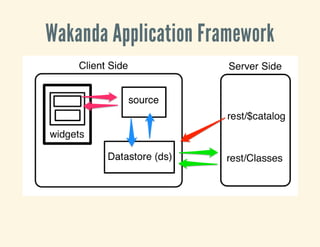
The document discusses Google Glass and its integration with WakandaDB, emphasizing tools for developing data-rich business applications. It includes details about the Wakanda application framework, a JSON data model, and a specific data schema for managing chickens. Additionally, it promotes the upcoming JS Everywhere event on October 25th, 2013.





















![{"dataClasses": [
{ "name": "Chicken",
"className": "Chicken",
"collectionName": "Chickens",
"scope": "public",
"attributes": [
{ "name": "ID",
"kind": "storage",
"scope": "public",
"unique": true,
"autosequence": true,
"type": "long",
"primKey": true
},
{ "name": "name",
"kind": "storage",
"scope": "public",
"type": "string"
},
{ "name": "hatchDate",
"kind": "storage",
"scope": "public",
"type": "date",
"simpleDate": false
}
}
]
}
]}](https://image.slidesharecdn.com/codecamp-131007101700-phpapp02/85/Code-Camp-Building-a-Glass-app-with-Wakanda-24-320.jpg)
















































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)








