Download as PDF, PPTX








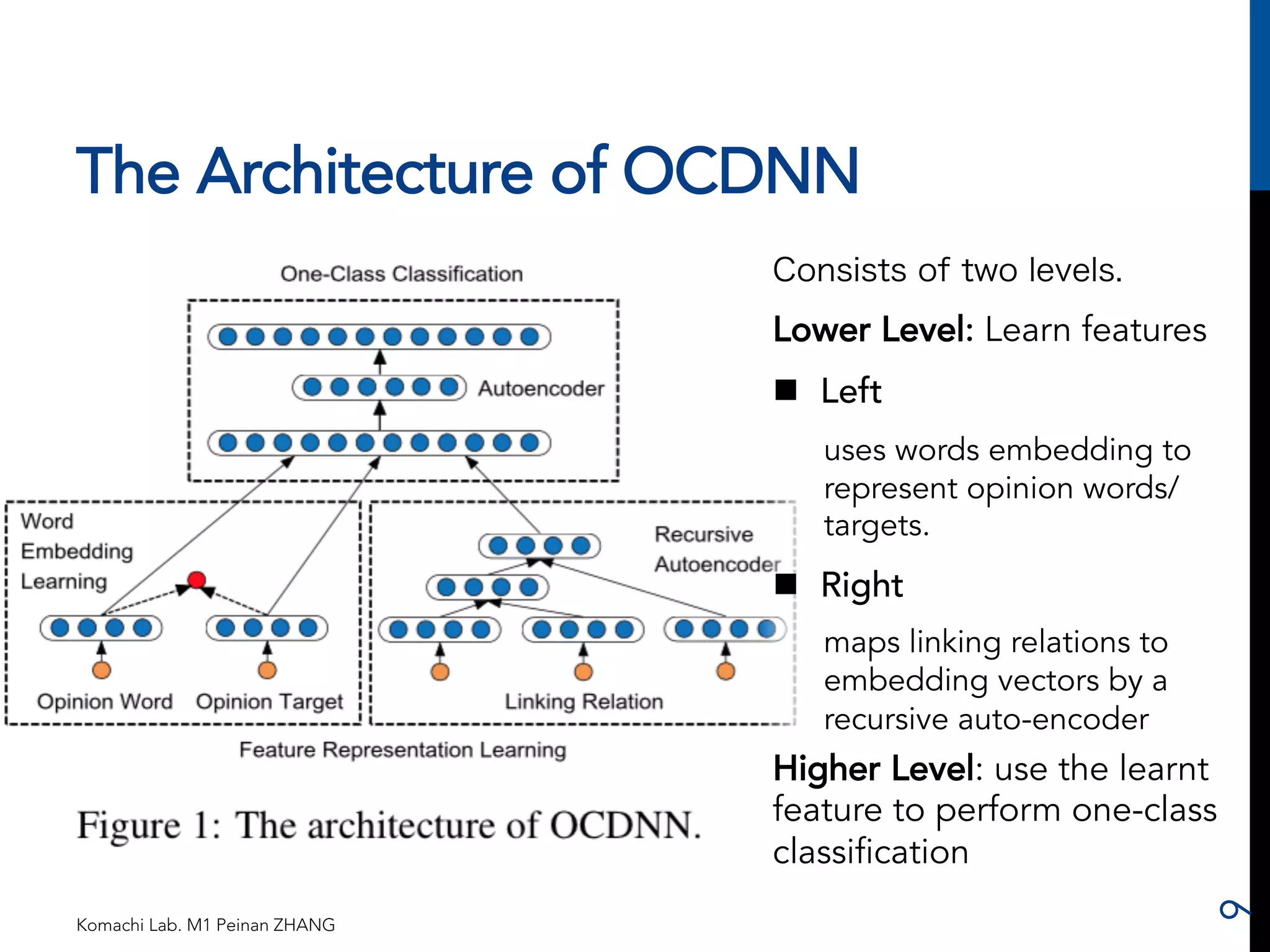






![Linking Relation Representation by
Using Recursive Auto-encoder
Komachi Lab. M1 Peinan ZHANG
1. c_s と c_t との間の係
り受け関係を取ってくる。
2. c_s と c_t をそれぞれ
[SC] と [ST] に置き換え
る。
3. 点線内を3層からなる
auto-encoder とし、2つ
の n-element vector を
中間層で1つの n-element
vector に圧縮す
る(下式)。
4. W を入力と出力のユー
クリッド距離が最小にな
るまで更新していく。
16
Example. too loud to listen to the player](https://image.slidesharecdn.com/20141106-141105232010-conversion-gate01/75/COLING-2014-Joint-Opinion-Relation-Detection-Using-One-Class-Deep-Neural-Network-16-2048.jpg)
![One-Class Classification for
Opinion Relation Detection
We represent an opinion relation candidate c_o by a vector
v_o=[v_s; v_t; v_r], and this vector v_o is to feed to
upper level auto-encoder.
For opinion relation detection, error scores that are smaller
than a threshold theta are classified as positive.
To estimate theta, we need to introduce a positive
proportion (pp) score as follows,
Komachi Lab. M1 Peinan ZHANG
17](https://image.slidesharecdn.com/20141106-141105232010-conversion-gate01/75/COLING-2014-Joint-Opinion-Relation-Detection-Using-One-Class-Deep-Neural-Network-17-2048.jpg)




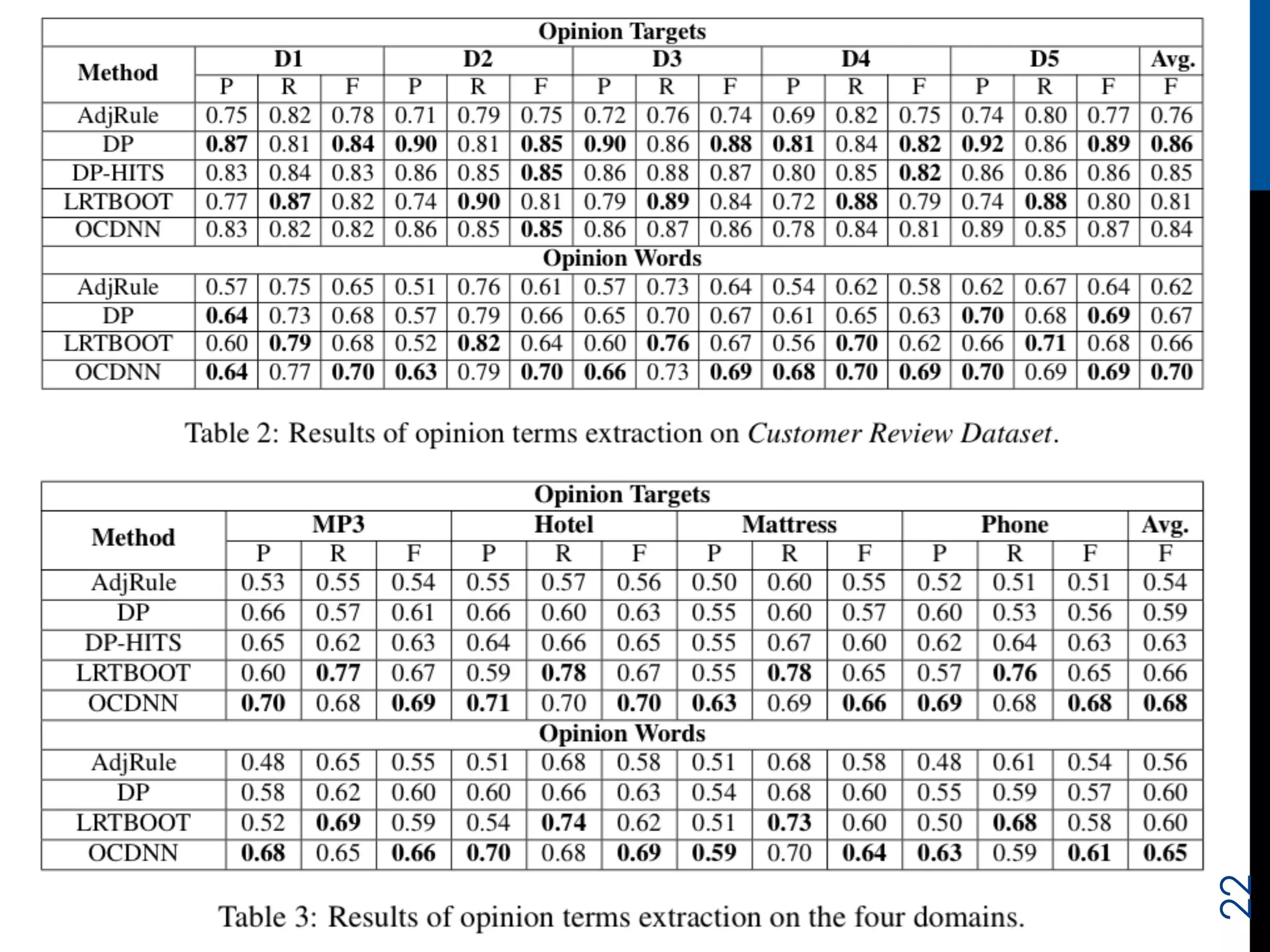

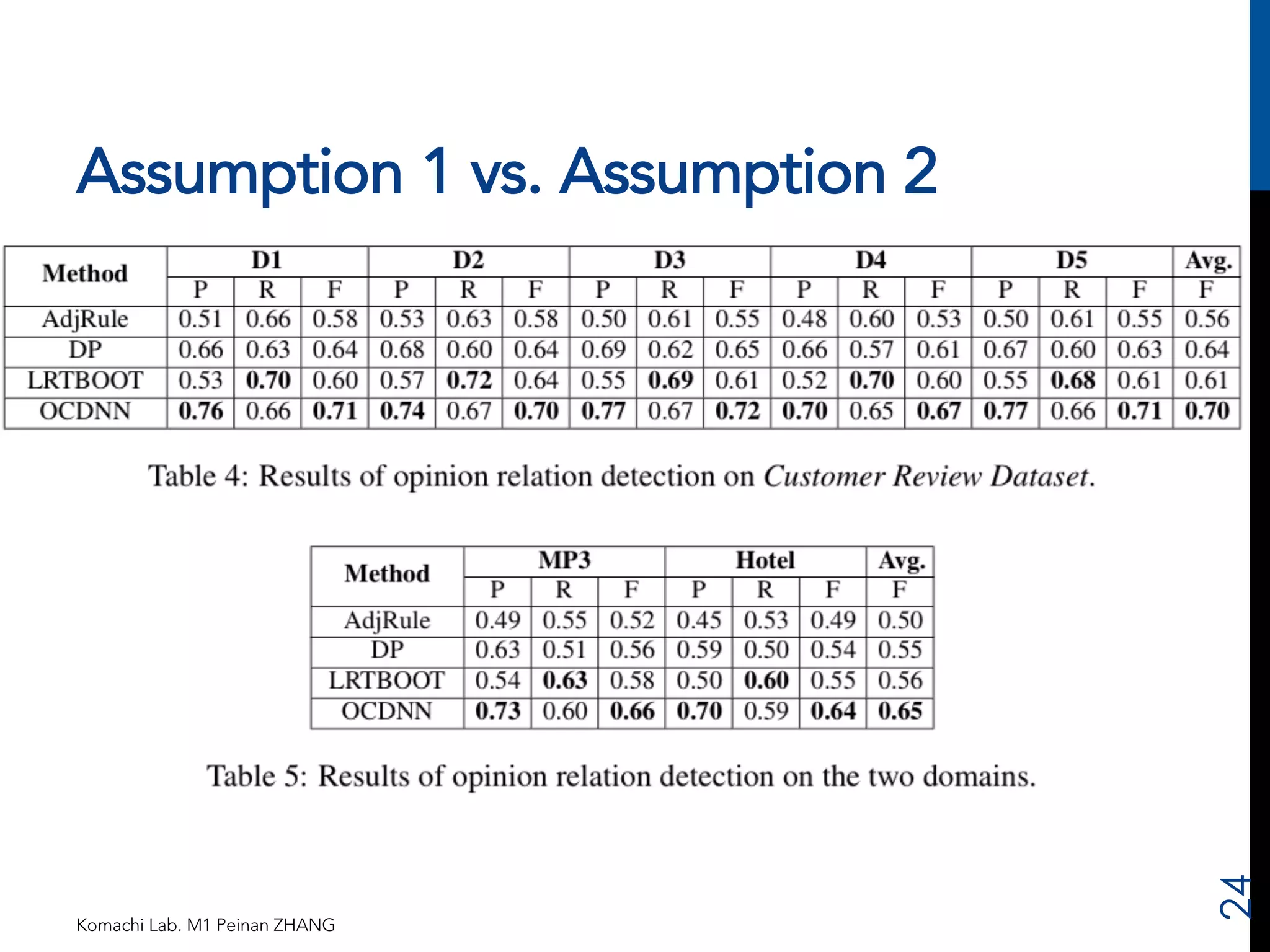




The document proposes a novel joint opinion relation detection method using a one-class deep neural network (OCDNN). It addresses the problems of prior methods by simultaneously considering opinion words, targets, and their linking relations. The OCDNN consists of two levels: the lower level learns features using word embeddings and a recursive autoencoder; the higher level performs one-class classification. Experiments on customer review datasets show the proposed method outperforms baselines by up to 9% F-measure by verifying all three required conditions of opinion relations.






![[Paper Reading] Supervised Learning of Universal Sentence Representations fro...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingmt-supervisedlearningofuniversalsentencerepresentationsfromnaturallanguageinferencedata-171216153412-thumbnail.jpg?width=640&height=640&fit=bounds)


































































