






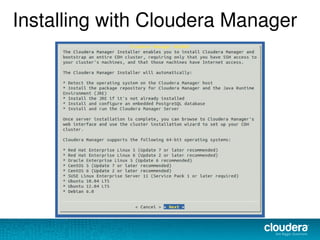

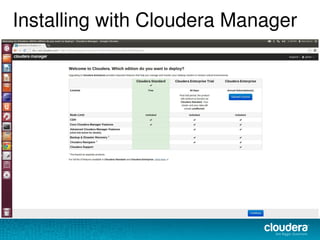
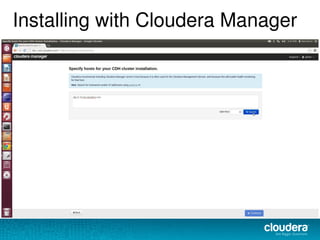
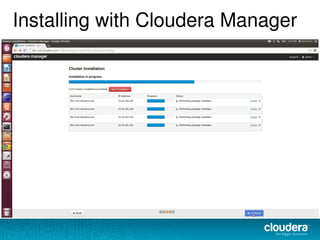









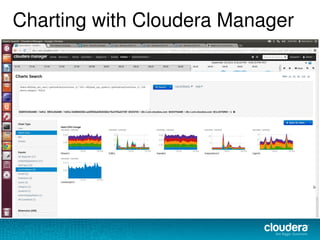

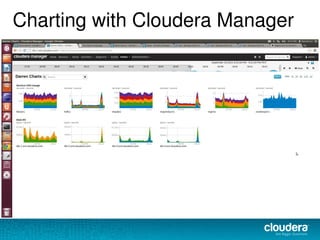







The document discusses the functionalities and advantages of Cloudera Manager for managing Hadoop clusters, highlighting its automation features, health checks, and integration capabilities with external tools like Nagios. It covers the installation process, common operational challenges, and enterprise-grade features like rolling upgrades and configuration management. Additionally, it provides links to resources for further understanding and utilizing Cloudera Manager effectively.























































































