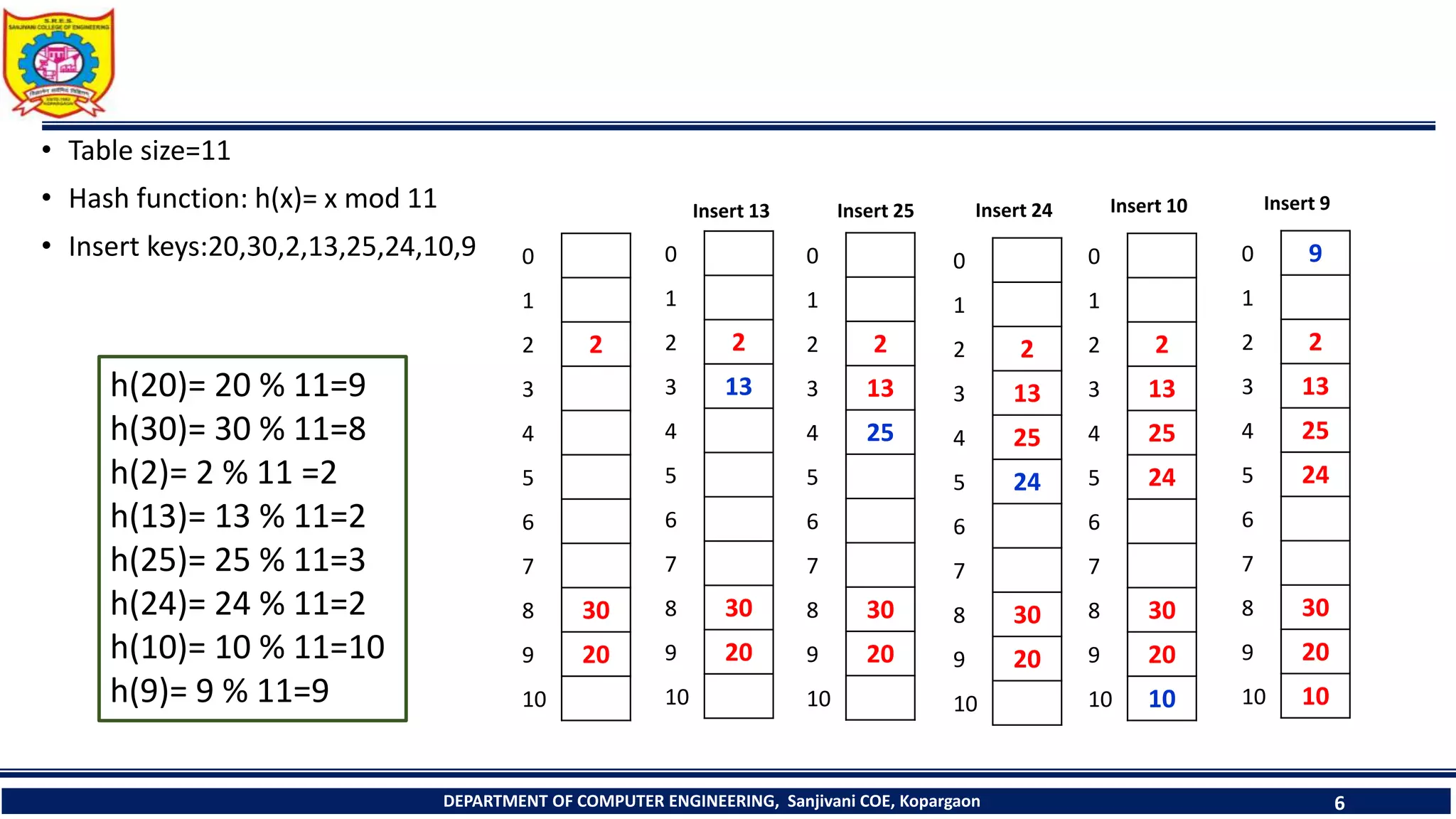
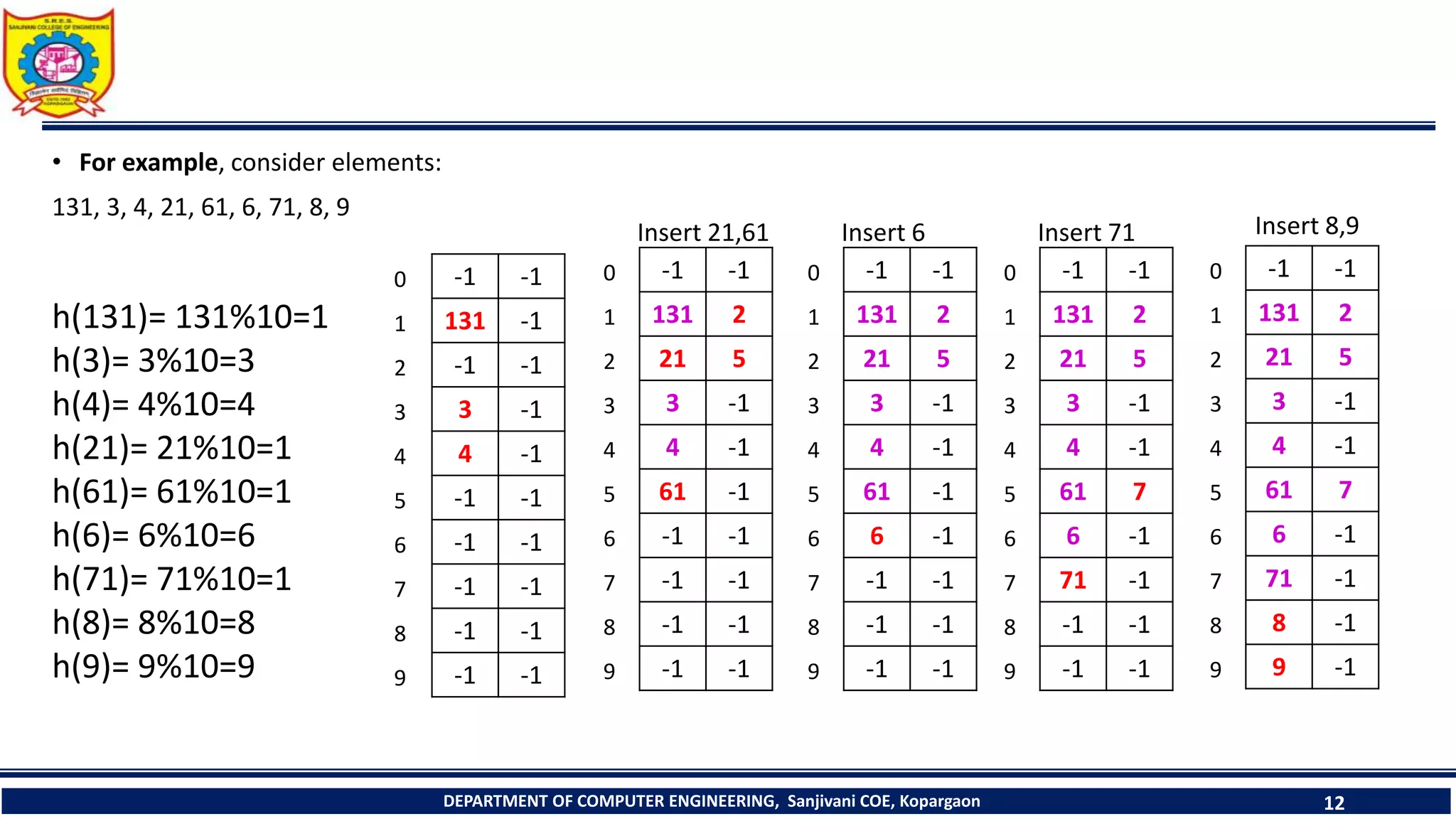
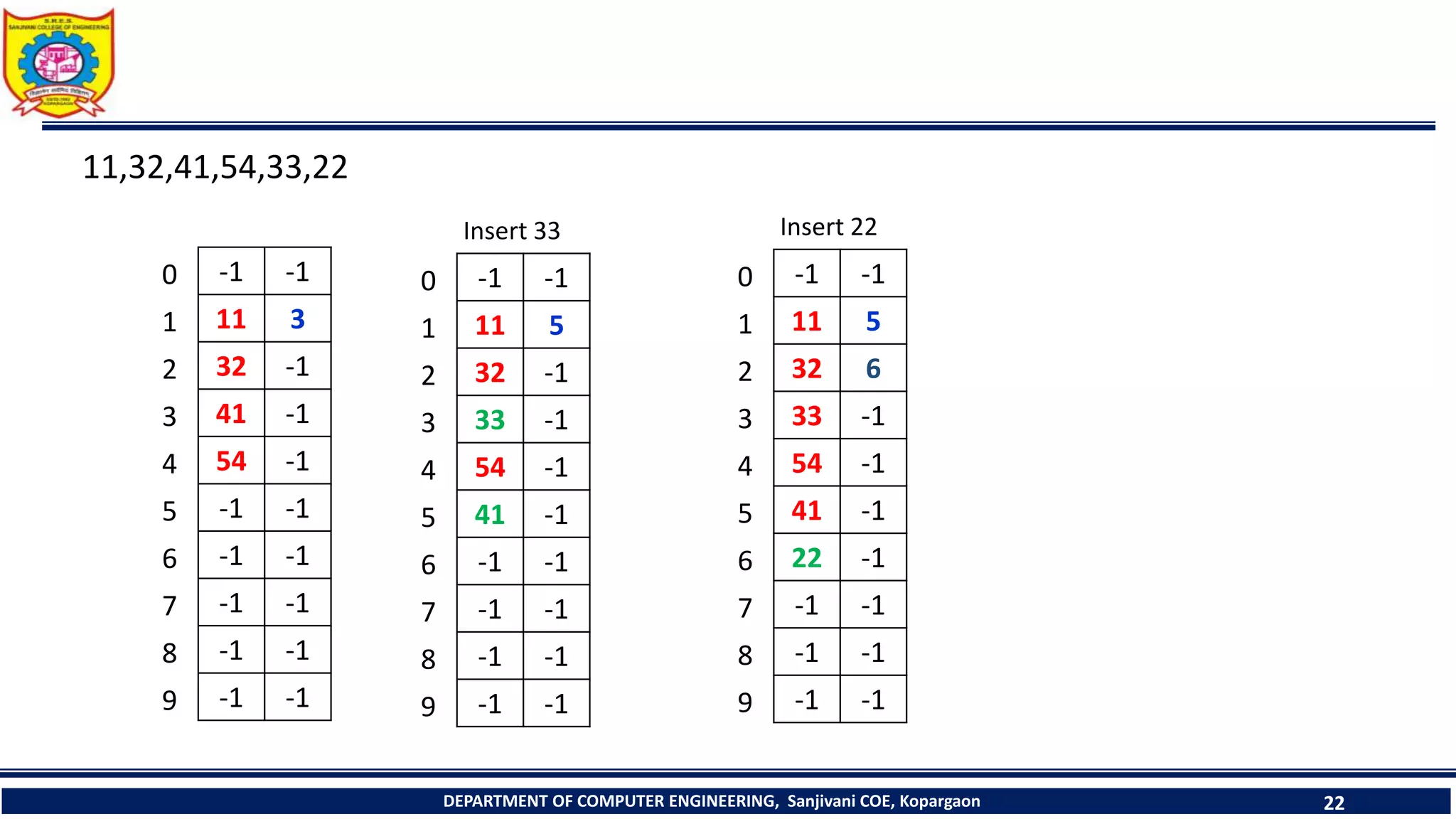
The document discusses linear probing as an open addressing technique for hash tables. It describes linear probing as placing an identifier in the next empty slot after its home bucket if a collision occurs. The document provides an example to demonstrate linear probing. It also discusses linear probing with chaining, where a chain of collided elements is maintained through pointers rather than replacing elements. Pseudocode for insertion and searching in linear probing tables is provided.







![#define MAX 10
int insert_lb(int key)
{
j=key % MAX;
for(i=0;i < MAX ; i++)
{
if(ht[j]== -1)
{
ht[j]=key;
DEPARTMENT OF COMPUTER ENGINEERING, Sanjivani COE, Kopargaon 9
return(j);
}
j=(j+1)%MAX;
}
return(-1);
}
Procedure to insert key in hash table](https://image.slidesharecdn.com/closedhashing-230705083716-4c9f3141/75/closed-hashing-pptx-9-2048.jpg)
![• Procedure to search key in hash table
DEPARTMENT OF COMPUTER ENGINEERING, Sanjivani COE, Kopargaon 10
int search_lb()
{
cout<<“Enter the key to be search”;
cin>>key;
j= key % MAX;
for(i=0;i<MAX;i++)
{
if(ht[j]==key)
return(j);
else
j=(j+1)%MAX;
}
return -1;
}](https://image.slidesharecdn.com/closedhashing-230705083716-4c9f3141/75/closed-hashing-pptx-10-2048.jpg)





![DEPARTMENT OF COMPUTER ENGINEERING, Sanjivani COE, Kopargaon 17
void insertwor(int b[][2])
{
int r,s,t,a;
printf("n Enter Data");
scanf("%d",&a);
s= a % MAX;
if(b[s][0]==-1)
b[s][0]=a;
else
{
while(1)
{
printf("nTrue Collision Occurs");
getch();
if(b[s][1]== -1)
{
t=s;
while(b[s][0]!=-1)
{
s=(s+1)%MAX;
if(s==t)
{
printf("Overflow");
break;
}
}](https://image.slidesharecdn.com/closedhashing-230705083716-4c9f3141/75/closed-hashing-pptx-17-2048.jpg)
![if(s!=t)
{
b[s][0]=a;
b[t][1]=s;
}
break;
} //if end
else
s=b[s][1];
}//while end
}//else end
}
DEPARTMENT OF COMPUTER ENGINEERING, Sanjivani COE, Kopargaon 18](https://image.slidesharecdn.com/closedhashing-230705083716-4c9f3141/75/closed-hashing-pptx-18-2048.jpg)
![void displaywor(int b[][2])
{
int i,r,s,t,a;
printf("nINDEXtDATAtCHAIN");
for(i=0;i<max;i++)
{
if(b[i][0]!=-1)
{
printf("n%d",i);
DEPARTMENT OF COMPUTER ENGINEERING, Sanjivani COE, Kopargaon 19
printf("t%d",b[i][0]);
//if(b[i][1]!=-1)
printf("t%d",b[i][1]);
}
}
getch();
}](https://image.slidesharecdn.com/closedhashing-230705083716-4c9f3141/75/closed-hashing-pptx-19-2048.jpg)
![void searchwor(int b[][2])
{
int r,s,a;
printf("Enter Data Which U Want To Search");
scanf("%d",&a);
s=a%MAX;
while(1)
{
if(b[s][0]==a)
break;
s=b[s][1];
DEPARTMENT OF COMPUTER ENGINEERING, Sanjivani COE, Kopargaon 20
if(s==-1)
{
printf("Not Found");
break;
}
}//end of while
else
{
printf("nIndex Is %d:",s);
printf("nData Is %d:",b[s][0]);
printf("n Index Which Is Chained From It:%d",b[s][1]);
}
}](https://image.slidesharecdn.com/closedhashing-230705083716-4c9f3141/75/closed-hashing-pptx-20-2048.jpg)




















































![Seller Deck - Presentation [Concert L2].PPTX](https://cdn.slidesharecdn.com/ss_thumbnails/sellerdeck-presentationconcertl2-251219171156-24982daf-thumbnail.jpg?width=640&height=640&fit=bounds)

















