Download as PDF, PPTX




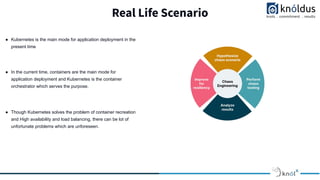
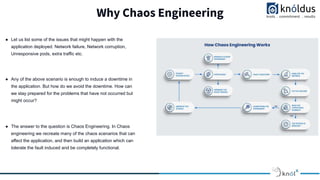

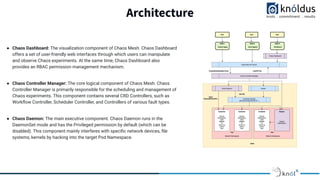




The document discusses a presentation on chaos engineering in Kubernetes, emphasizing the importance of etiquette during sessions, such as punctuality and constructive feedback. Chaos engineering aims to simulate failures to help engineers create fault-tolerant applications and is facilitated by tools like Chaos Mesh, which allows for customized experiments. The architecture of Chaos Mesh includes components like the chaos dashboard, chaos controller manager, and chaos daemon, which together provide robust mechanisms for conducting chaos experiments.






















































































