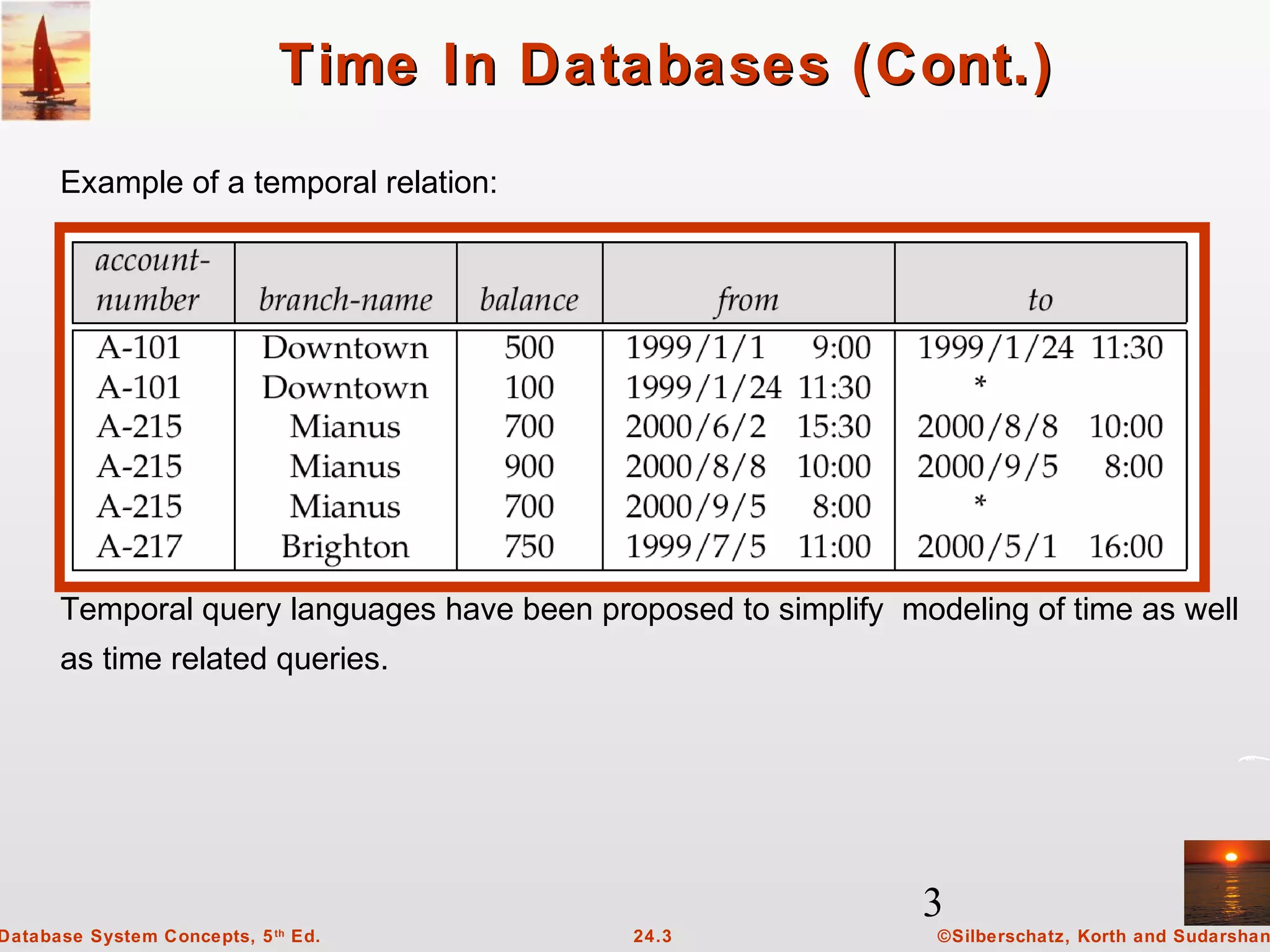
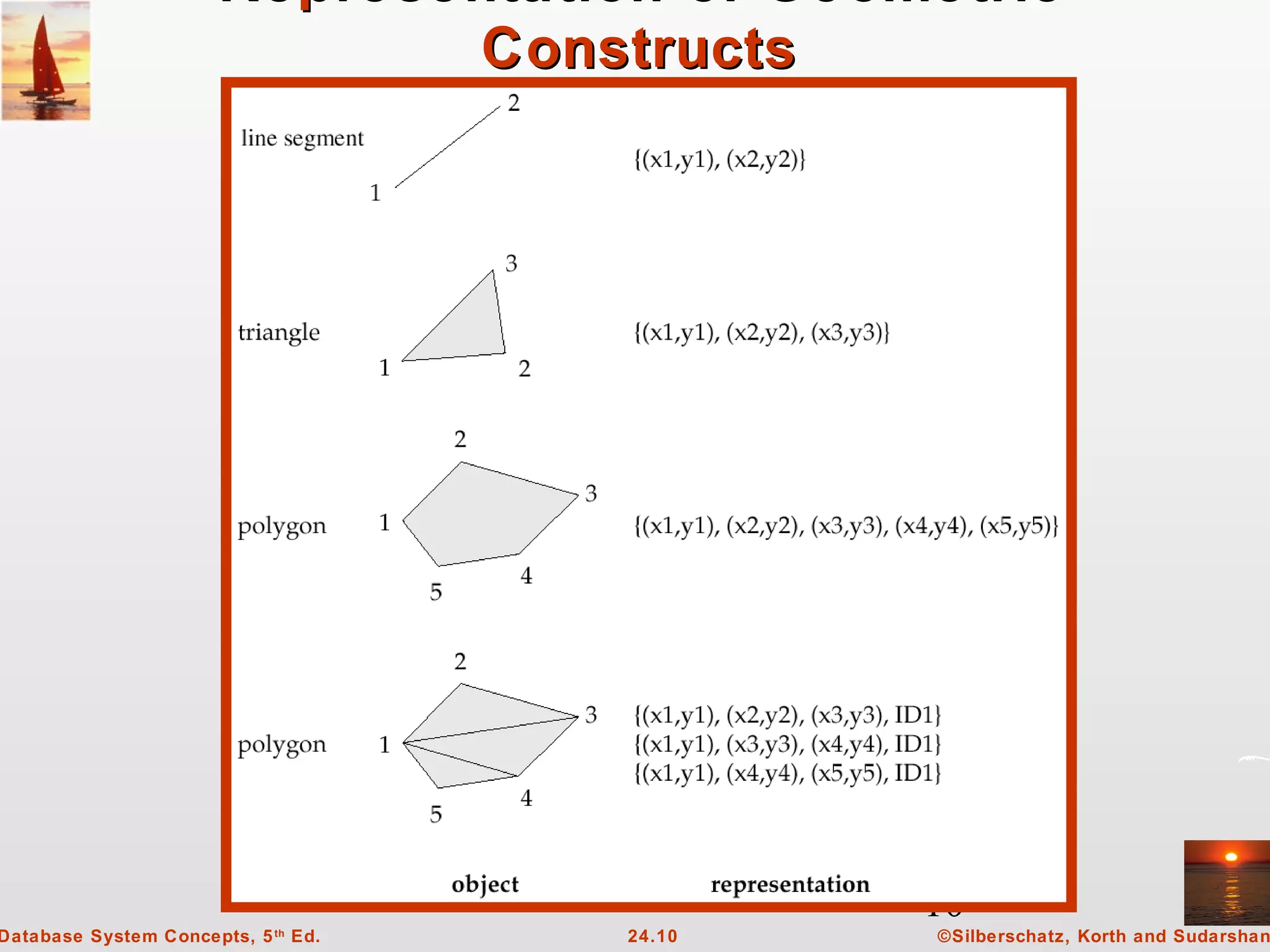
This document discusses temporal data and time in databases. It explains that temporal databases model states of the real world across time by associating times when facts are valid. Facts can have valid times or transaction times. Bi-temporal relations store both valid and transaction times. The document also discusses SQL specifications for time, temporal query languages, and challenges with temporal functional dependencies.









































![44
©Silberschatz, Korth and Sudarshan24.44Database System Concepts, 5th
Ed.
Detecting Inconsistent UpdatesDetecting Inconsistent Updates
Version vector scheme used to detect inconsistent updates to documents
at different hosts (sites).
Copies of document d at hosts i and j are inconsistent if
1. the copy of document d at i contains updates performed by host k
that have not been propagated to host j (k may be the same as i),
and
2. the copy of d at j contains updates performed by host l that have not
been propagated to host i (l may be the same as j)
Basic idea: each host i stores, with its copy of each document d, a
version vector - a set of version numbers, with an element Vd,i[k] for
every other host k
When a host i updates a document d, it increments the version number Vd,i
[i] by 1](https://image.slidesharecdn.com/ch24-150505194228-conversion-gate01/75/Ch24-44-2048.jpg)
![45
©Silberschatz, Korth and Sudarshan24.45Database System Concepts, 5th
Ed.
Detecting Inconsistent Updates (Cont.)Detecting Inconsistent Updates (Cont.)
When two hosts i and j connect to each other they check if the copies of
all documents d that they share are consistent:
1. If the version vectors are the same on both hosts (that is, for each k,
Vd,i[k]= Vd,j [k]) then the copies of d are identical.
2. If, for each k, Vd,i [k] ≤ Vd,j[k], and the version vectors are not
identical, then the copy of document d at host i is older than the one
at host j
That is, the copy of document d at host j was obtained by one
or more modifications of the copy of d at host i.
Host i replaces its copy of d, as well as its copy of the version
vector for d, with the copies from host j.
3. If there is a pair of hosts k and m such that Vd,i [k]< Vd,j [k], and
Vd,i [m] > Vd,j [m], then the copies are inconsistent
That is, two or more updates have been performed](https://image.slidesharecdn.com/ch24-150505194228-conversion-gate01/75/Ch24-45-2048.jpg)




















































![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Uros Pesic - The Reality of AI in Marketing.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtkodnmtycovsllvzsyn-9-251215095918-b0c6bfe3-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)

