Downloaded 572 times



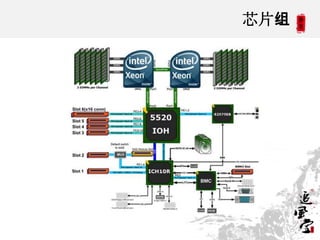
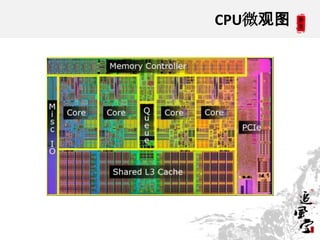
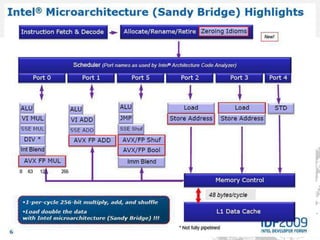
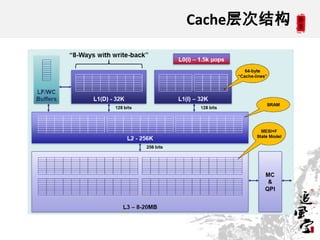
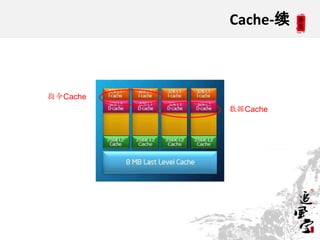
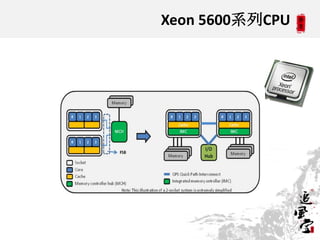
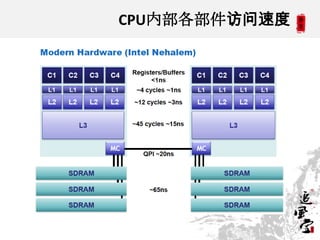
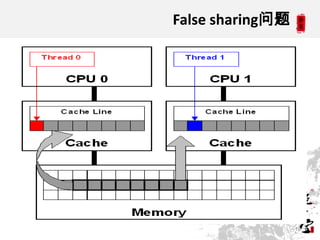
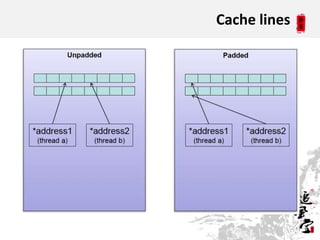



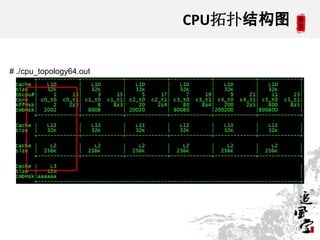




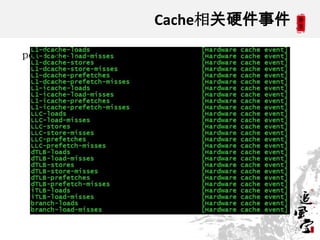



This document discusses CPUs and provides information about their architecture and performance. It begins with an overview and outlines topics like measurement, utilization, chipset architecture, cache hierarchy, and components inside CPUs. Examples are given of Intel Xeon and Sandy Bridge CPUs. Performance numbers are listed for operations like L1/L2 cache references and network/disk data transfers. Tools for investigating hardware topology and benchmarking micro-level performance are also introduced.
































































![[OpenStack Days Korea 2016] Track3 - OpenStack on 64-bit ARM with X-Gene](https://cdn.slidesharecdn.com/ss_thumbnails/32apm-160226173205-thumbnail.jpg?width=640&height=640&fit=bounds)






























