Categorization Of Major
ClusteringMethods
Presented by,
C.Dhivyasri
I-M.Sc(Computer science)
Nadar Saraswathi College of Arts and Science
2.
Definition of clusteringmethods
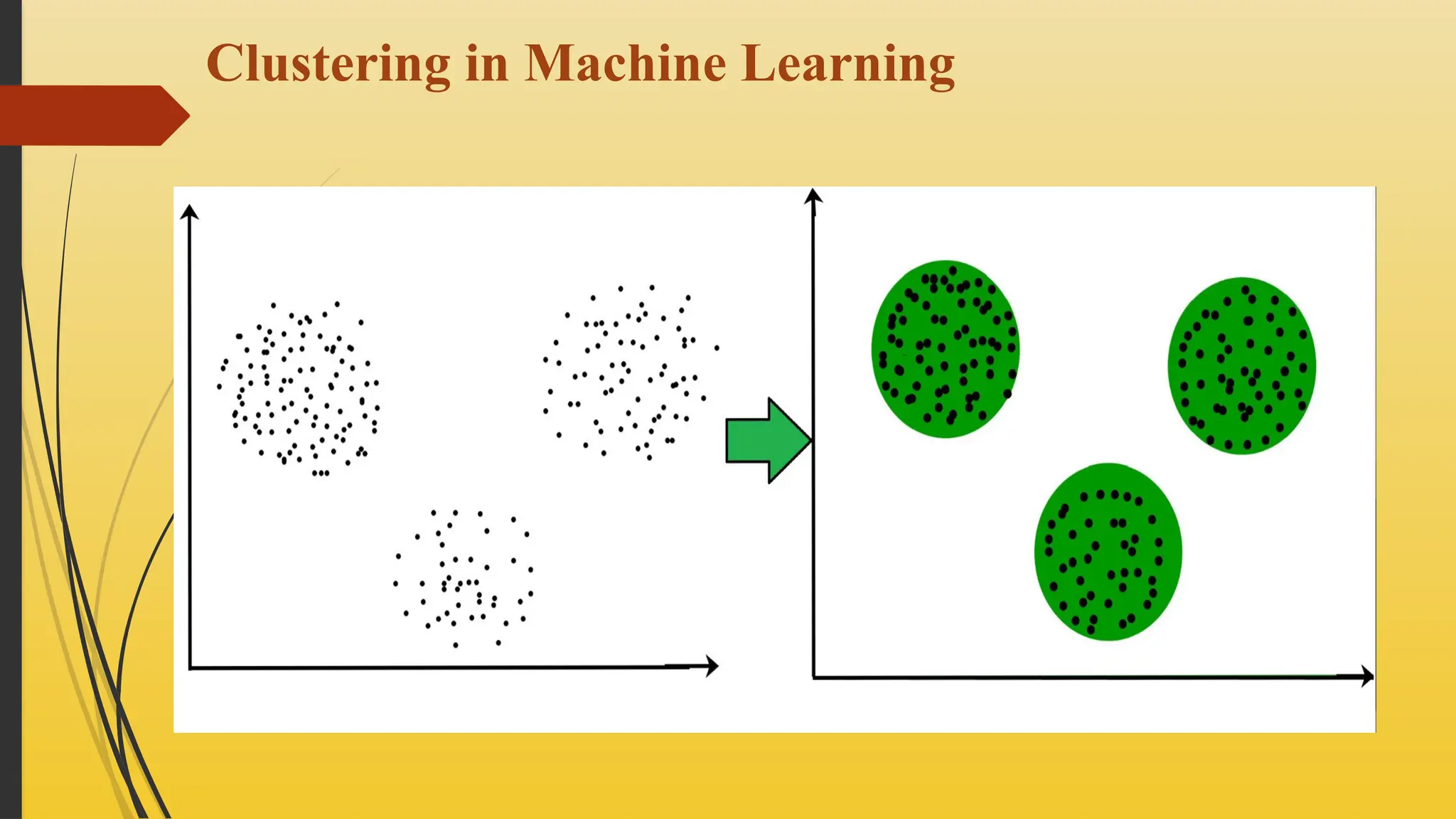
Clustering methods are unsupervised machine learning techniques that group
unlabeled data points into clusters based on their inherent similarities, using
various algorithms and similarity measures to identify statistically validated
subgroups within datasets.
These techniques are used in various fields, including market research and
healthcare, to find natural patterns and categorize data into meaningful
segments for analysis and strategic decision-making.
Types of ClusteringMethods
At the surface level, clustering helps in the analysis of unstructured
data. Graphing, the shortest distance, and the density of the data points are a
few of the elements that influence cluster formation.
Centroid-based Clustering (Partitioning methods)
Density-based Clustering (Model-based methods)
Connectivity-based Clustering (Hierarchical clustering)
5.
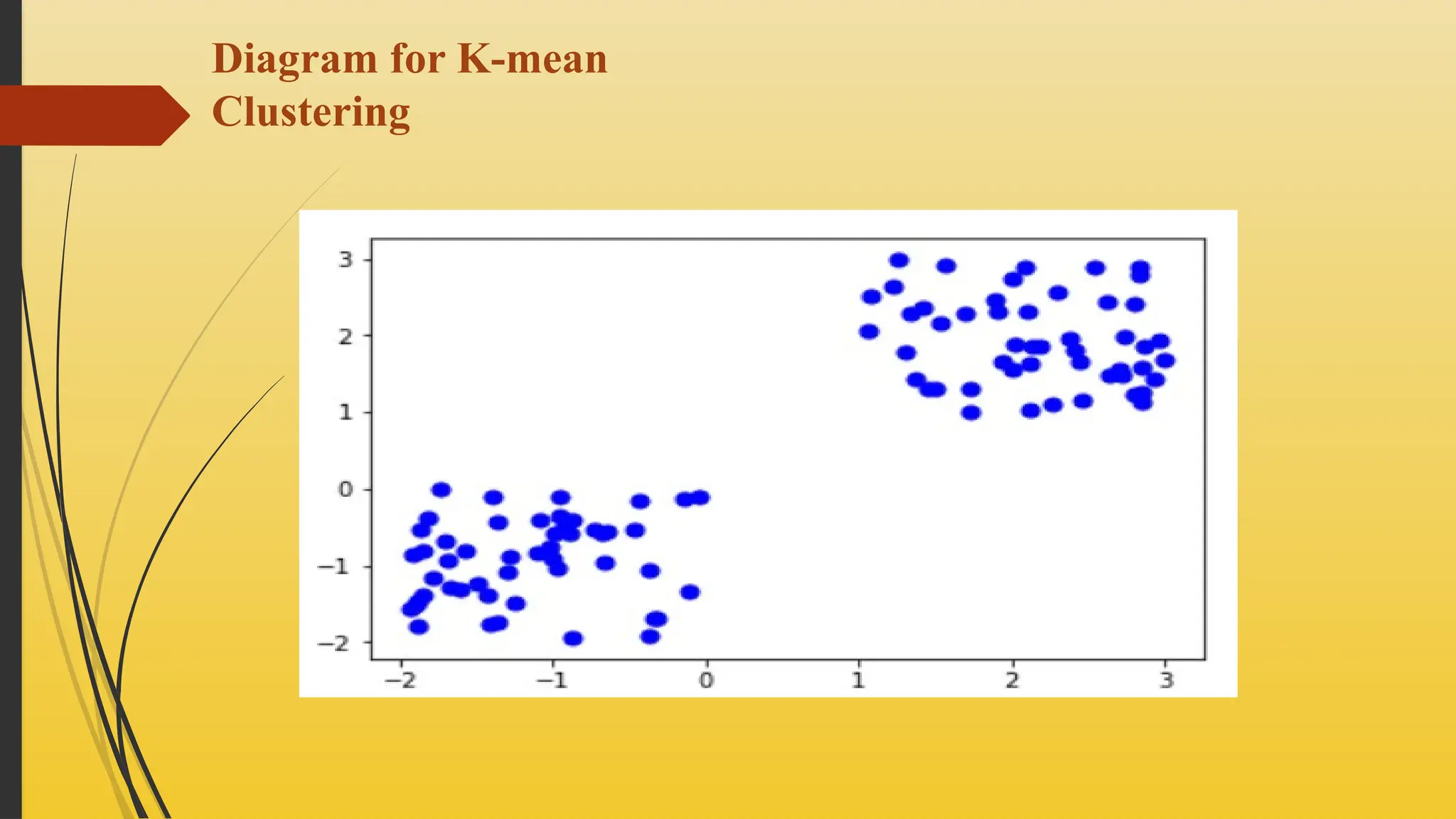
Centroid-based Clustering
(Partitioning methods)
Centroid-based clustering organizes data points around central vectors
(centroids) that represent clusters. Each data point belongs to the cluster with
the nearest centroid. Generally, the similarity measure chosen for these
algorithms are Euclidian distance, Manhattan Distance or Minkowski Distance.
The datasets are separated into a predetermined number of clusters, and each
cluster is referenced by a vector of values. When compared to the vector value,
the input data variable shows no difference and joins the cluster.
6.
Popular Algorithms
K-means:
Thisis the most widely known centroid-based algorithm. It aims to
minimize the sum of squared distances between data points and their respective
cluster centroids.
K-medoids (PAM - Partitioning Around Medoids):
Unlike K-means, K-medoids uses an actual data point (medoid) as the
cluster center, making it more robust to outliers than K-means.
7.
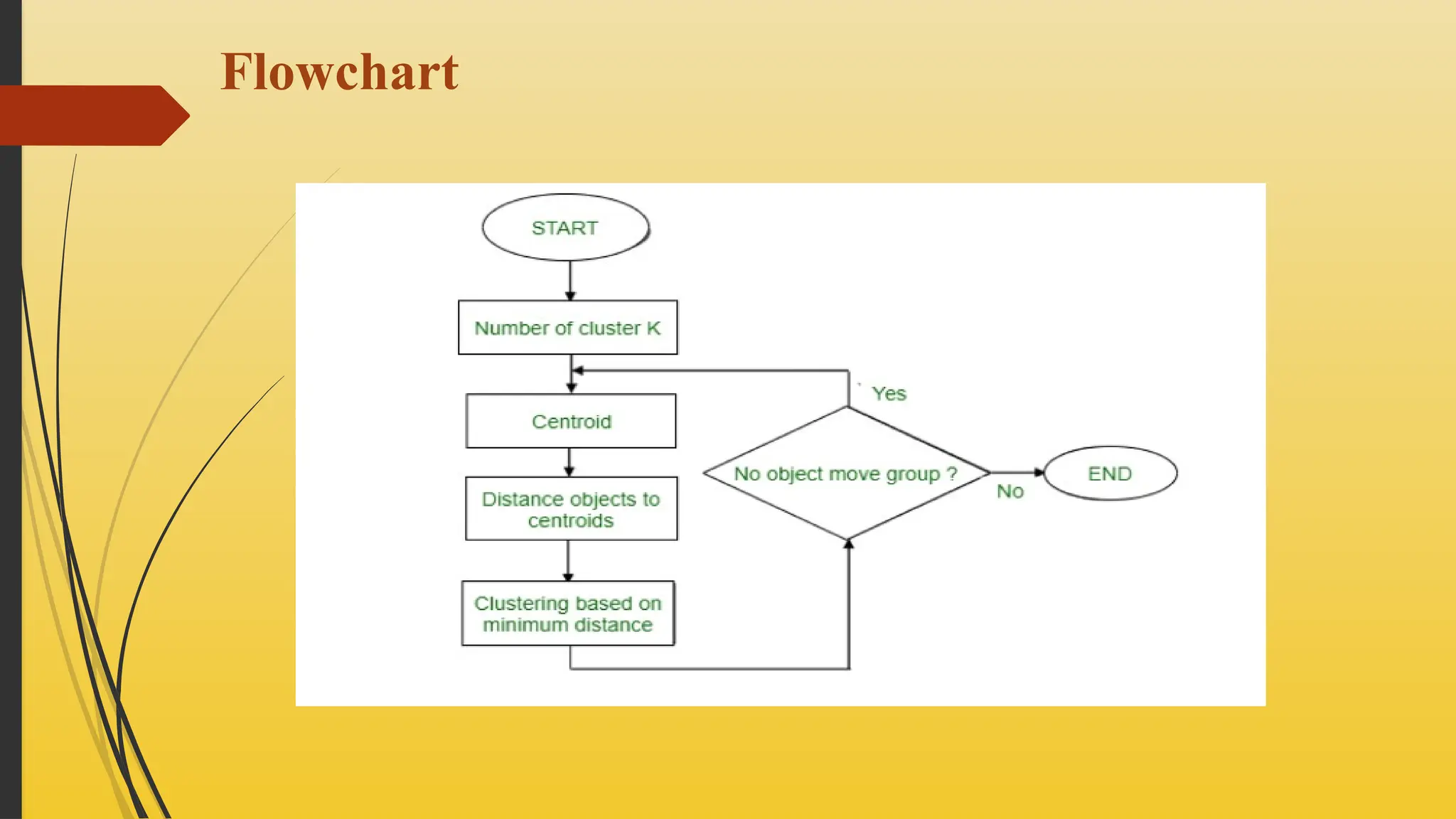
K-mean Algorithm
METHODS
Randomlyassign K objects from the dataset(D) as cluster centres(C)
(Re) Assign each object to which object is most similar based upon mean
values.
Update Cluster means, i.e., Recalculate the mean of each cluster with the
updated values.
Repeat Step 2 until no change occurs.
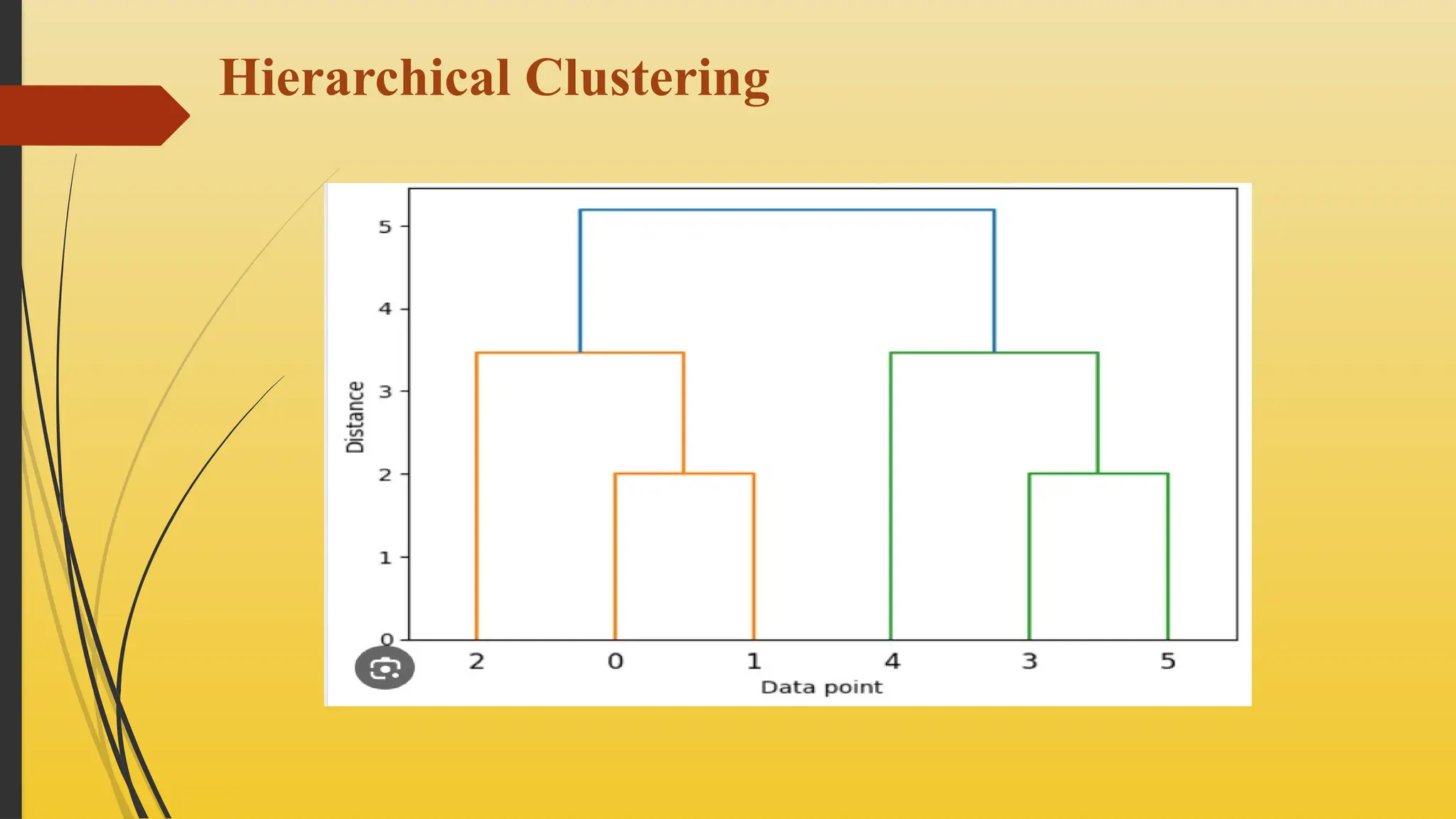
Connectivity-based Clustering
(Hierarchical clustering)
Connectivity-based clustering builds a hierarchy of clusters using a measure of
connectivity based on distance when organizing a collection of items based on
their similarities.
This method builds a dendrogram, a tree-like structure that visually represents the
relationships between objects.
The key idea is that nearby objects are more related than distant ones, and the final
cluster hierarchy is determined by a chosen distance metric and a linkage
criterion.
Types of HierarchicalClustering
There are two main types of hierarchical clustering.
Agglomerative Hierarchical Clustering (Bottom-Up)
Divisive Hierarchical Clustering (Top-Down)
13.
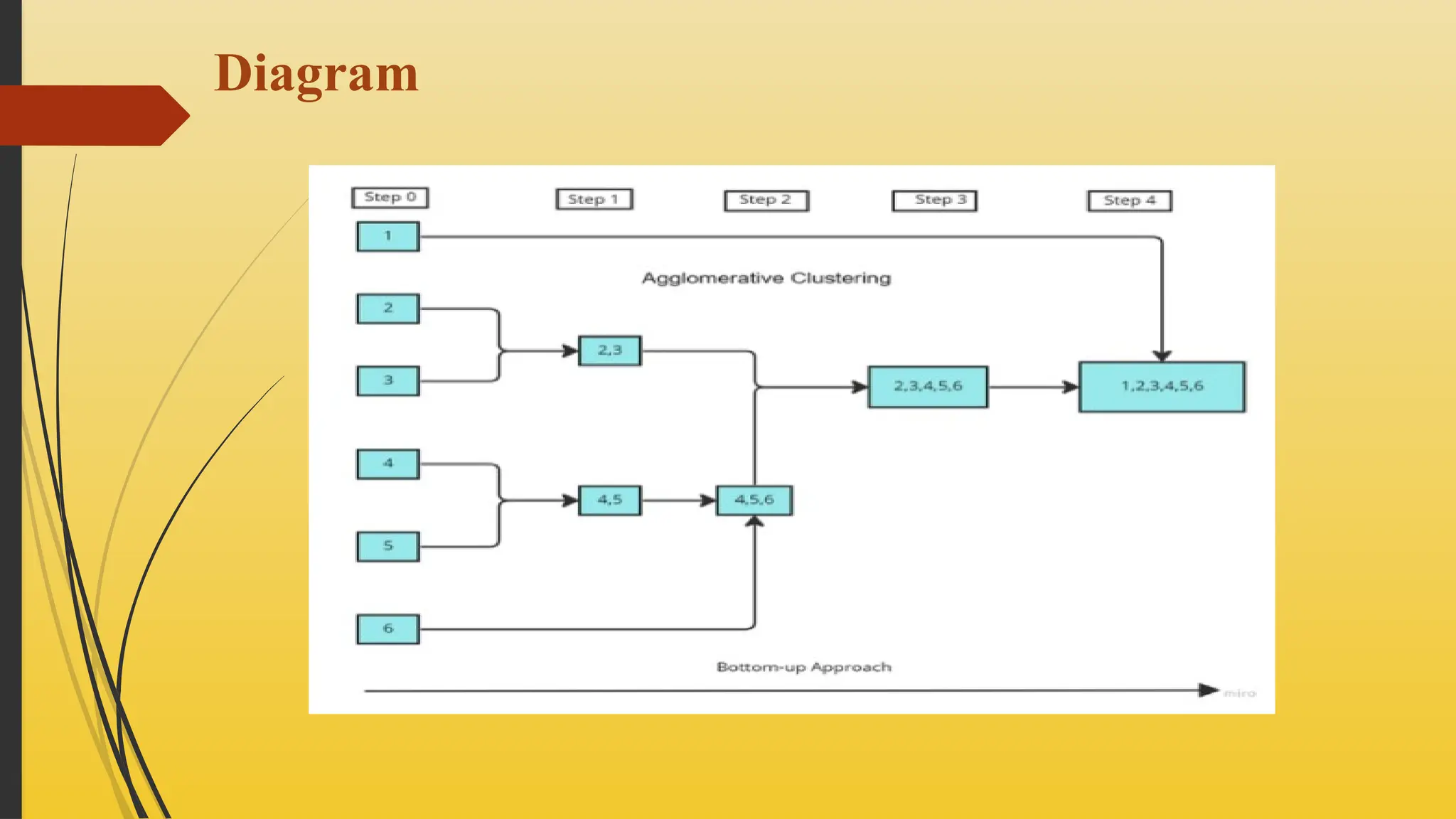
1.Agglomerative Hierarchical
Clustering (Bottom-Up)
This method begins by treating each individual data point as a separate cluster.
It then iteratively merges the two closest clusters at each step.
This merging process continues until all data points are grouped into a single,
large cluster.
The "closeness" or "similarity" between clusters is determined by a chosen
linkage criterion (e.g., single linkage, complete linkage, average linkage, Ward's
method).
Advantages
No PredefinedK: Unlike algorithms like K-Means, it doesn't require
specifying the number of clusters (K) beforehand.
Visual Insights: The resulting dendrogram offers a rich, hierarchical view
of the data's structure.
Flexibility: It allows for various distance metrics and linkage methods to be
used.
16.
Disadvantages
Computational Cost:
Itcan be computationally expensive and slow for very large datasets
due to its O(n²) complexity.
Sensitivity:
It can be sensitive to noisy data and outliers, and once a merge is
done, it cannot be undone.
17.
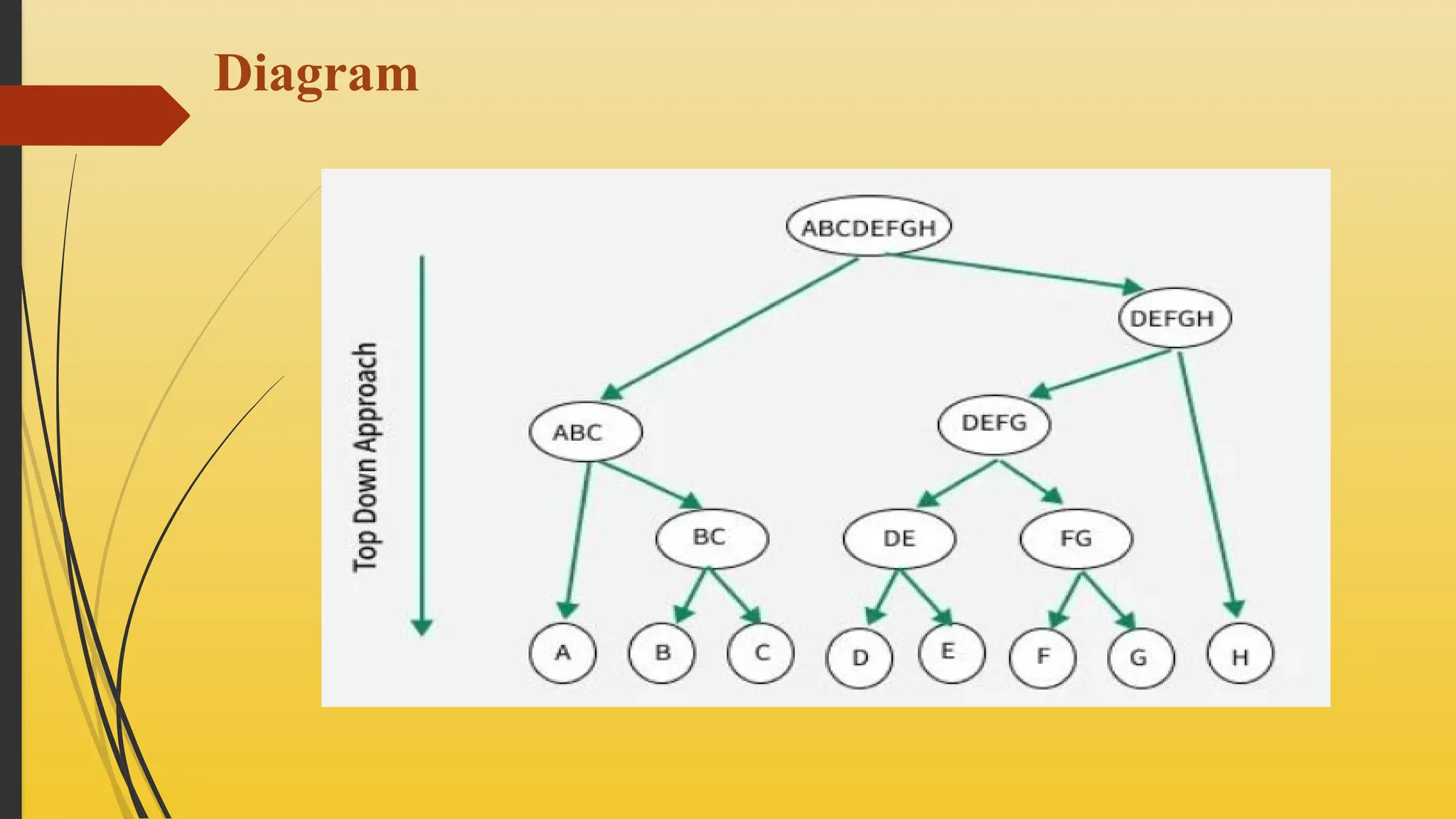
2.Divisive Hierarchical
Clustering (Top-Down)
Divisive Hierarchical Clustering (Top-Down Clustering) is a method that
starts with all data points in a single cluster and recursively splits it into
smaller, more homogeneous clusters.
Unlike the bottom up Agglomerative approach, divisive clustering breaks
down broad categories into smaller groups by identifying the most dissimilar
points or clusters to split at each step.
This top-down process continues until a stopping condition is met, such as
each data point forming its own cluster.