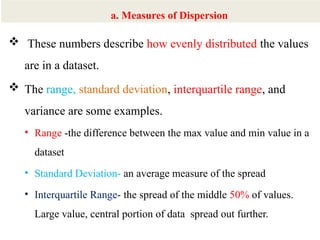
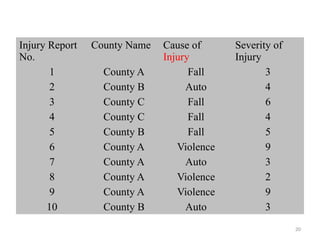
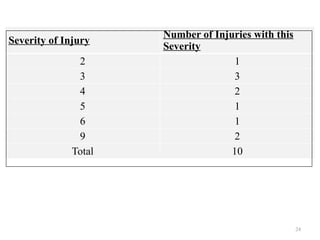
The document provides an overview of univariate analysis, a basic statistical technique focusing on a single variable without examining relationships. It discusses key concepts such as descriptive statistics, measures of central tendency and dispersion, and methods for visual representation including bar charts, histograms, and pie charts. The document emphasizes the importance of univariate analysis in summarizing data and identifying patterns for further analysis.


































![3. PTDL_Chapter 3 Descriptive Statistics [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/3-250315040432-1773461d-thumbnail.jpg?width=640&height=640&fit=bounds)