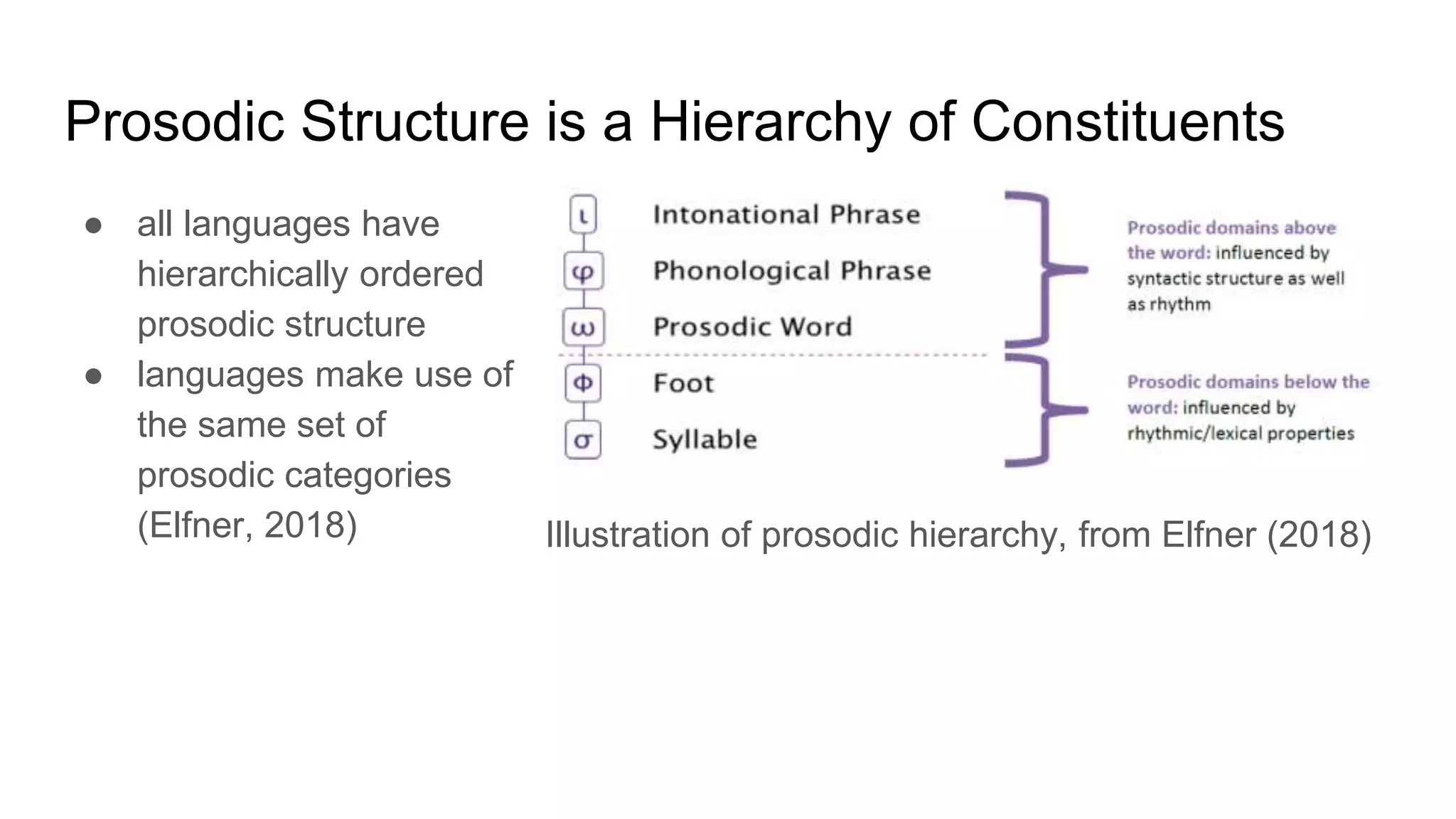
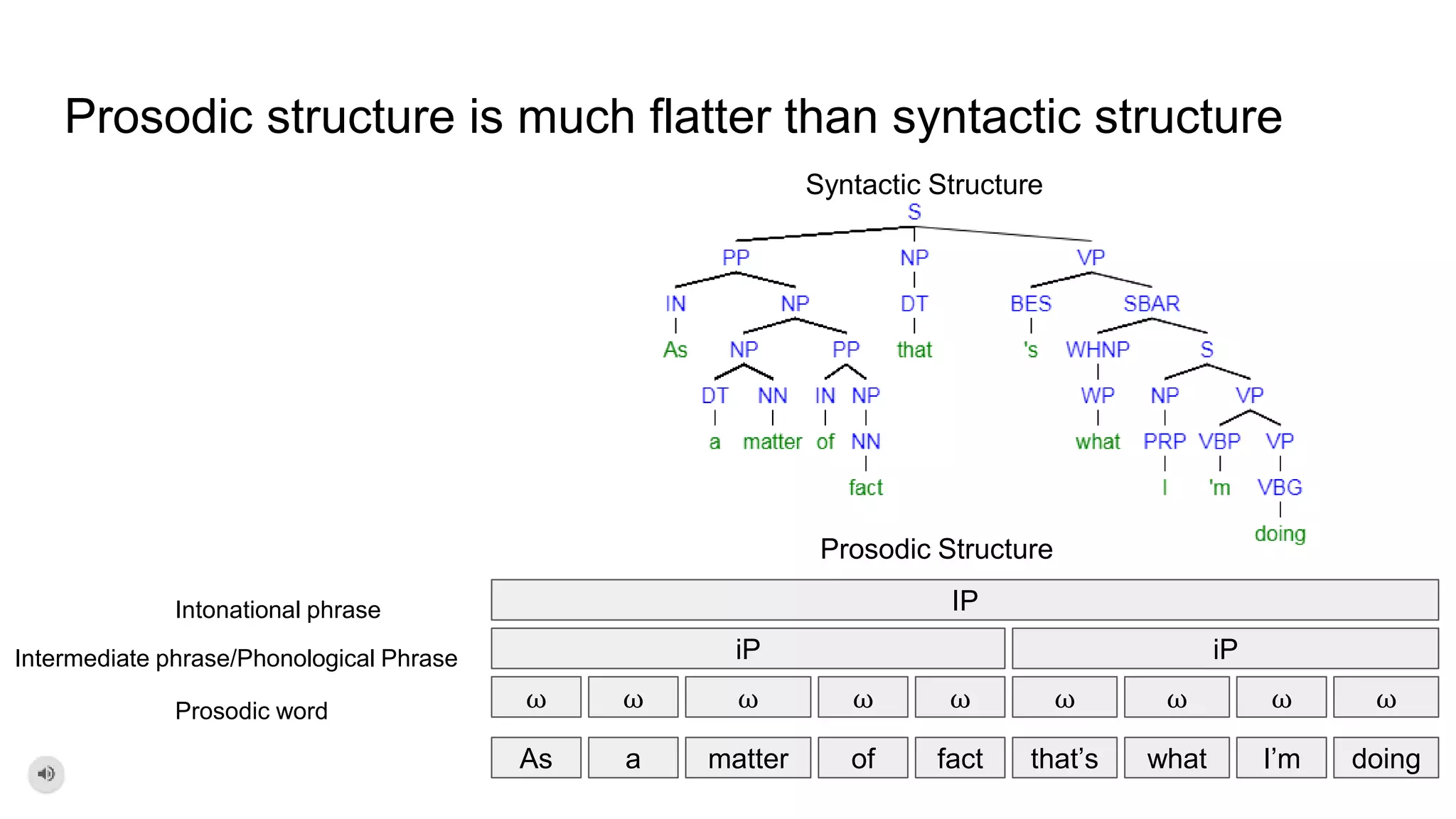
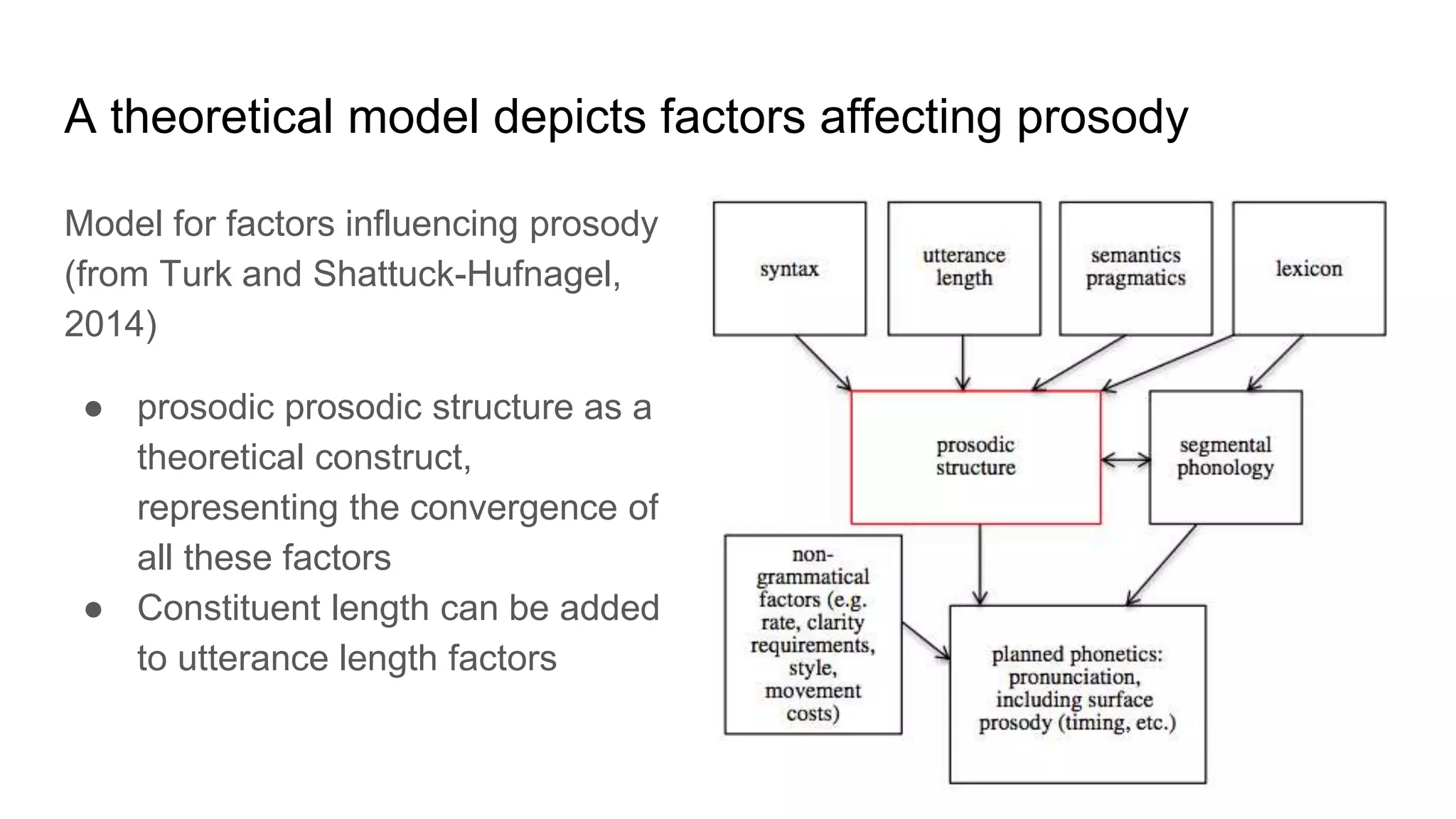
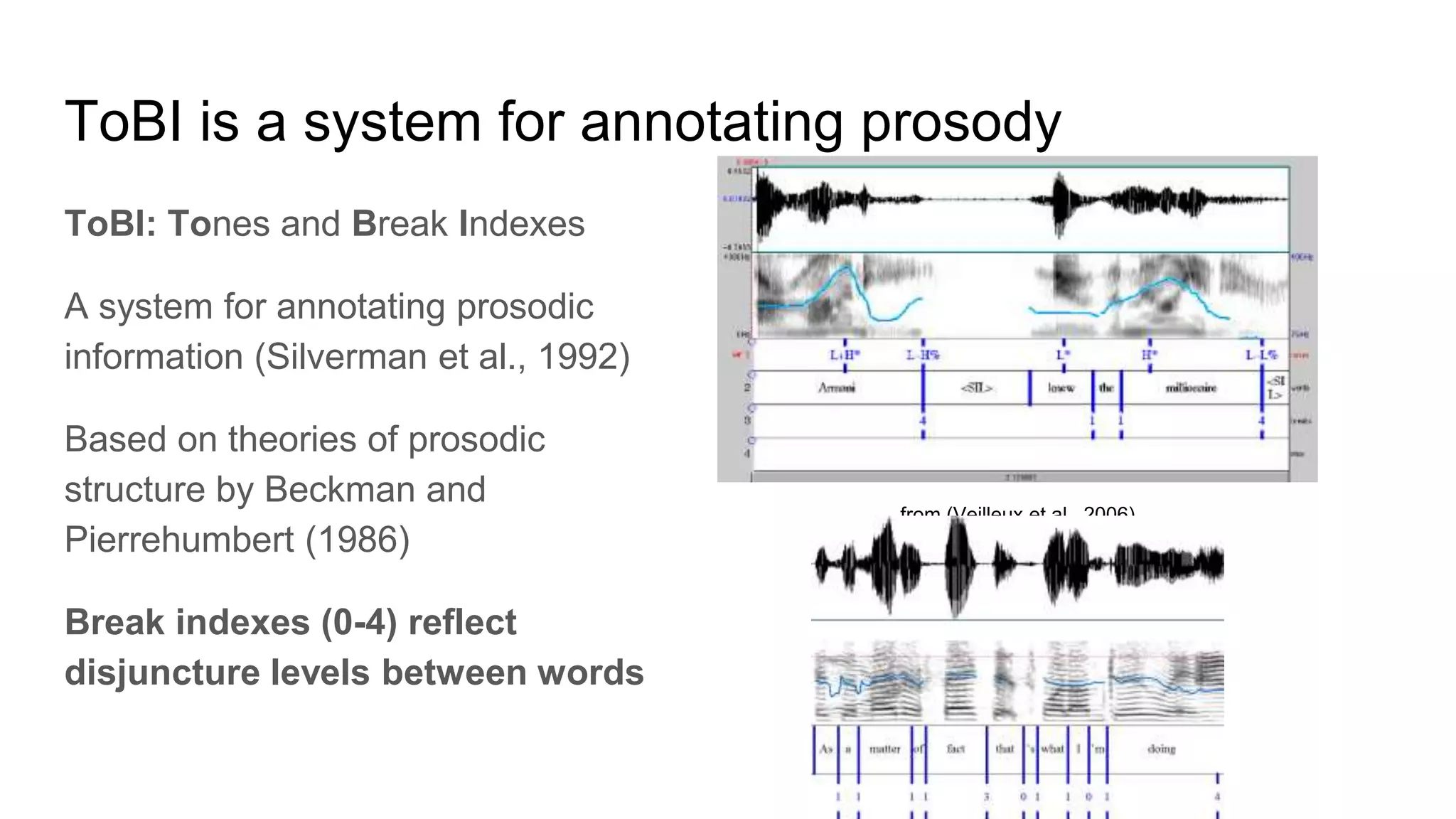
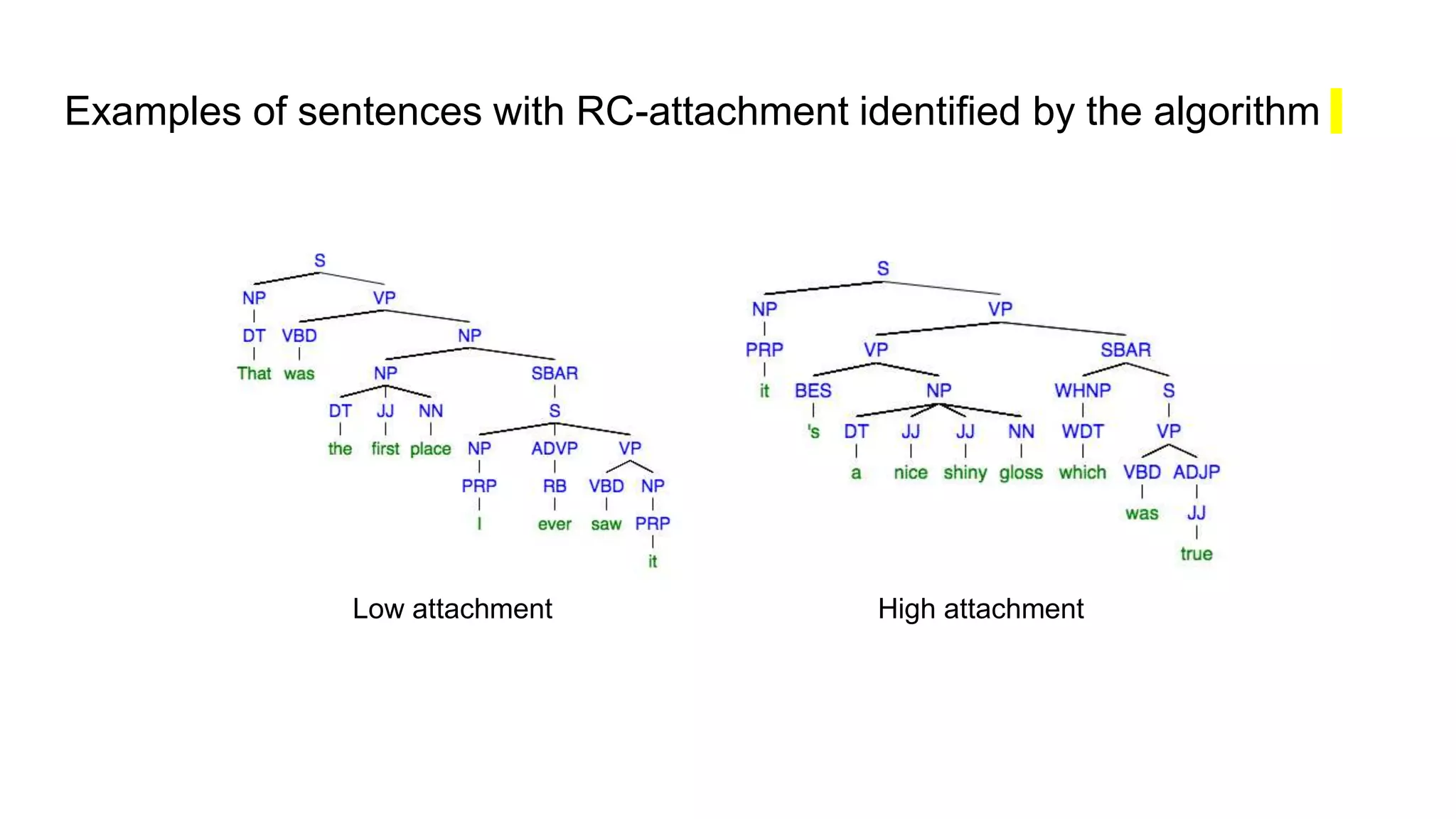
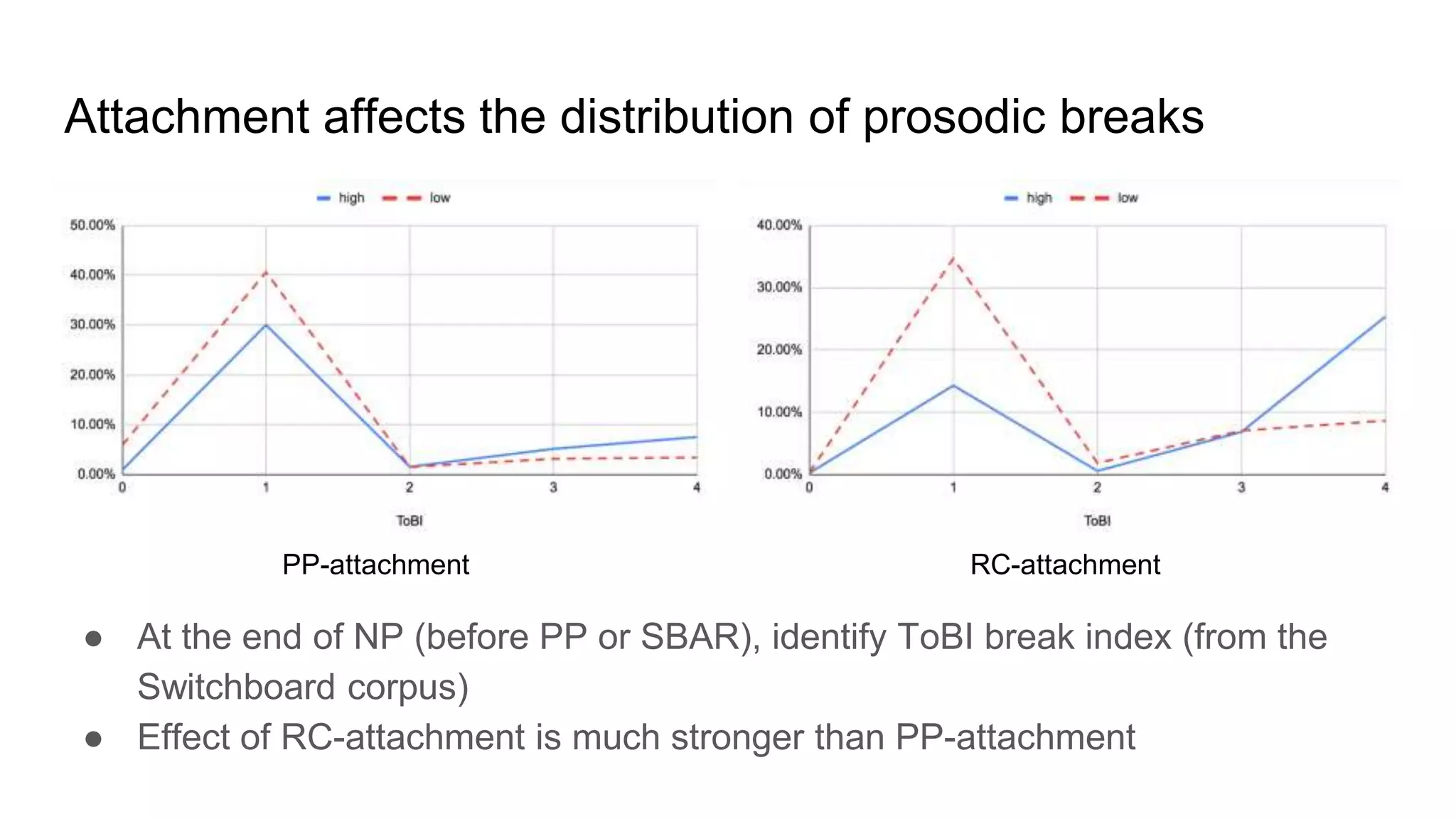
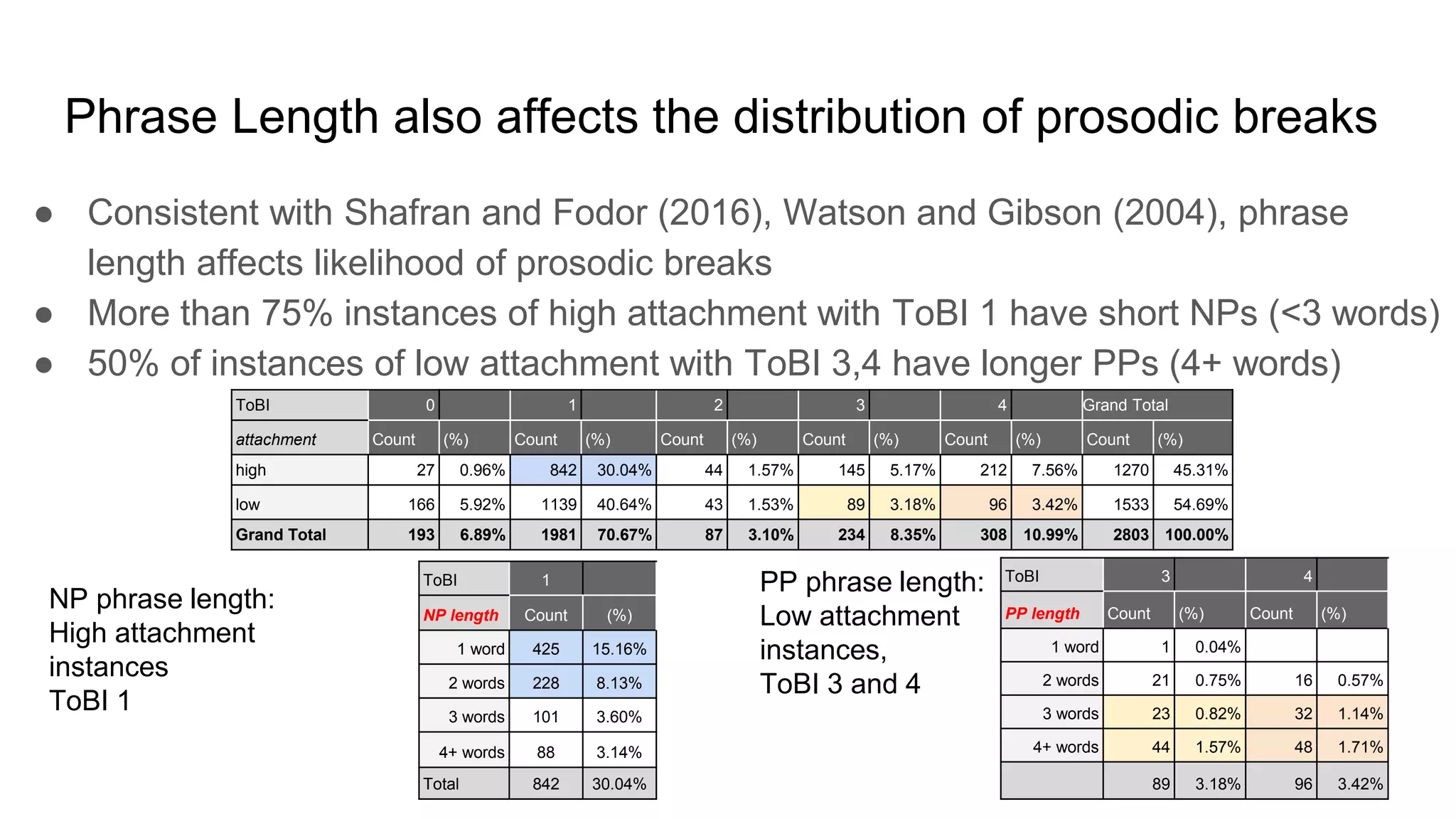
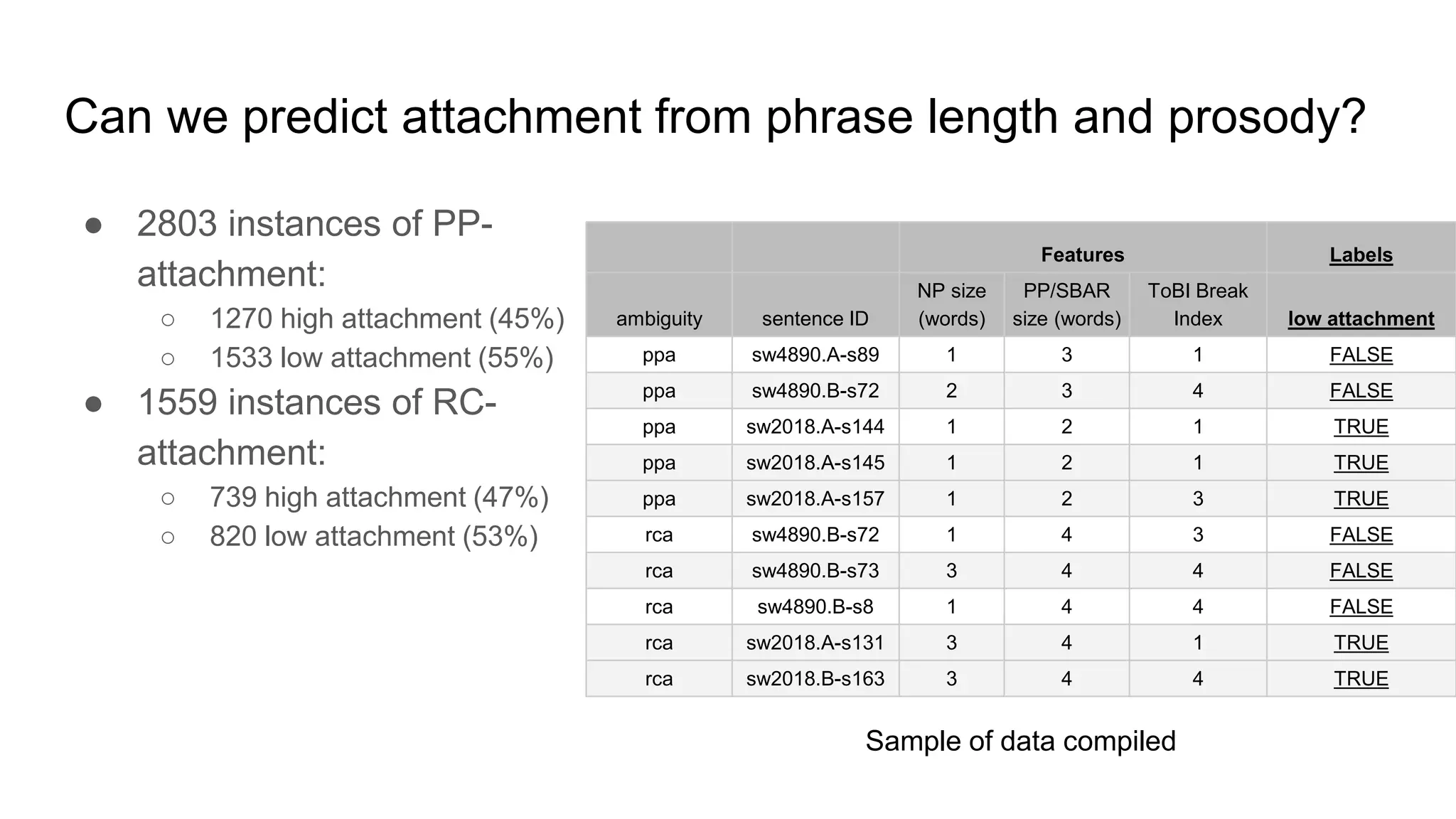
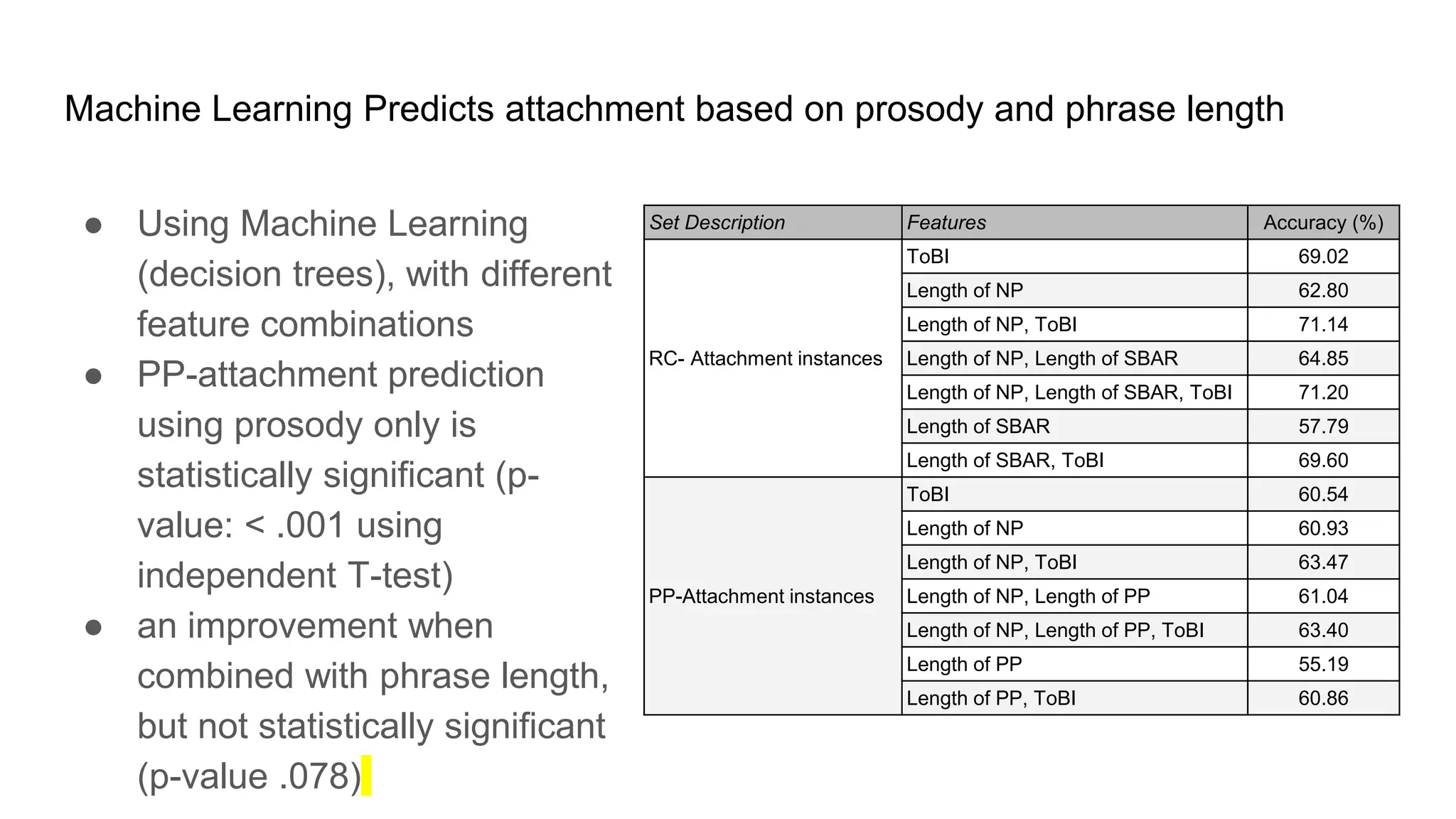
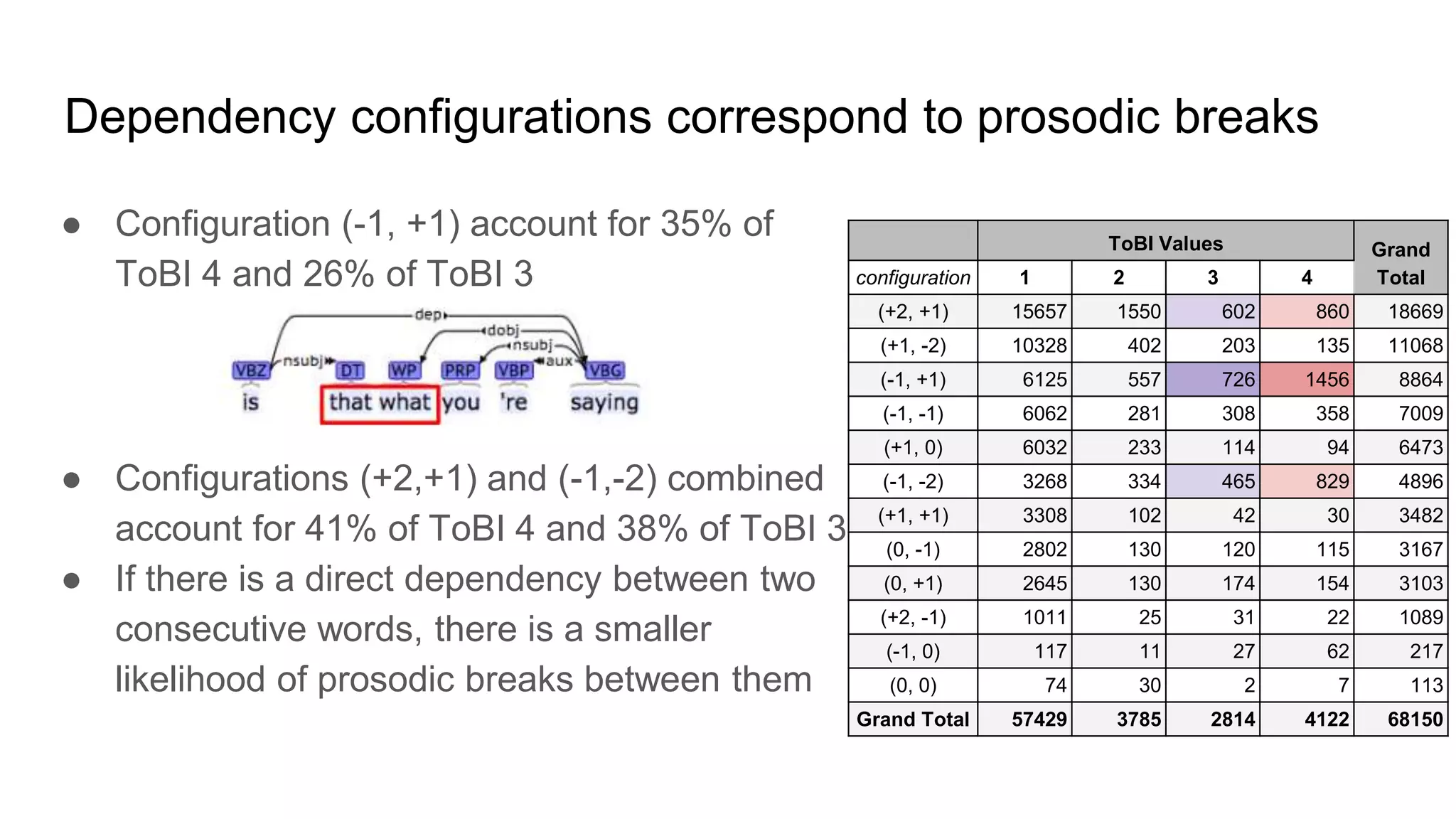
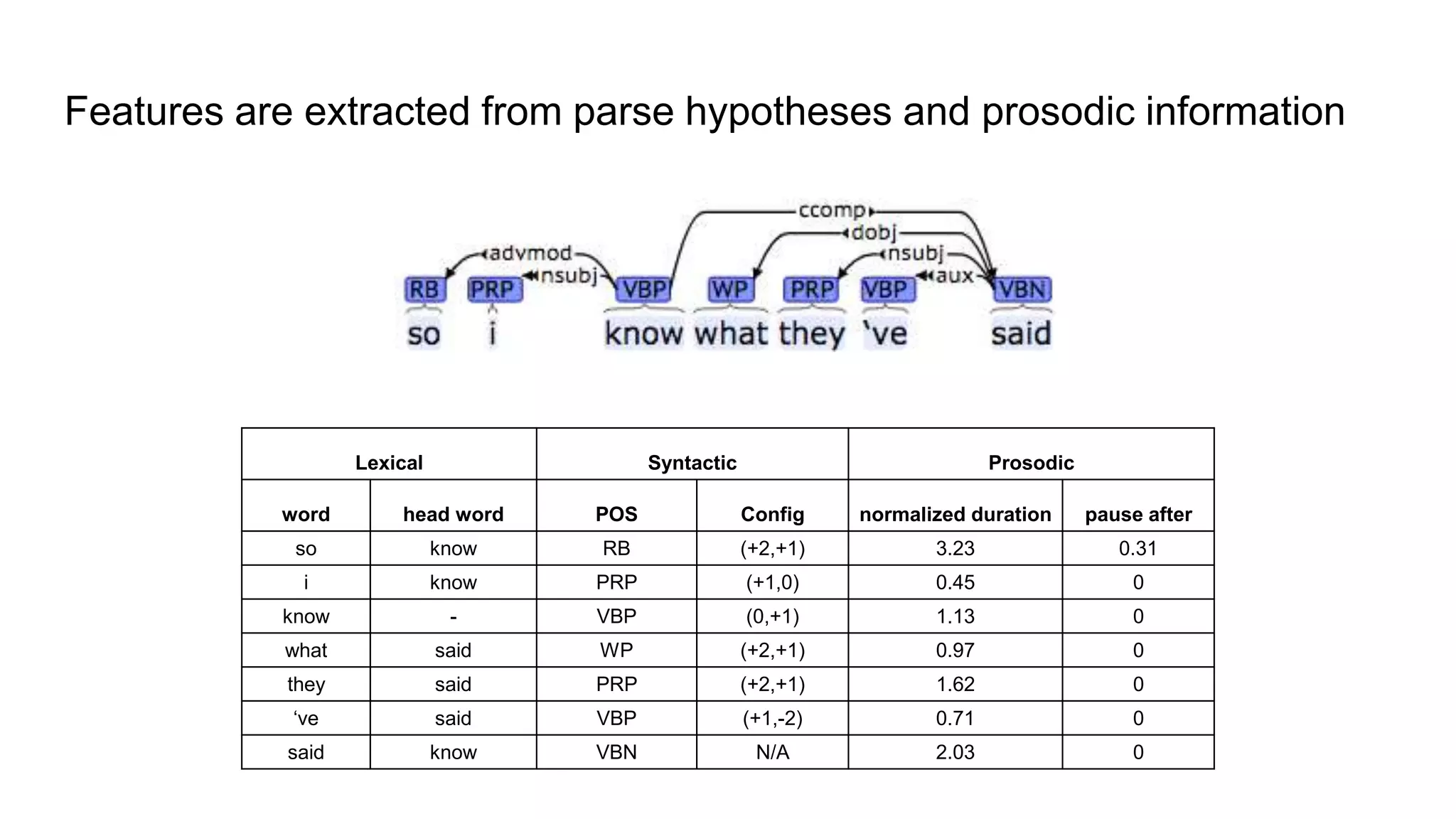
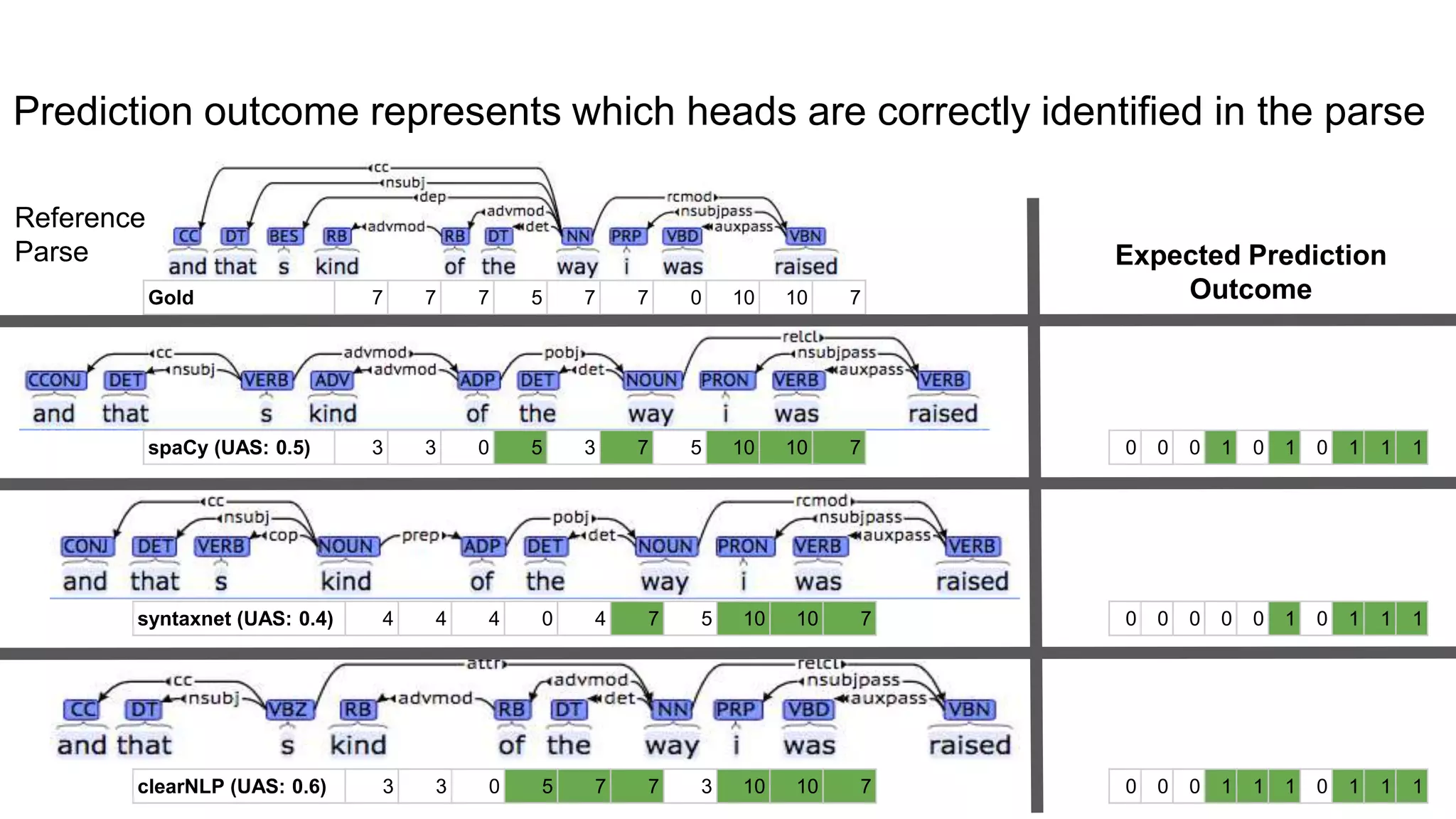
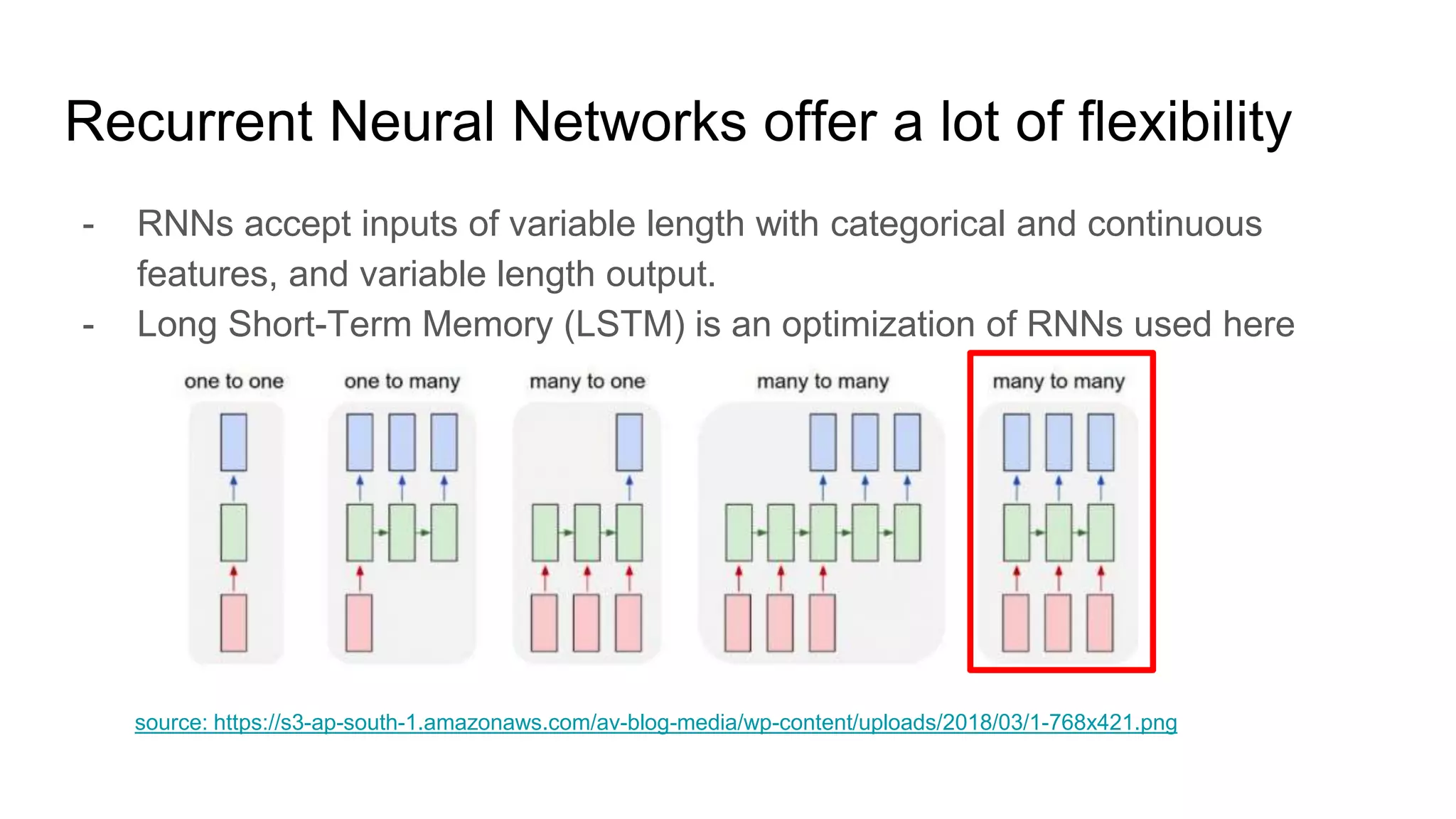
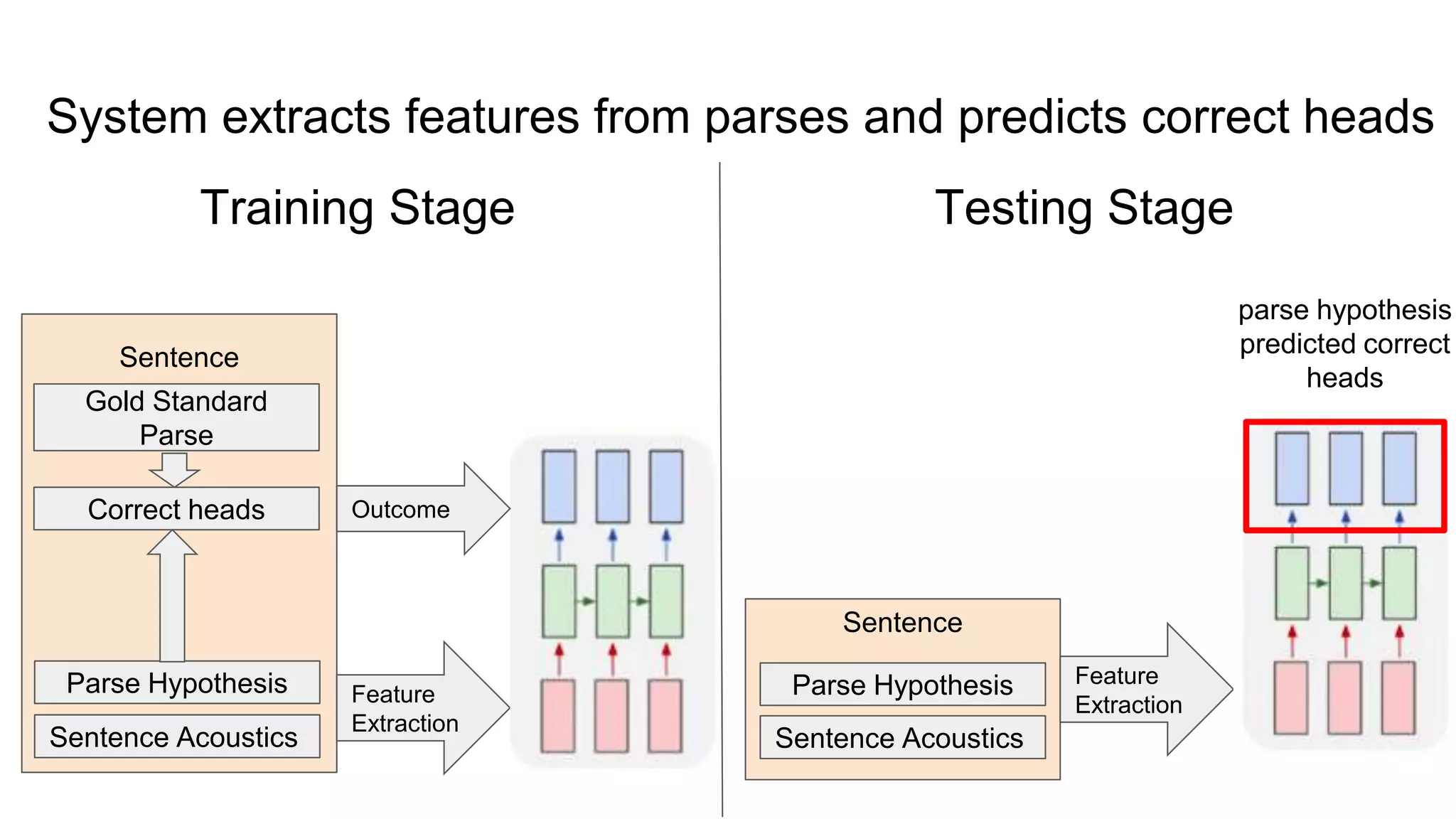
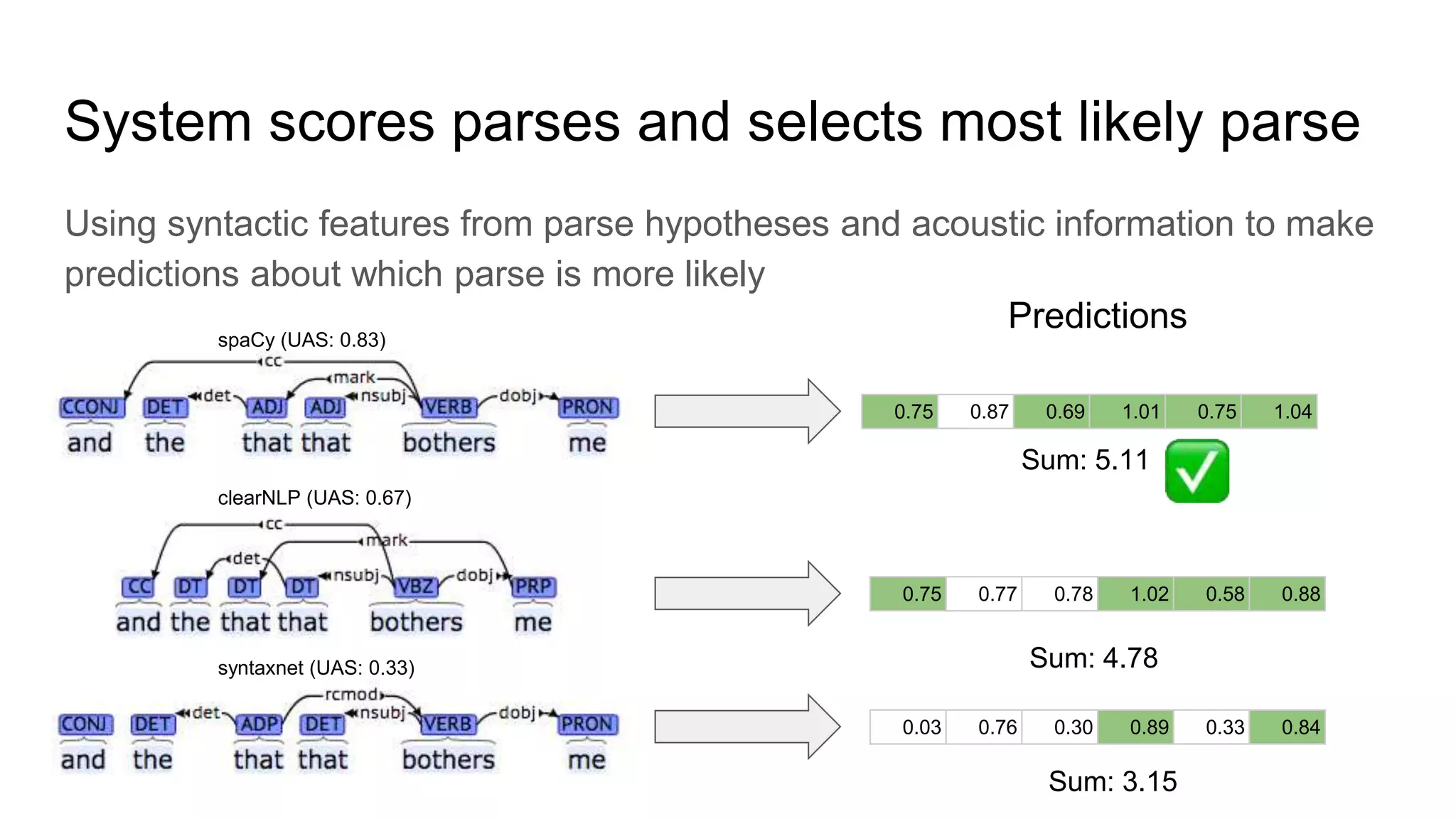
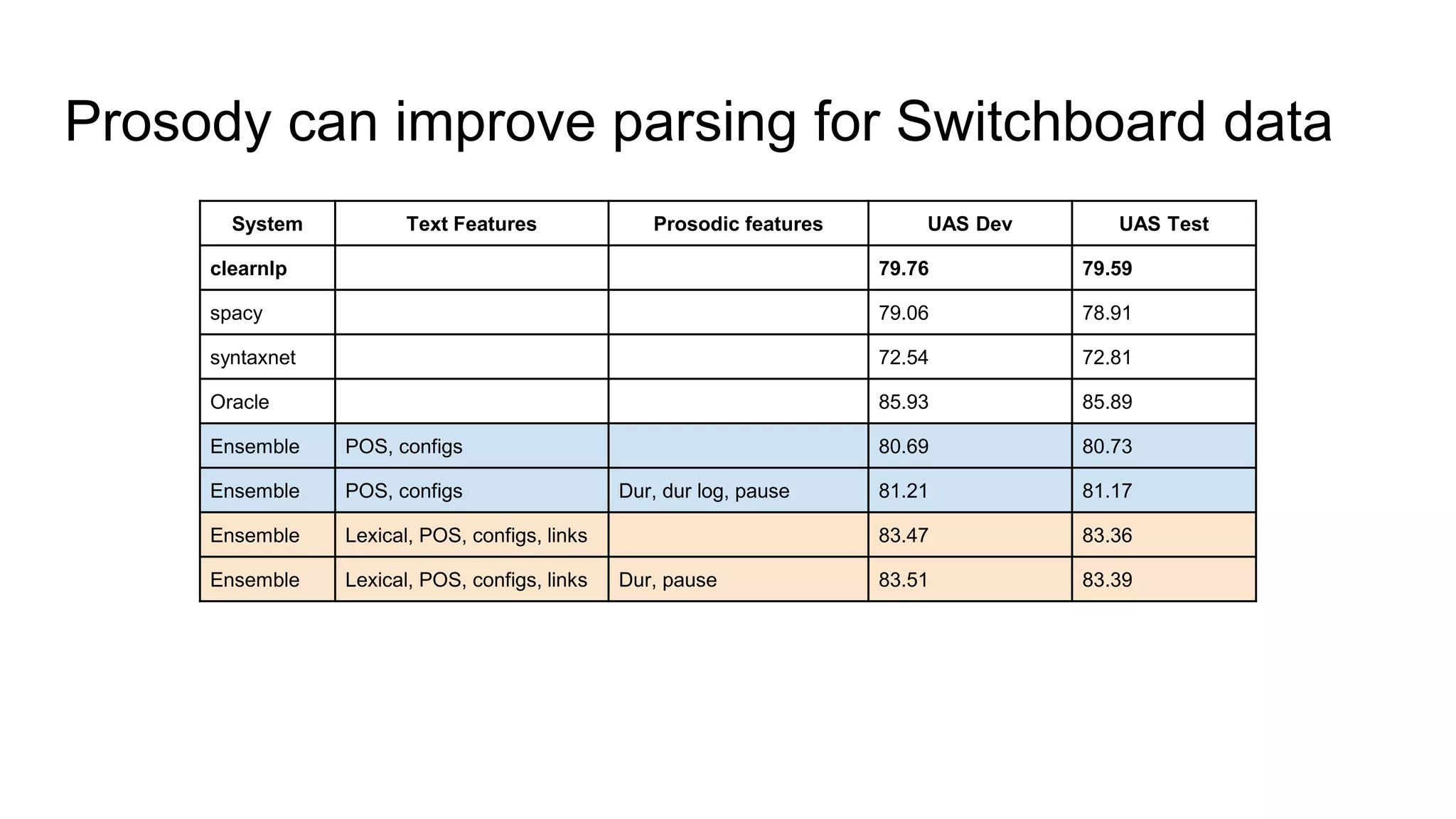
The document outlines a dissertation titled 'Computational Approaches to the Syntax-Prosody Interface' by Hussein Ghaly, which focuses on improving the automatic syntactic parsing of spontaneous speech by leveraging prosodic cues. It discusses theoretical frameworks, challenges, and opportunities within the intersection of computational linguistics and prosody research, alongside experimental findings on how prosody can resolve syntactic ambiguities in sentence structures. The research demonstrates the efficacy of prosodic features in parsing and understanding spoken language through machine learning models and analyses of speech corpora.












































![[Paper review] BERT](https://cdn.slidesharecdn.com/ss_thumbnails/paperreviewbert-190507052754-thumbnail.jpg?width=640&height=640&fit=bounds)












































