Downloaded 27 times






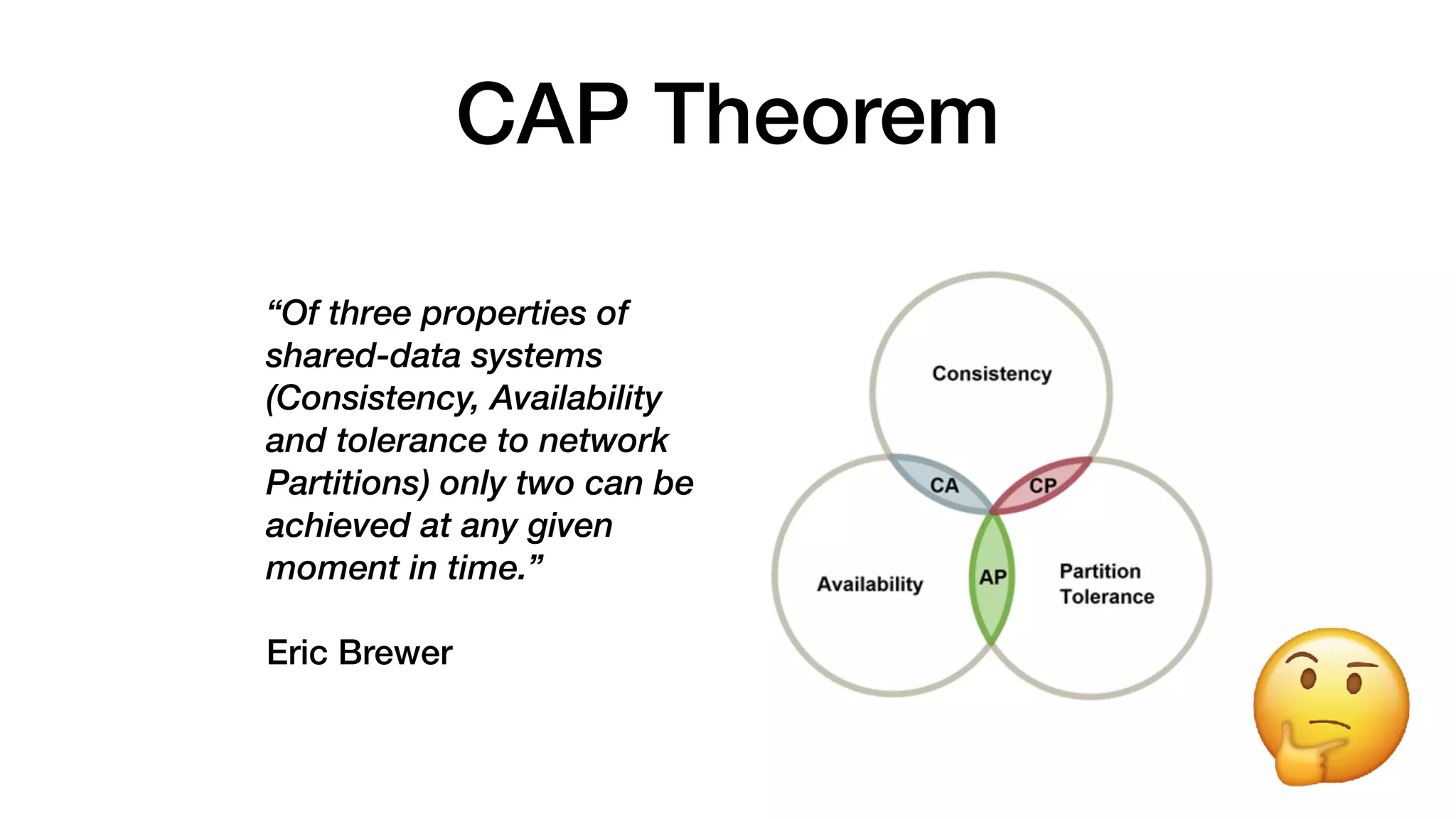










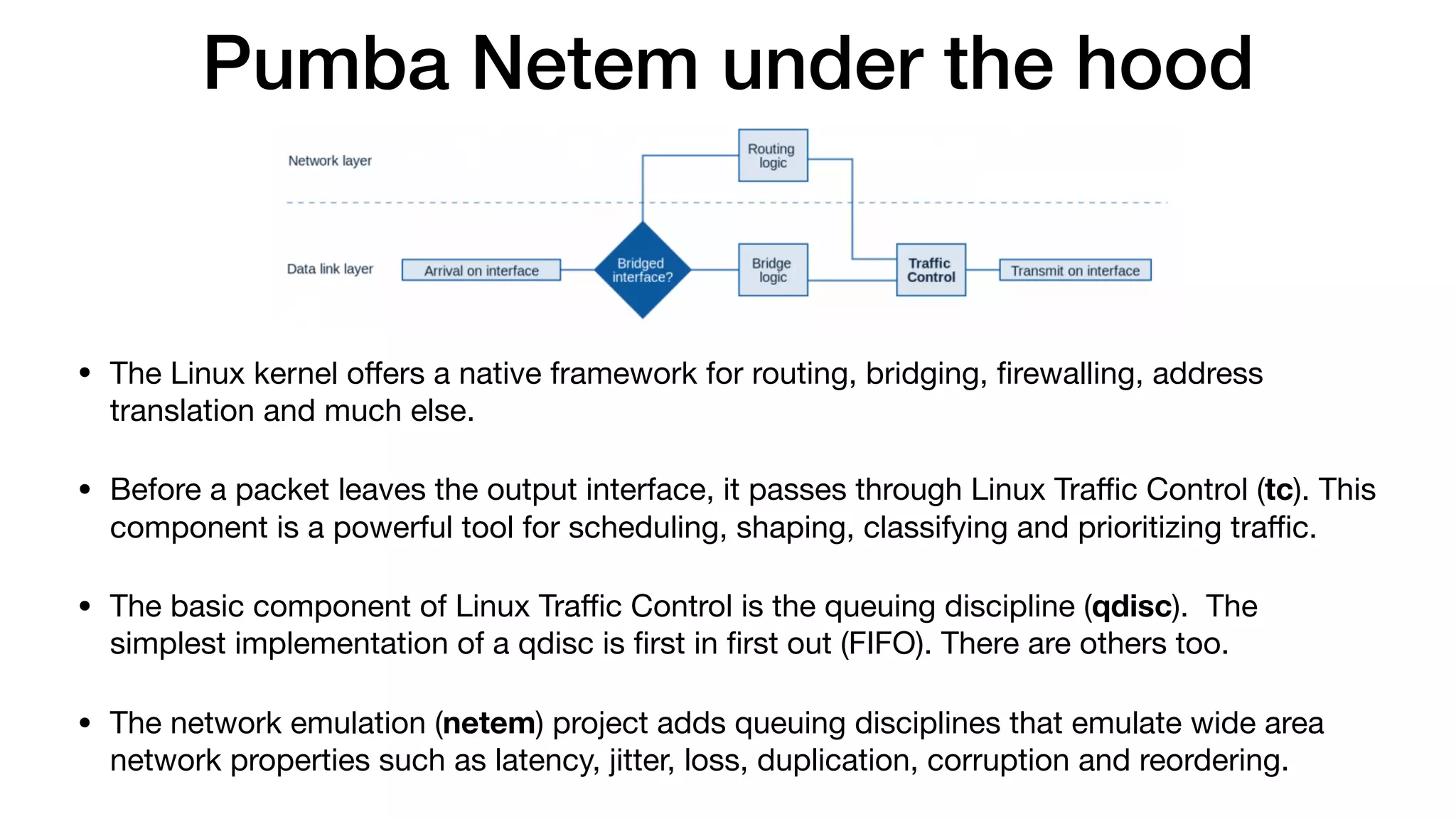



The document discusses chaos testing for Docker containers, highlighting the importance of resilience in complex software systems and the potential for failure. It introduces Pumba, an open-source tool for chaos testing that injects various types of failures into Docker environments, allowing users to test system weaknesses. The document also provides command examples for disrupting containers and emulating network failures using Pumba.





![[AWSマイスターシリーズ] Instance Store & Elastic Block Store](https://cdn.slidesharecdn.com/ss_thumbnails/20140129aws-meister-reloaded-ephemeral-ebs-public-140130055222-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





![[Gaming on AWS] AWS와 함께 한 쿠키런 서버 Re-architecting 사례 - 데브시스터즈](https://cdn.slidesharecdn.com/ss_thumbnails/6-140305055030-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






















































