This document summarizes the key points about database normalization from Chapter 3 of an unknown textbook. It discusses:
1. The reasons for normalizing a database, including improving accuracy, efficiency, and making queries and reports easier.
2. The concept of normalization as a sequence of steps to improve database design by putting relations into a more desirable form and removing duplication.
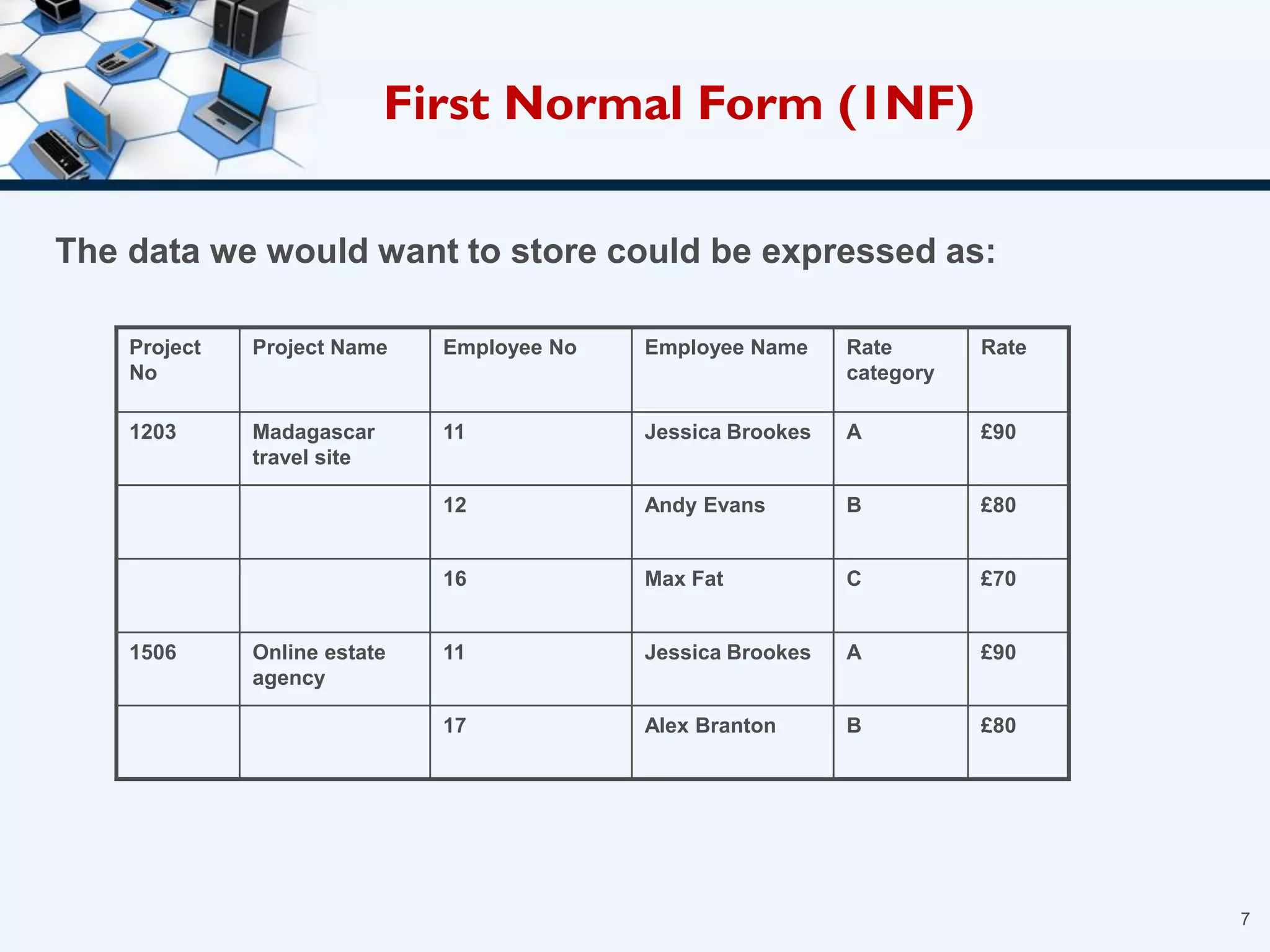
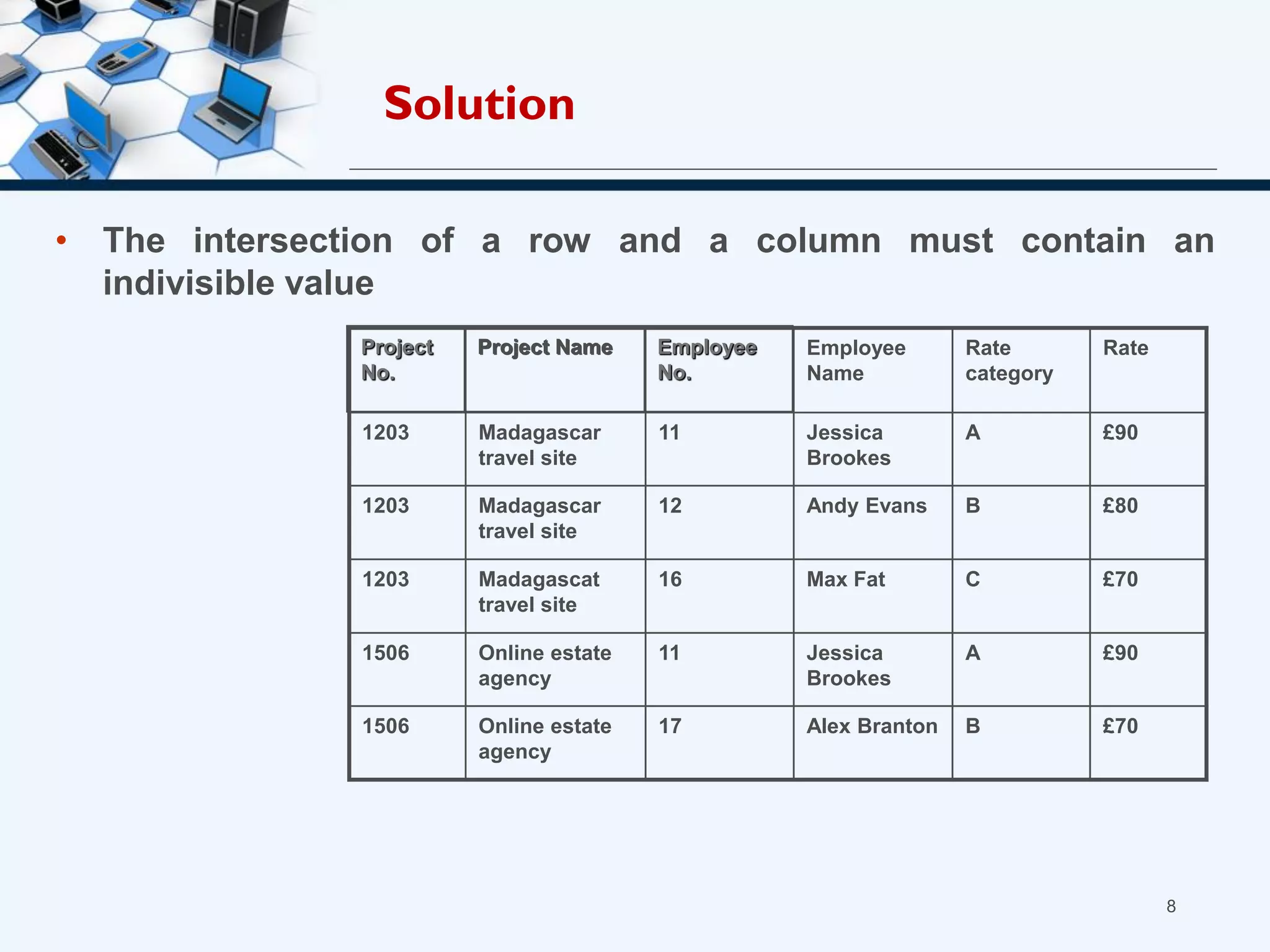
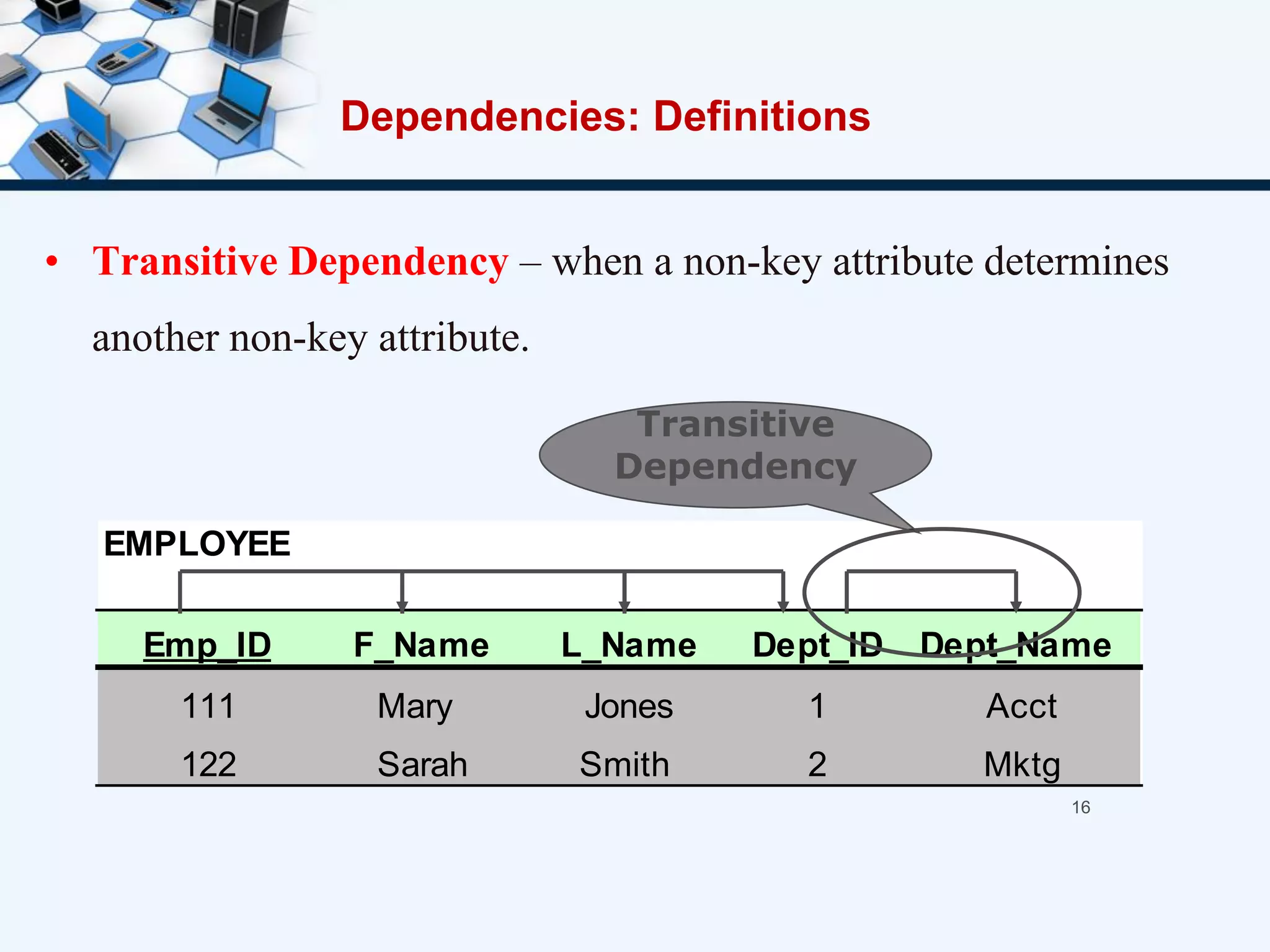
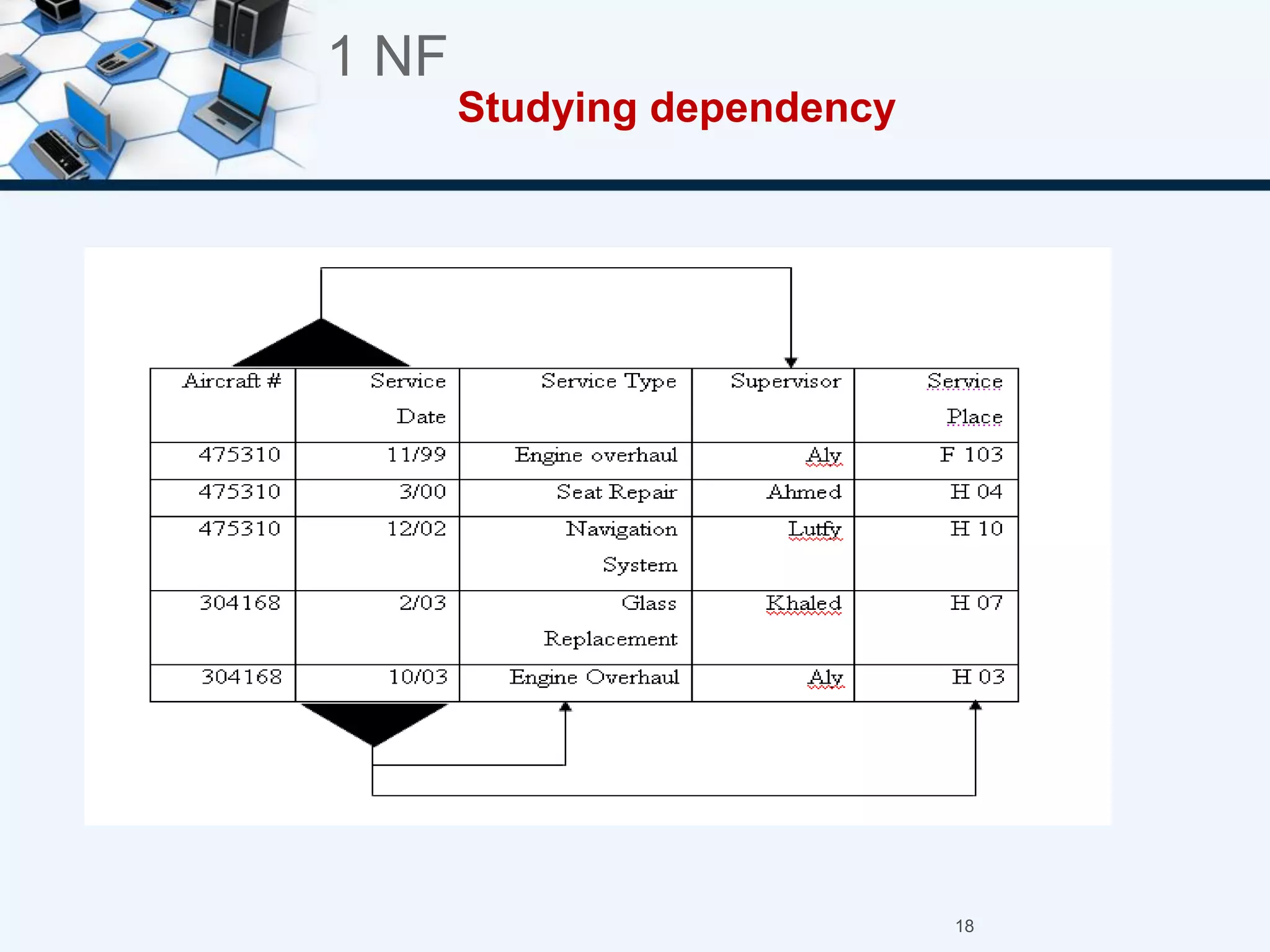
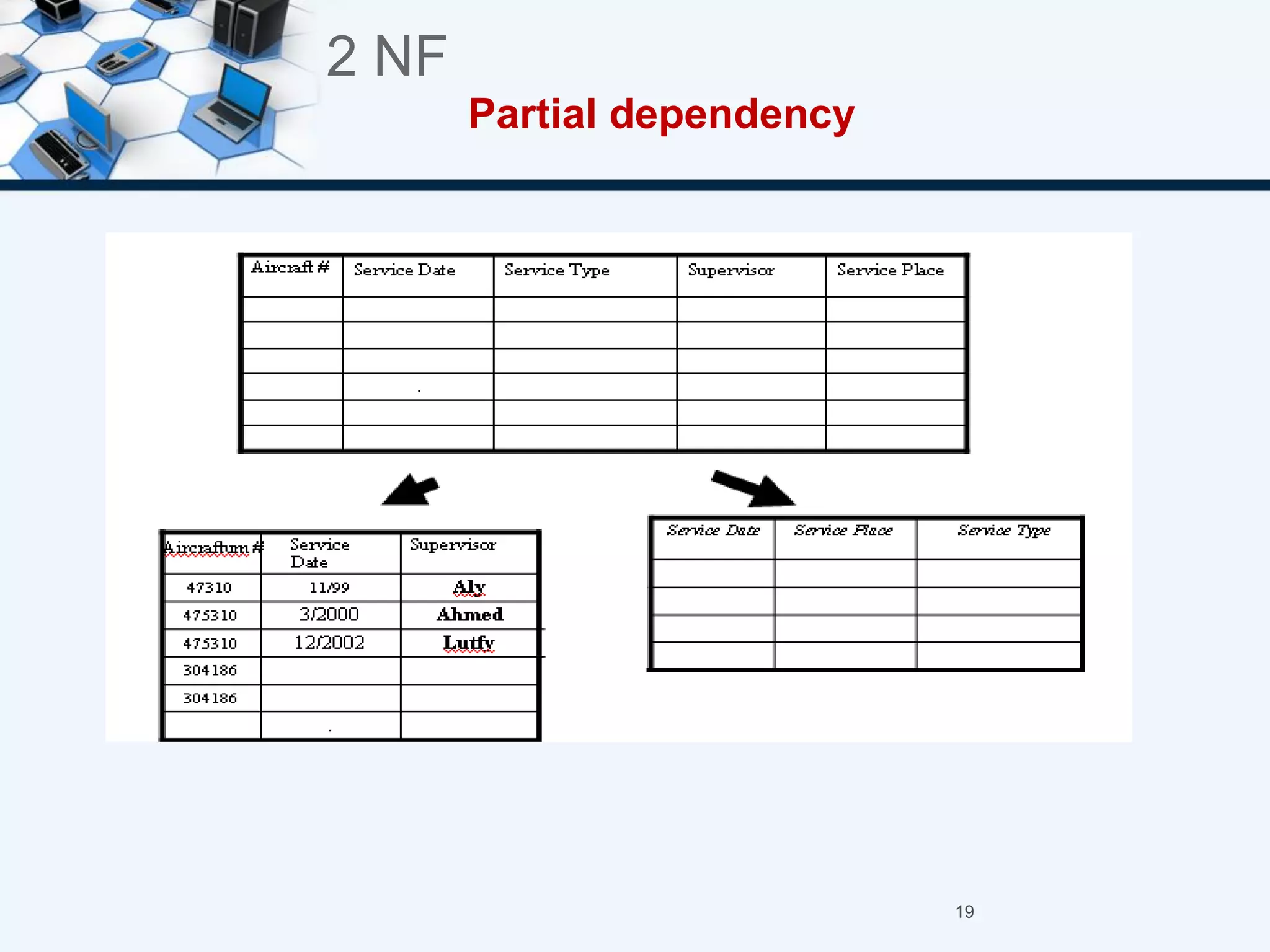
3. The three normal forms - first, second, and third - and how to achieve each by removing certain types of dependencies between attributes.
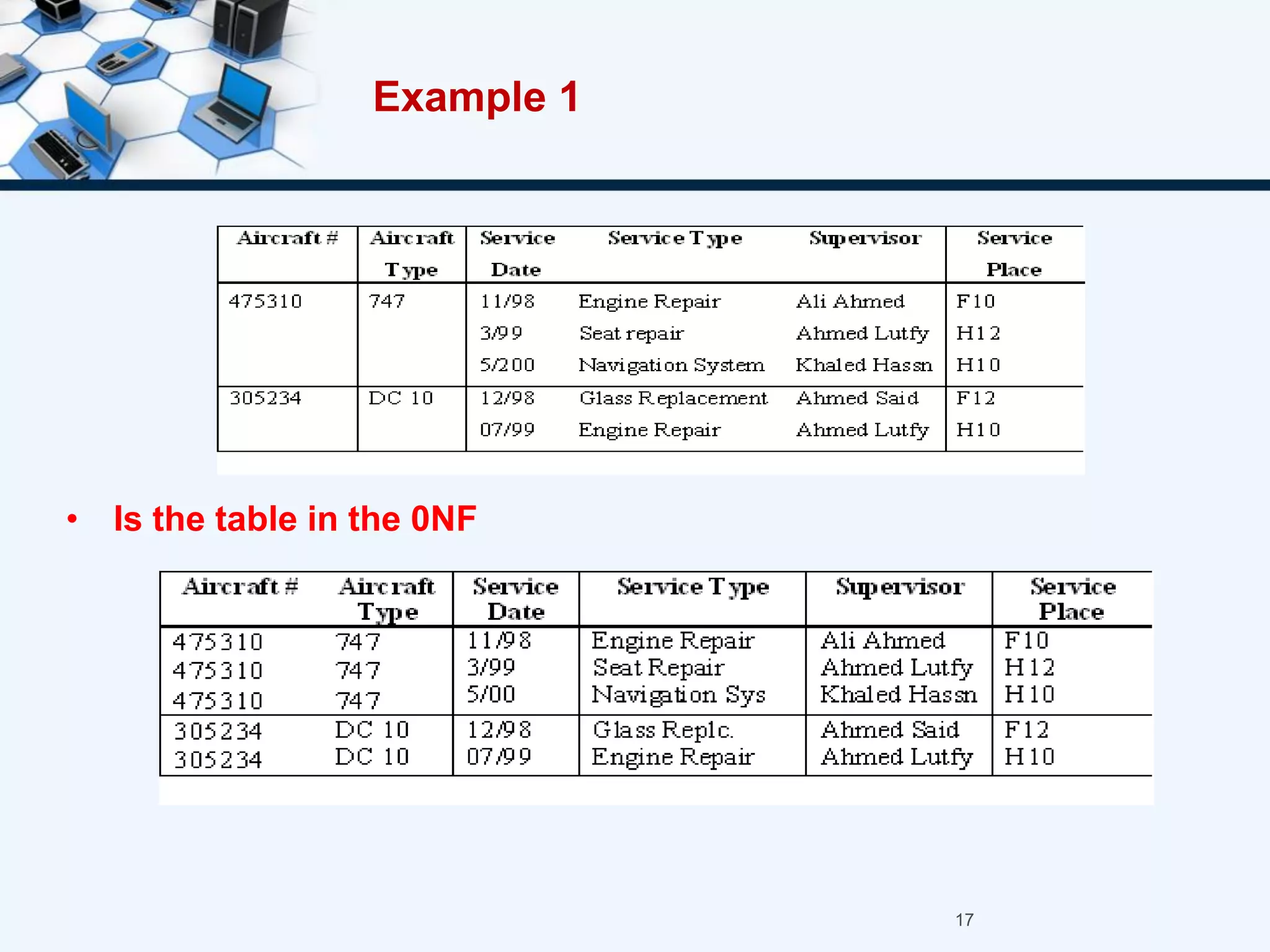
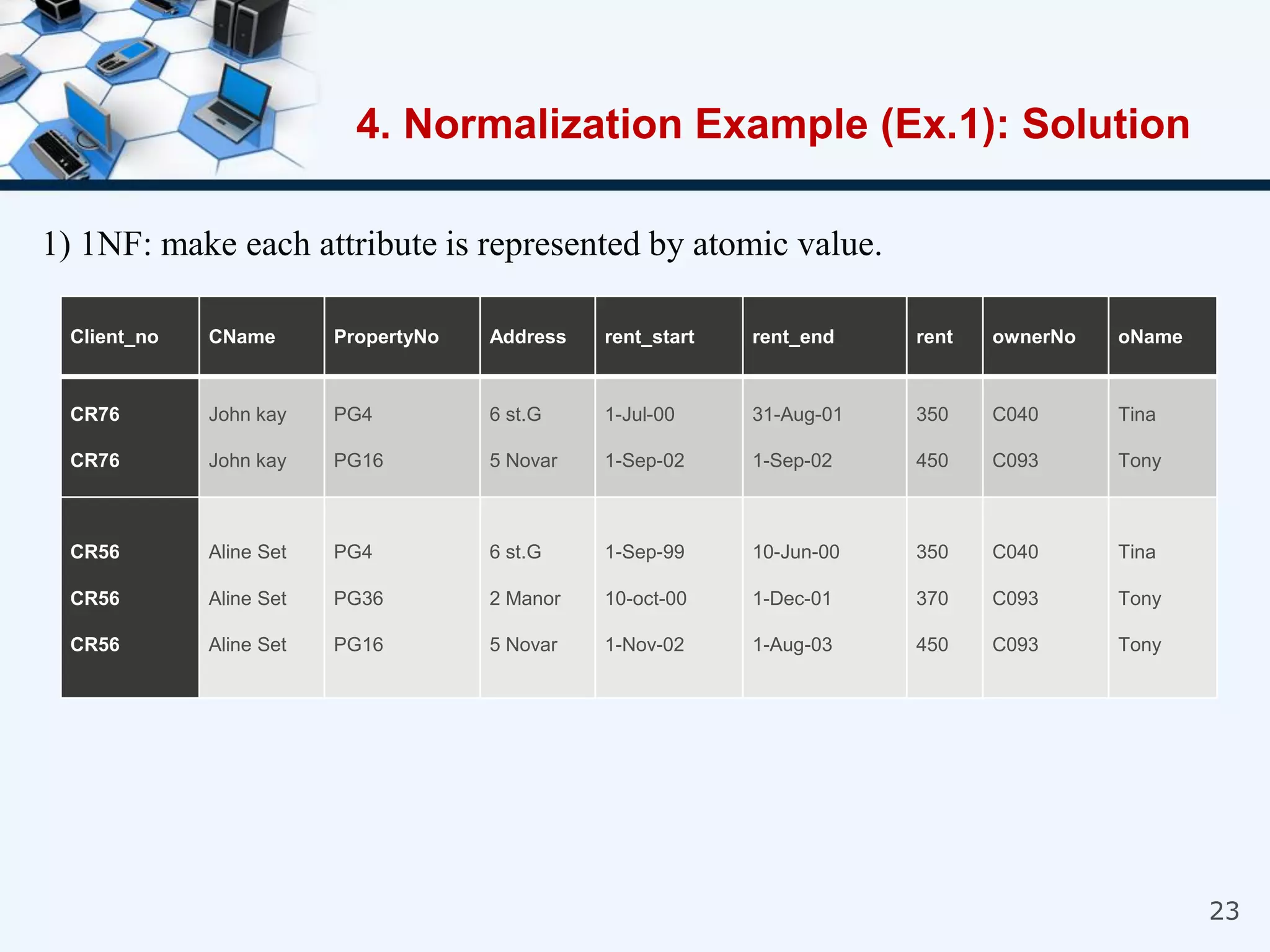
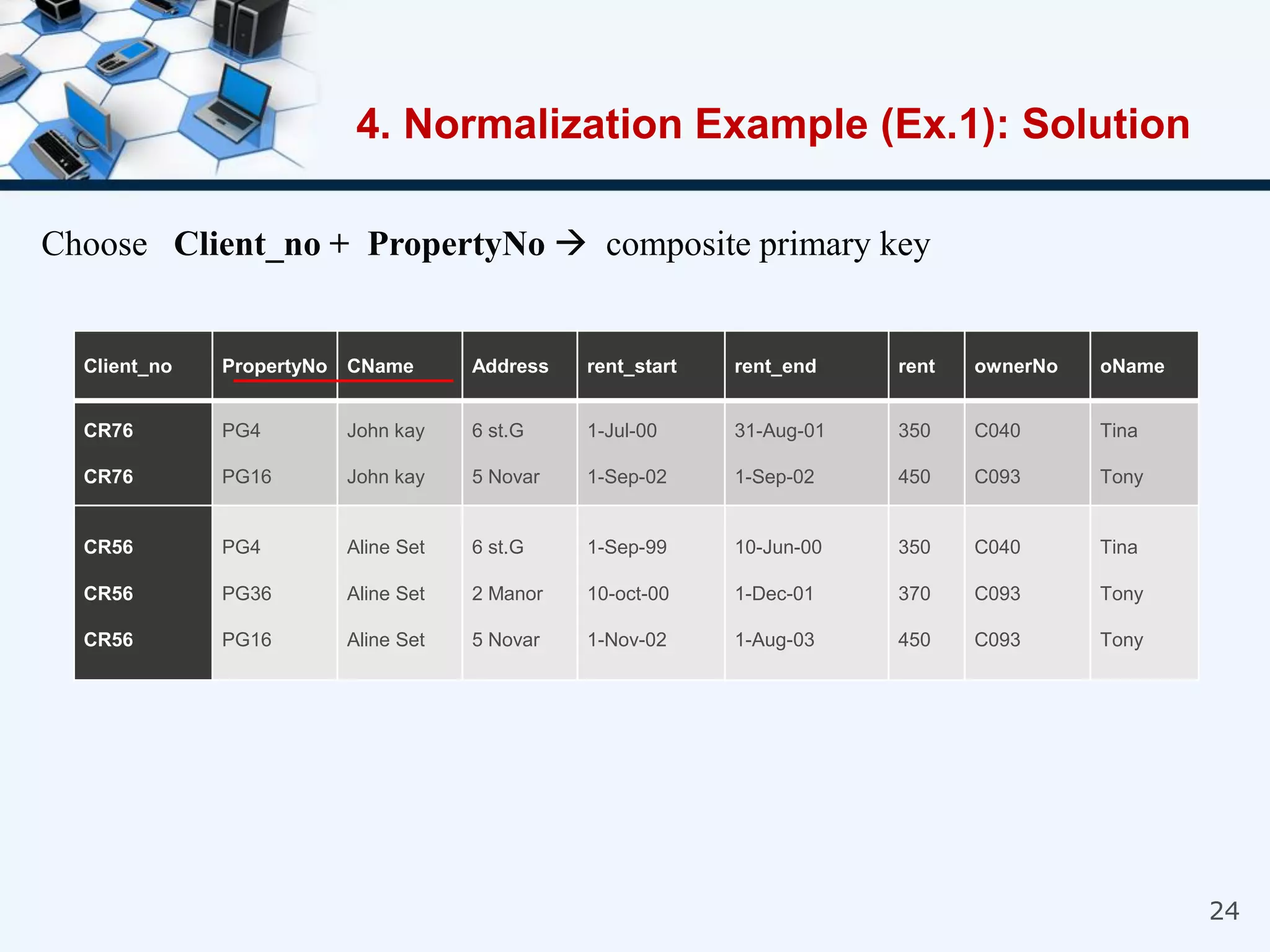
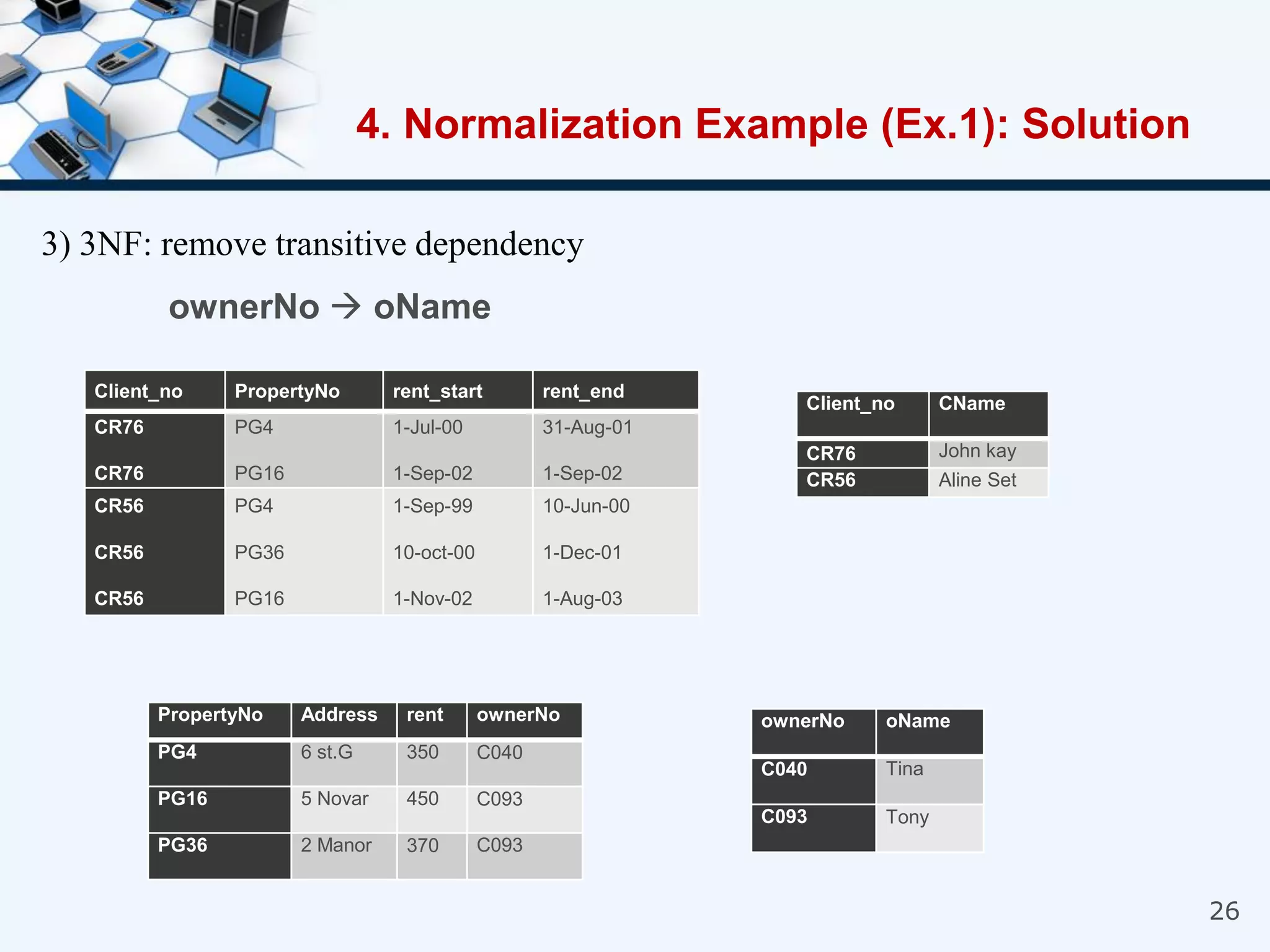
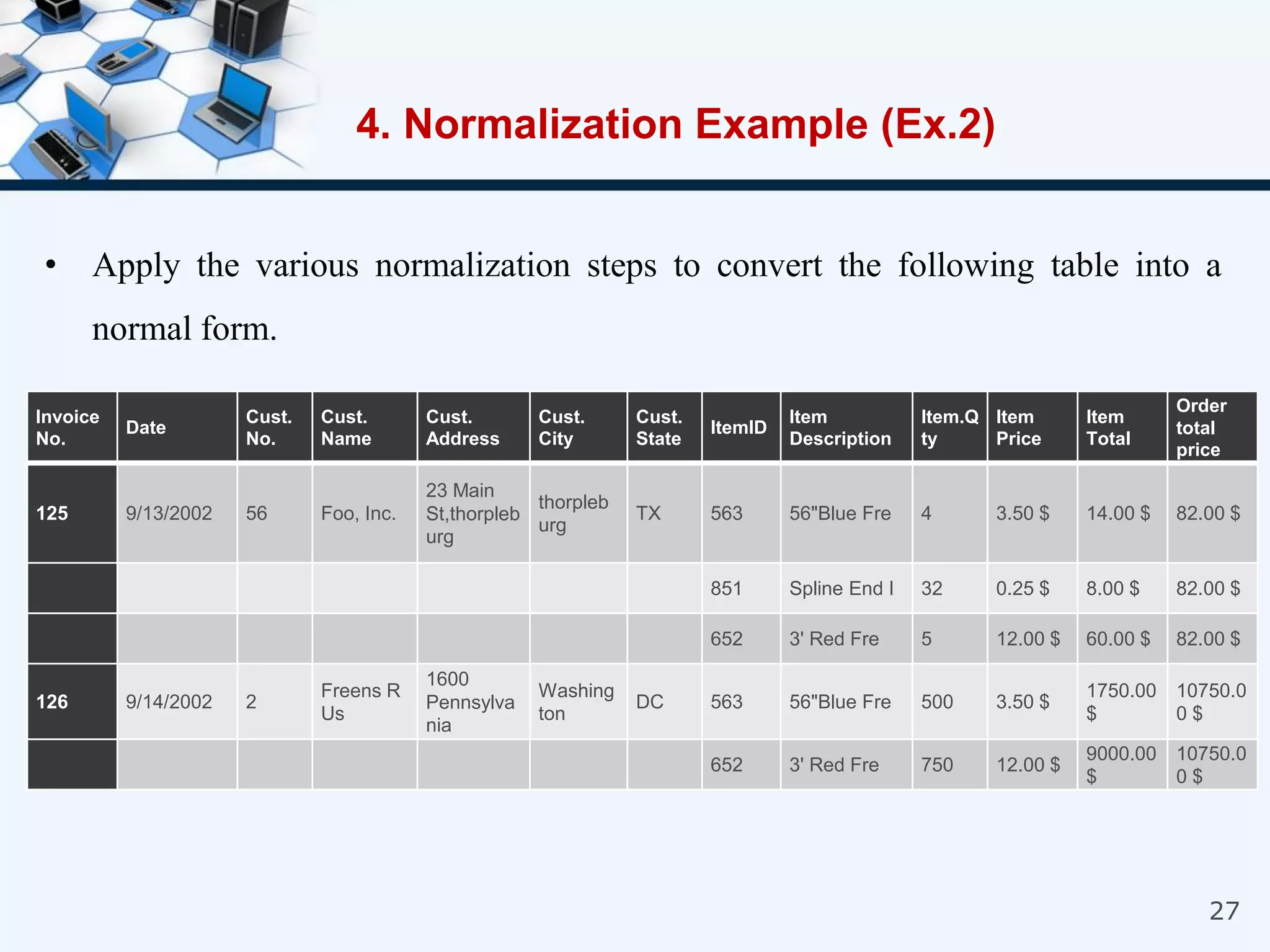
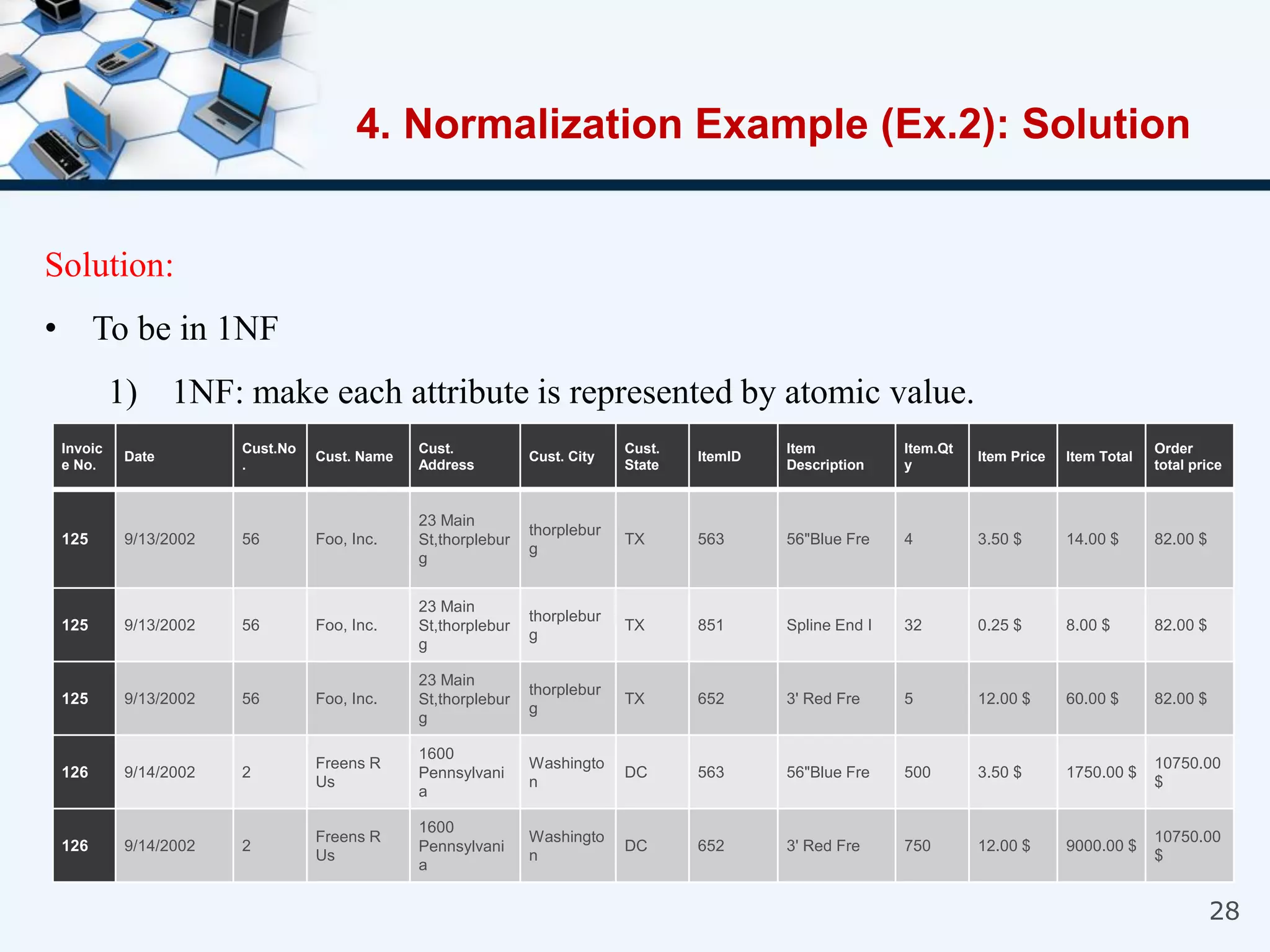
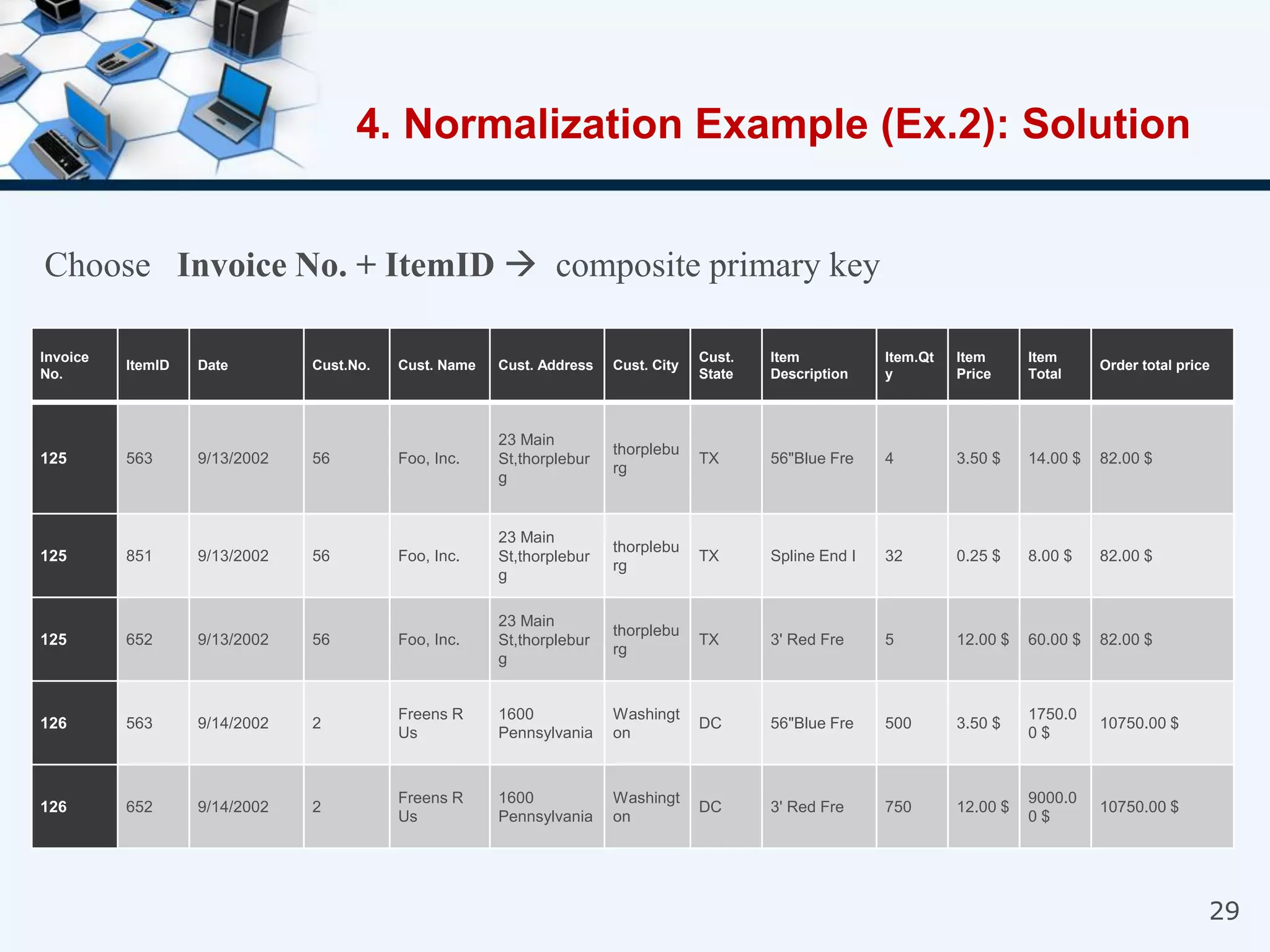
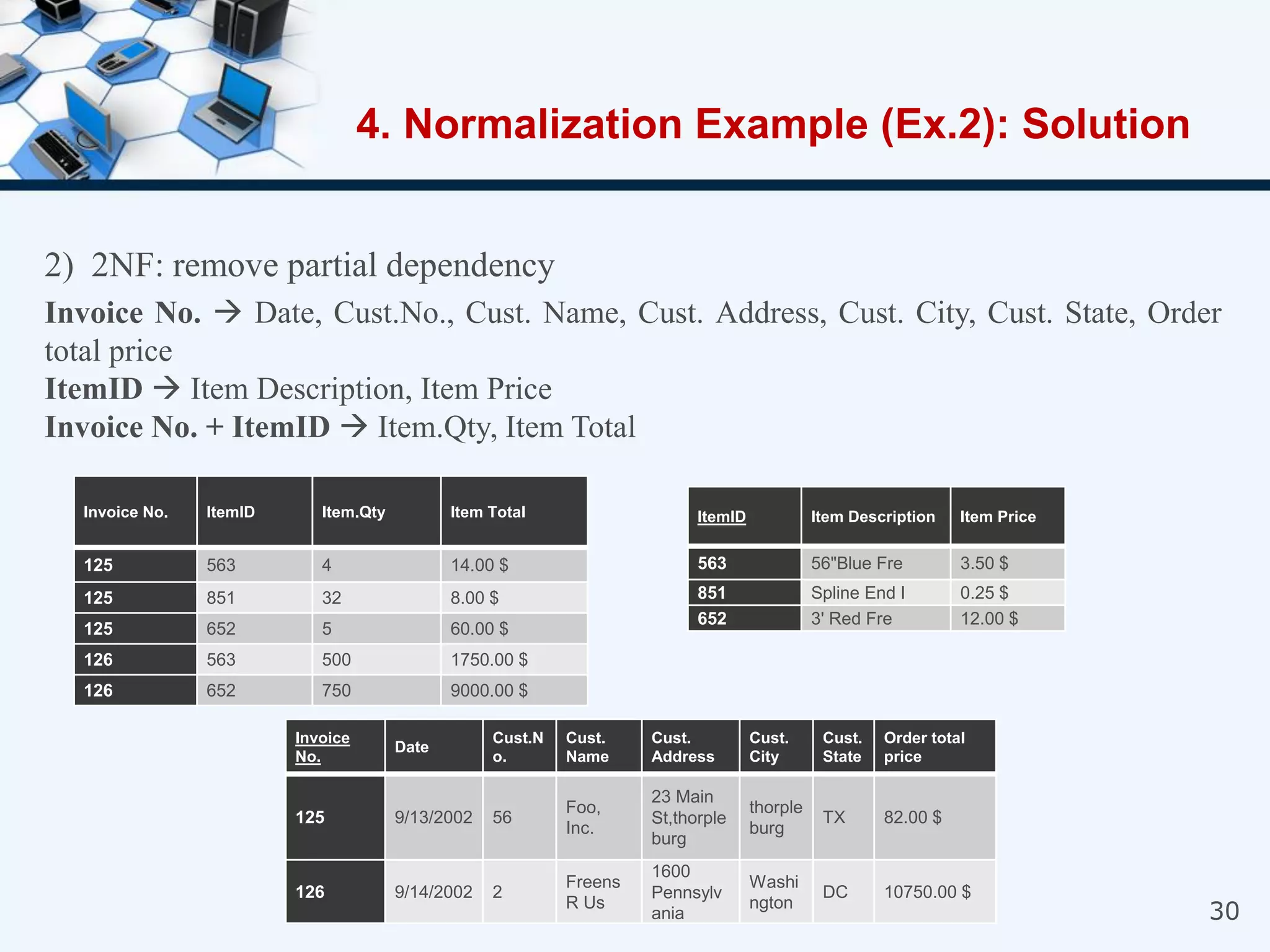
4. An example of normalizing a table through a three-step process to convert it into third normal form.