Download to read offline
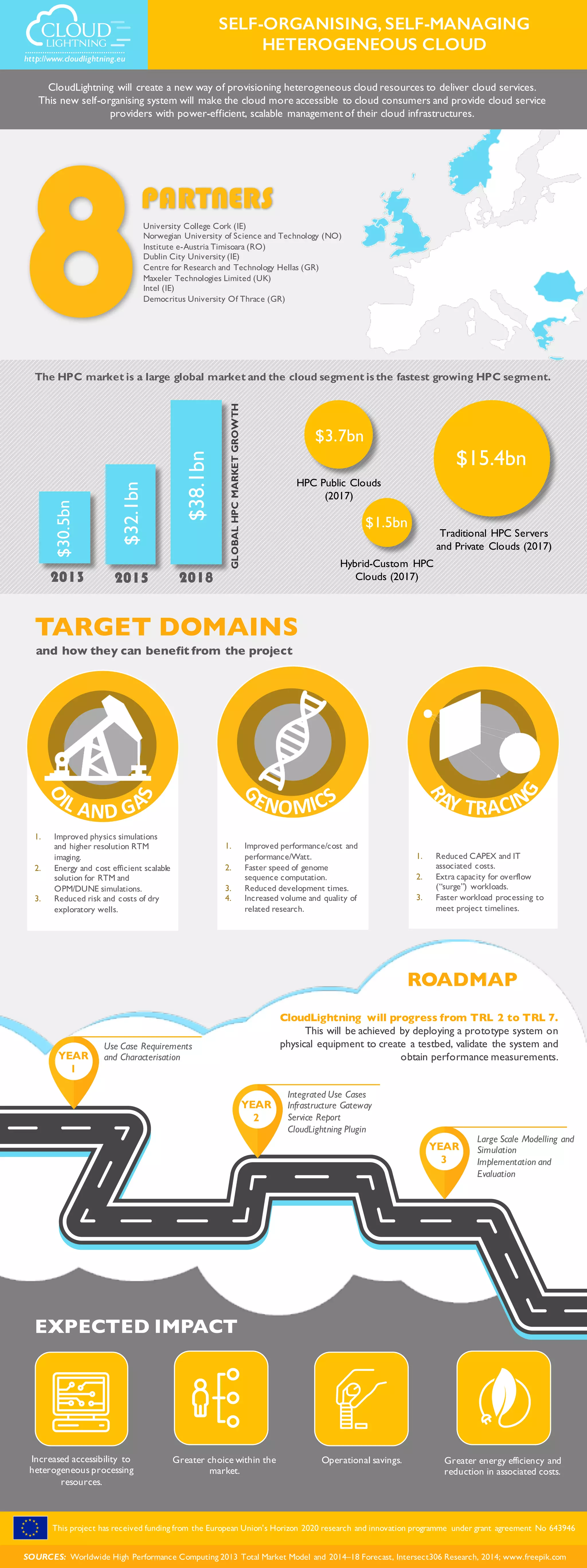

The document discusses the CloudLightning project aimed at creating a self-organizing cloud resource provisioning system to enhance accessibility and efficiency for both consumers and providers. Key benefits include improved computational performance, reduced costs, and faster processing times for high-performance computing (HPC). Funded by the EU's Horizon 2020 program, the project targets advancements in cloud services and aims to progress through technology readiness levels by deploying a prototype for testing.






























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)











