved in the project's development.

![What’s a Random Forest?
trees = []
for i in 1 .. T:
Xi, Yi = random_sample(X, Y)
t = RandomizedDecisionTree()
t.fit(Xi,Yi)
trees.append(t)
A bagged ensemble of randomized decision
trees. Learning by uncorrelated memorization.
Few free parameters, popular for “data science”](https://image.slidesharecdn.com/cudatree-gtc-140325184725-phpapp02/75/CudaTree-GTC-2014-2-2048.jpg)
![Random Forest trees are trained like normal
decision trees (CART), but use random subset
of features at each split.
bestScore = bestThresh = None
for i in RandomSubset(nFeatures):
Xi, Yi = sort(X[:, i], Y)
for nLess, thresh in enumerate(Xi):
score = Impurity(nLess, Yi)
if score < bestScore:
bestScore = score
bestThresh = thresh
Decision Tree Training
1;](https://image.slidesharecdn.com/cudatree-gtc-140325184725-phpapp02/75/CudaTree-GTC-2014-3-2048.jpg)





















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)







![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)






