2
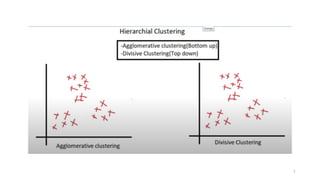
• Divisive approachis a top-down approach.
• Start with one, all-inclusive cluster.
• Smaller clusters are created by splitting the group by using the
continuous iteration.
• Split until each cluster contains a point.
– Cannot undo after the group is split or merged, and that is
why this method is not so flexible.
*
DIVISIVE APPROACH
17
*
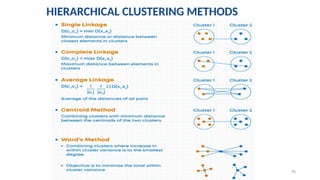
Minimum or Single-Linkage(Nearest Neighbor)
Shortest distance between a pair of observations in two clusters. It tends to
produce long, “loose” clusters.
Maximum or Complete-Linkage (Farthest Neighbor)
Distance measured between the farthest pair of observations in two clusters.
This method usually produces “tighter” clusters than single-linkage.
Mean or Average-Linkage
Computes all pairwise dissimilarities between the elements in cluster 1 and
the elements in cluster 2, and considers the average of these
dissimilarities as the distance between the two clusters.
Centroid-Linkage
Computes the dissimilarity between the centroid for cluster 1 (a mean vector
of length p variables) and the centroid for cluster 2.
Ward’s Minimum Variance Method:
Minimizes the total within-cluster variance. At each step the pair of clusters
with minimum between-cluster distance are merged.
HIERARCHICAL CLUSTERING METHODS
18.
18
*
HIERARCHICAL CLUSTERING METHODS
•Starts with one cluster, individual item in its own cluster and
iteratively merge clusters until all the items belong to one
cluster.
• Bottom up approach is followed to merge the clusters
together.
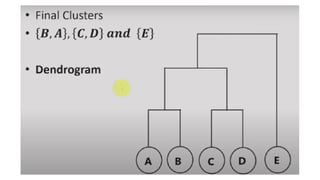
• Dendrograms are pictorially used to represent the
Hierarchical Agglomerative Clustering (HAC).
• HAC groups similar data points together step-by-
step to form a hierarchy of clusters.
• It starts with each point as its own cluster and
merges the closest clusters one by one until all
points are in a single big cluster.
Single Linkage Clustering
HIERARCHICAL CLUSTERING METHODS
19.
19
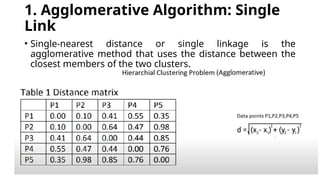
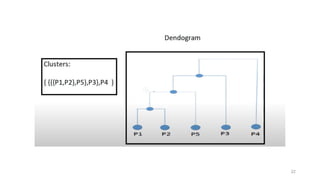
1. Agglomerative Algorithm:Single
Link
• Single-nearest distance or single linkage is the
agglomerative method that uses the distance between the
closest members of the two clusters.
23
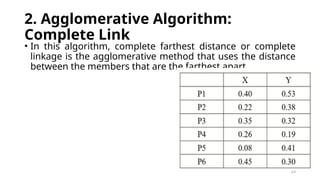
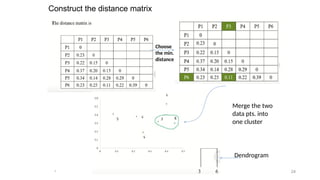
2. Agglomerative Algorithm:
CompleteLink
• In this algorithm, complete farthest distance or complete
linkage is the agglomerative method that uses the distance
between the members that are the farthest apart.
35
*
• The heightin the dendrogram at which two clusters are merged
represents the Distance between two clusters in the data space.
• The decision of merging two clusters is taken on the basis of
closeness of these clusters. There are multiple metrics for
deciding the closeness of two clusters. (Distance).
• The red horizontal line in the dendrogram below covers
maximum vertical distance AB.
• Hierarchical clustering, as the name suggests is an algorithm that
builds hierarchy of clusters.
HIERARCHICAL CLUSTERING (1/2)
36.
36
*
• This algorithmstarts with all the data points assigned to a cluster
of their own.
• Then two nearest clusters are merged into the same cluster. In
the end, this algorithm terminates when there is only a single
cluster left.
HIERARCHICAL CLUSTERING (2/2)
37.
37
*
Advantages:
•We can obtainthe optimal (desired) number of clusters from
the model itself, human intervention not required.
•Dendrograms help us in clear visualization, which is practical
and easy to understand.
Disadvantages:
•Not suitable for large datasets due to high time and space
complexity.
•In hierarchical Clustering, once a decision is made to combine
two clusters, it can not be undone.
•The time complexity for the clustering can result in very
long computation times.
HIERARCHICAL CLUSTERING
38.
38
a. Search EngineResult Grouping.
b. Document Clustering.
c. Banking and Insurance fraud detection.
d. Image Segmentation.
e. Customer Segmentation.
f. Recommendation Engines.
g. Social Network Analysis.
h. Network Traffic Analysis.
*
APPLICATIONS OF CLUSTERING
Editor's Notes
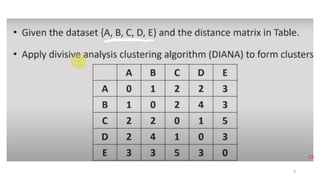
#2 Hence, iteratively, we are splitting the data which was once grouped as a single large cluster, to “n” number of smaller clusters in which the data points now belong to.
It must be taken into account that this algorithm is highly “rigid” when splitting the clusters –
meaning, one a clustering is done inside a loop, there is no way that the task can be undone
#37 Can obtain any desired number of clusters by cutting the Dendrogram at the proper level.
All the approaches to calculate the similarity between clusters has their own disadvantages.
Time complexity of at least O(n2 log n) is required, where ‘n’ is the number of data points.
#38 It is the backbone of search engine algorithms – where objects that are similar to each other must be presented together and dissimilar objects should be ignored. Also, it is required to fetch objects that are closely related to a search term, if not completely related.
A similar application of text clustering like search engine can be seen in academics where clustering can help in the associative analysis of various documents – which can be in-turn used in – plagiarism, copyright infringement, patent analysis etc.
Used in image segmentation in bioinformatics where clustering algorithms have proven their worth in detecting cancerous cells from various medical imagery – eliminating the prevalent human errors and other bias.
Netflix has used clustering in implementing movie recommendations for its users.
News summarization can be performed using Cluster analysis where articles can be divided into a group of related topics.
Clustering is used in getting recommendations for sports training for athletes based on their goals and various body related metrics and assign the training regimen to the players accordingly.
Marketing and sales applications use clustering to identify the Demand-Supply gap based on various past metrics – where a definitive meaning can be given to huge amounts of scattered data.
Various job search portals use clustering to divide job posting requirements into organized groups which becomes easier for a job-seeker to apply and target for a suitable job.
Resumes of job-seekers can be segmented into groups based on various factors like skill-sets, experience, strengths, type of projects, expertise etc., which makes potential employers connect with correct resources.
Clustering effectively detects hidden patterns, rules, constraints, flow etc. based on various metrics of traffic density from GPS data and can be used for segmenting routes and suggesting users with best routes, location of essential services, search for objects on a map etc.
Satellite imagery can be segmented to find suitable and arable lands for agriculture.
Pizza Hut very famously used clustering to perform Customer Segmentation which helped them to target their campaigns effectively and helped increase their customer engagement across various channels.
Clustering can help in getting customer persona analysis based on various metrics of Recency, Frequency, and Monetary metrics and build an effective User Profile – in-turn this can be used for Customer Loyalty methods to curb customer churn.
Document clustering is effectively being used in preventing the spread of fake news on Social Media.
Website network traffic can be divided into various segments and heuristically when we can prioritize the requests and also helps in detecting and preventing malicious activities.
Fantasy sports have become a part of popular culture across the globe and clustering algorithms can be used in identifying team trends, aggregating expert ranking data, player similarities, and other strategies and recommendations for the users.