Downloaded 10 times



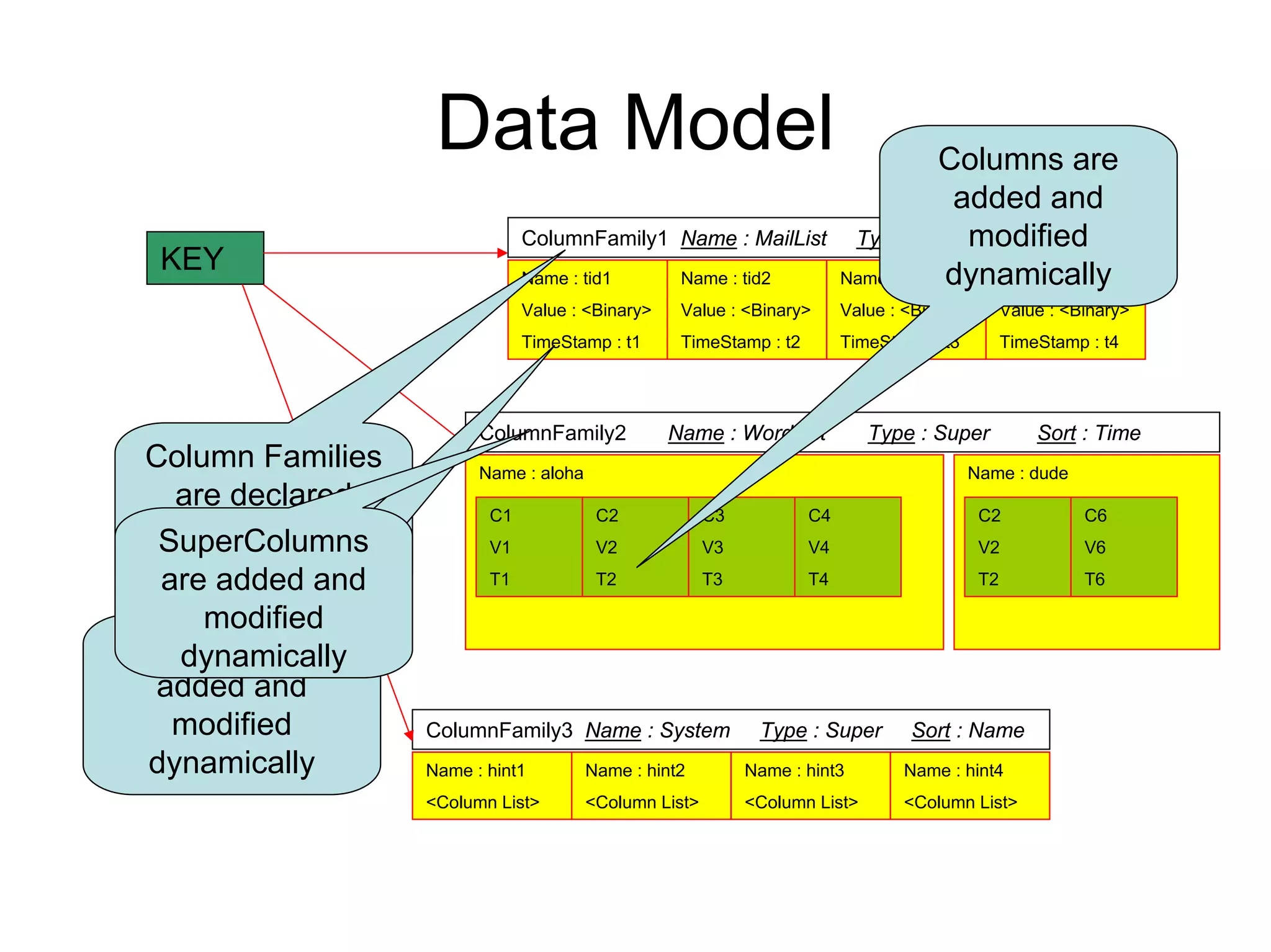

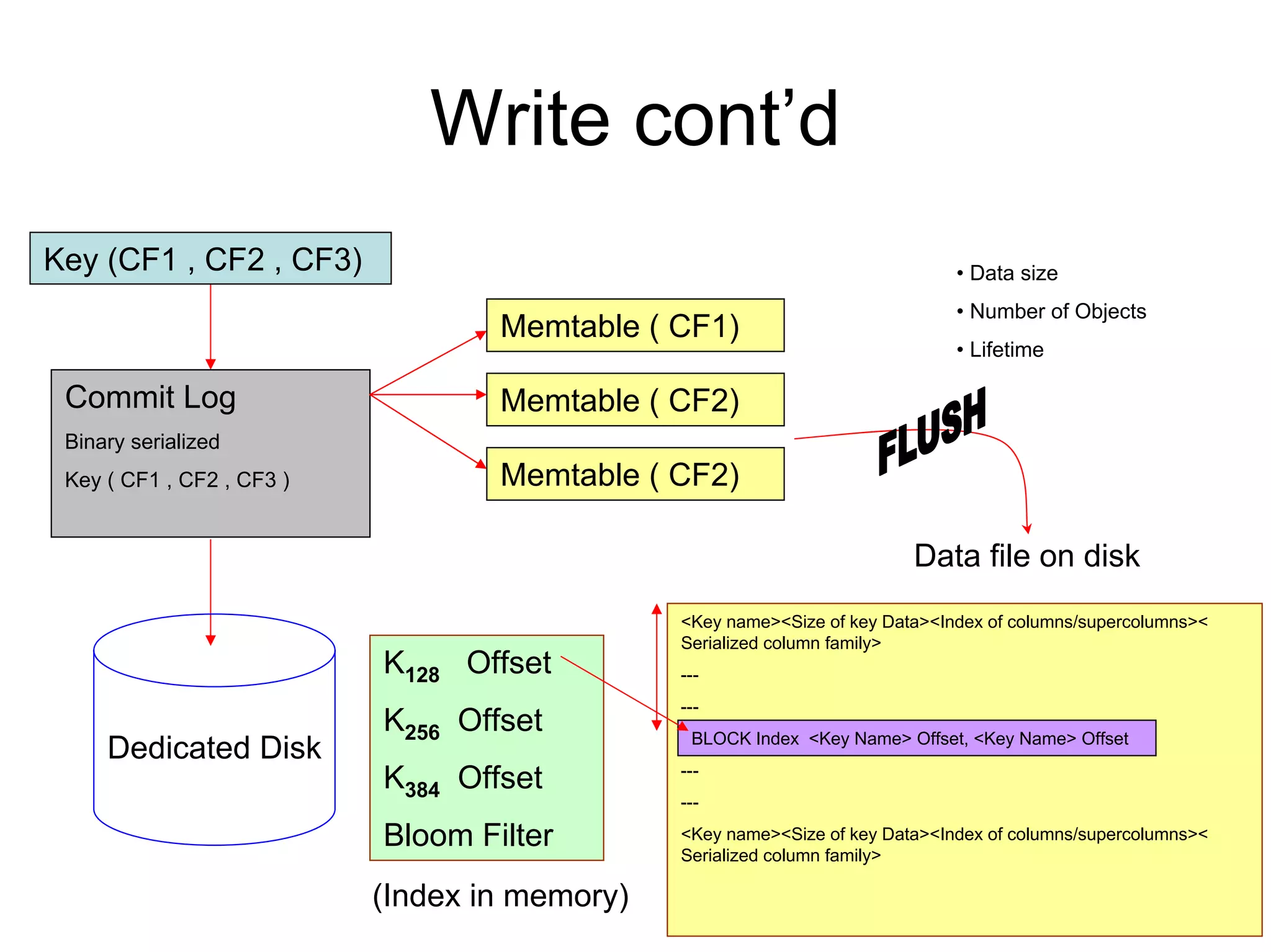
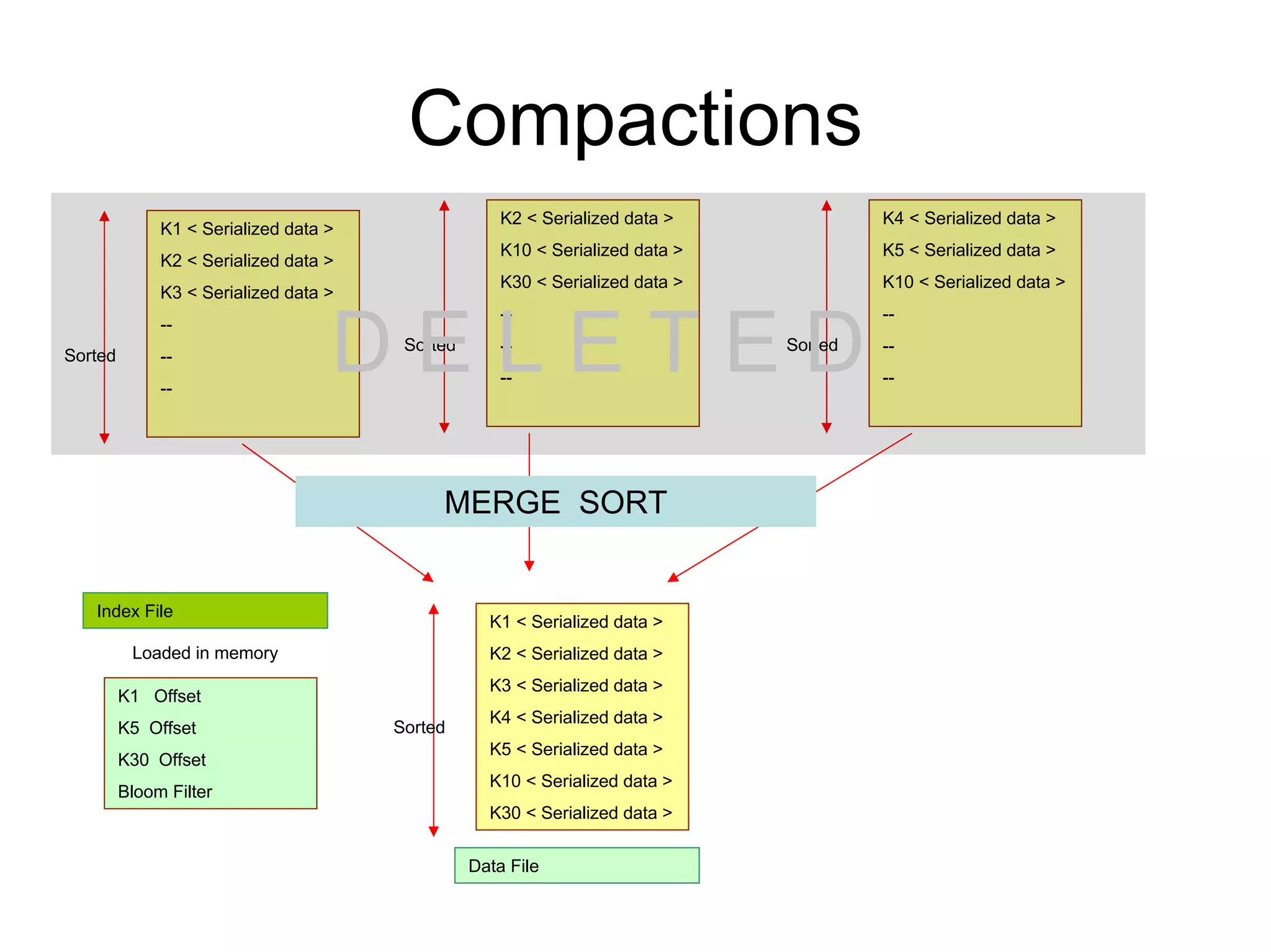

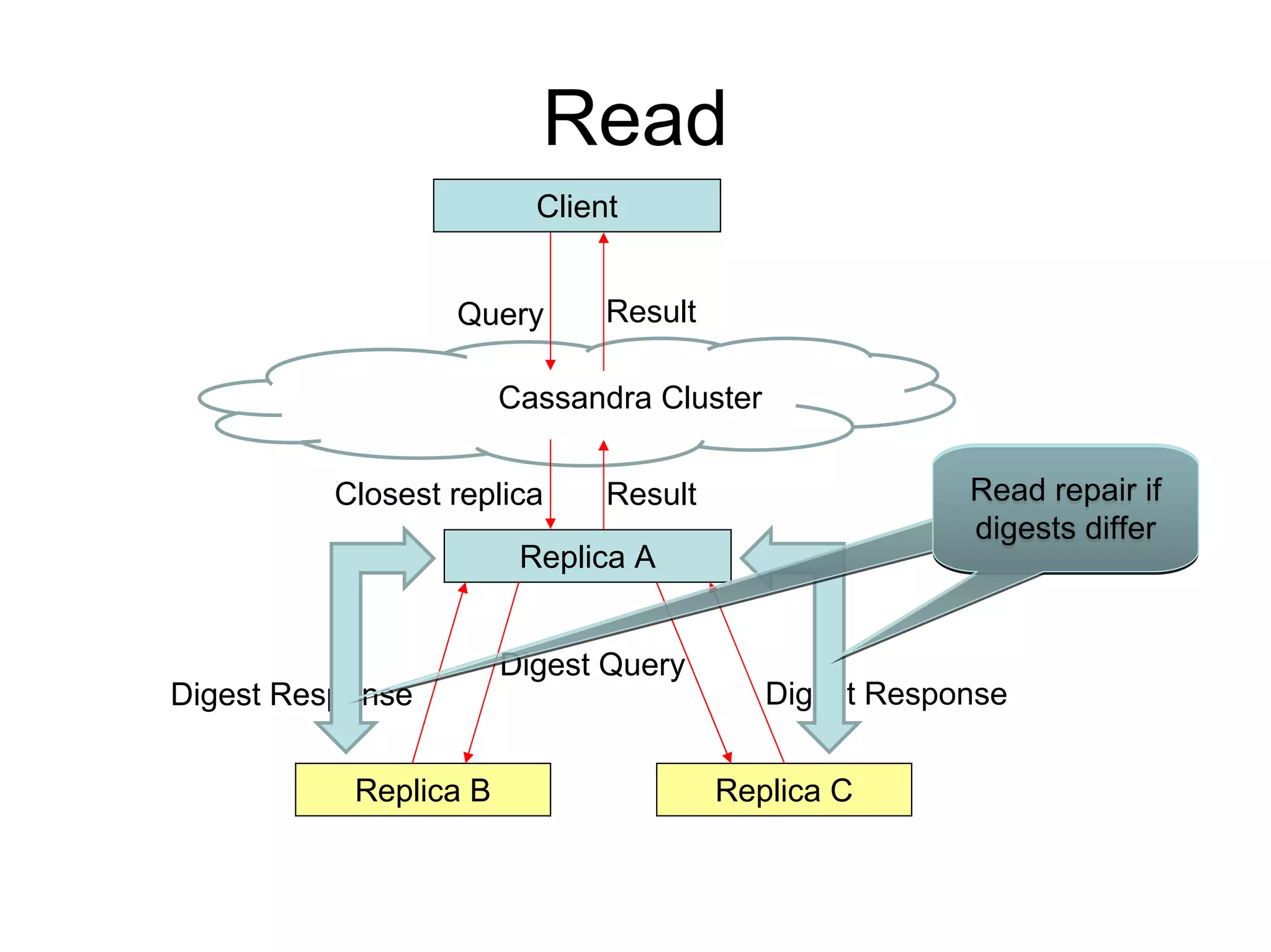
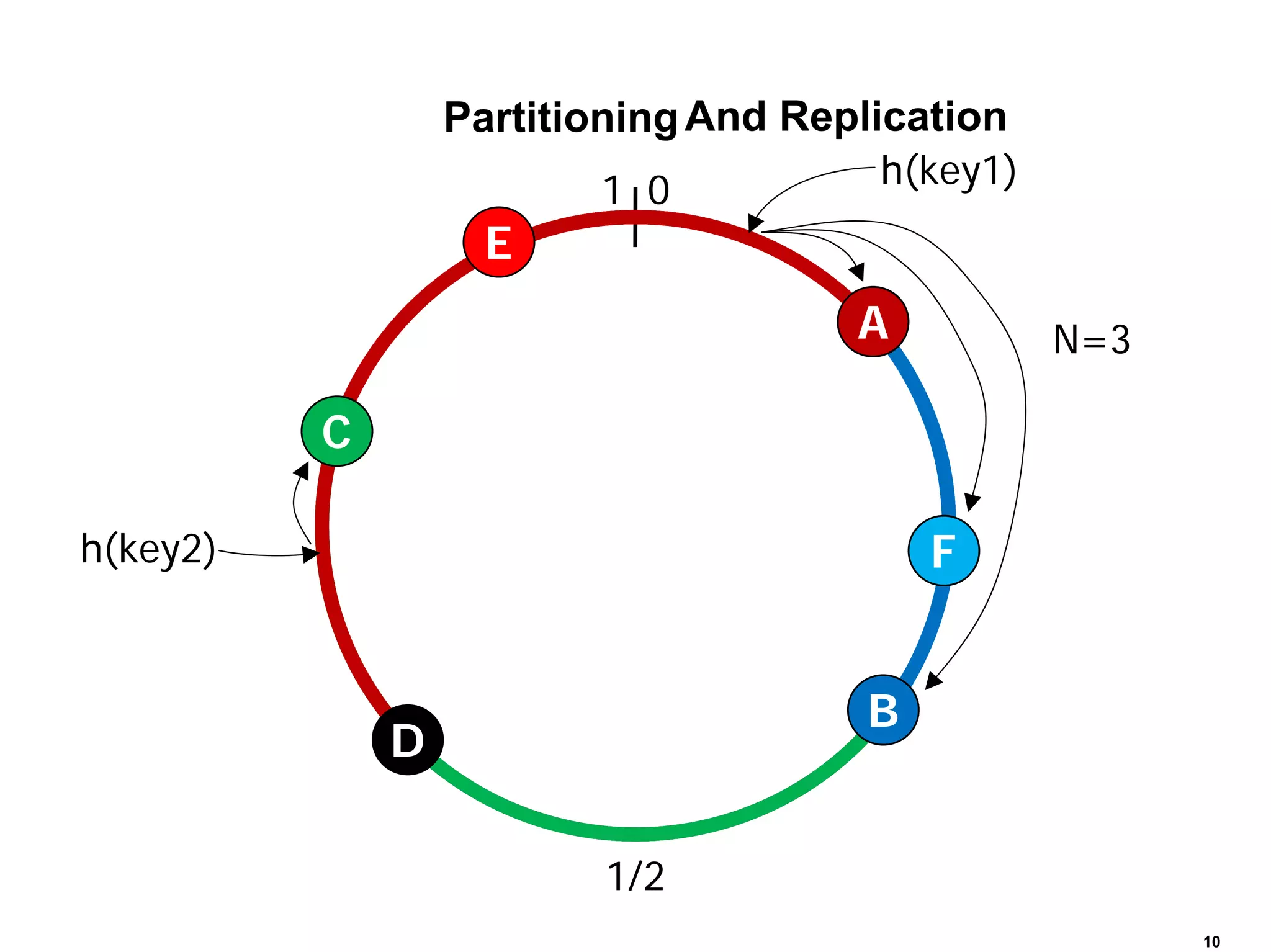

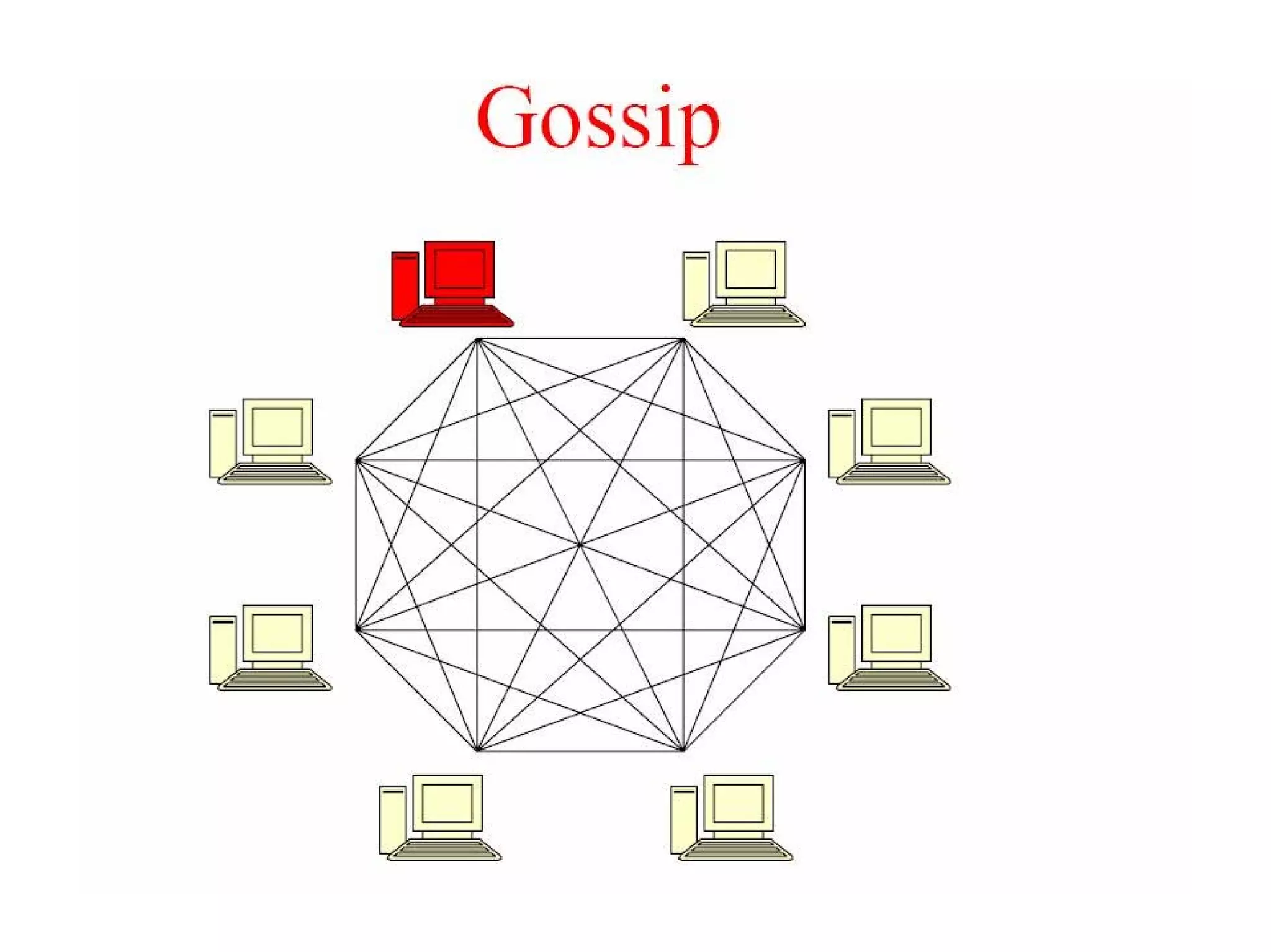
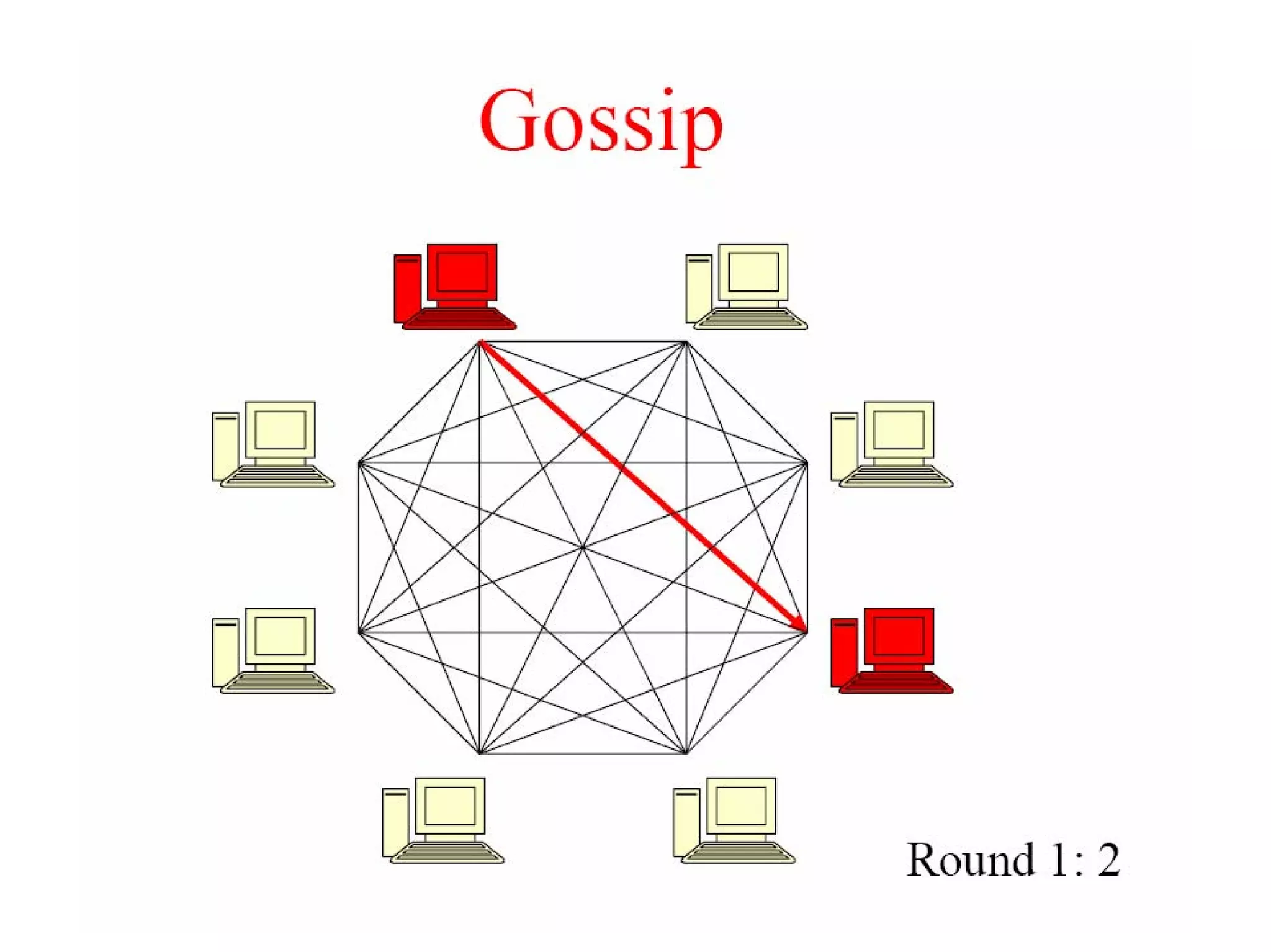
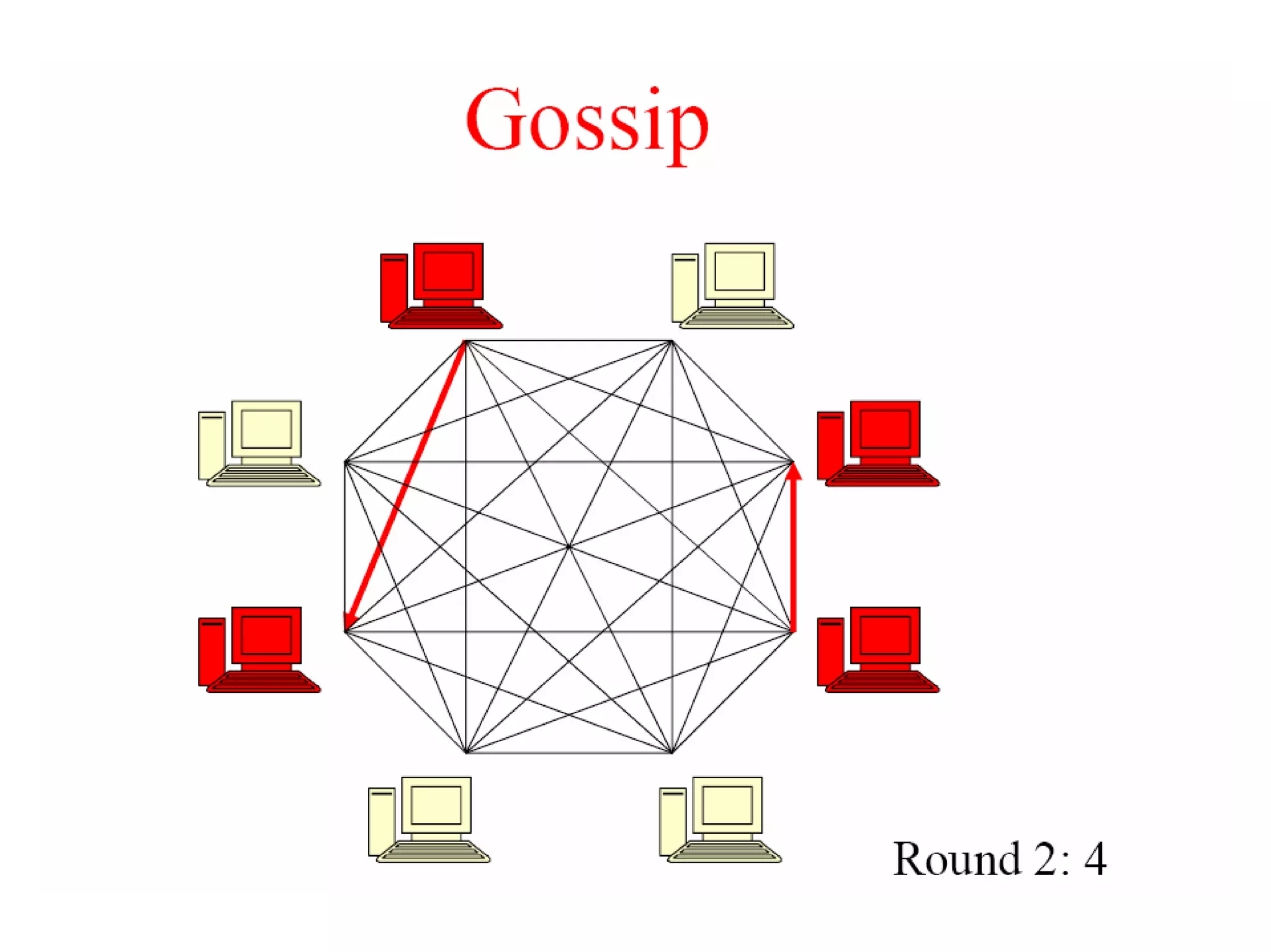
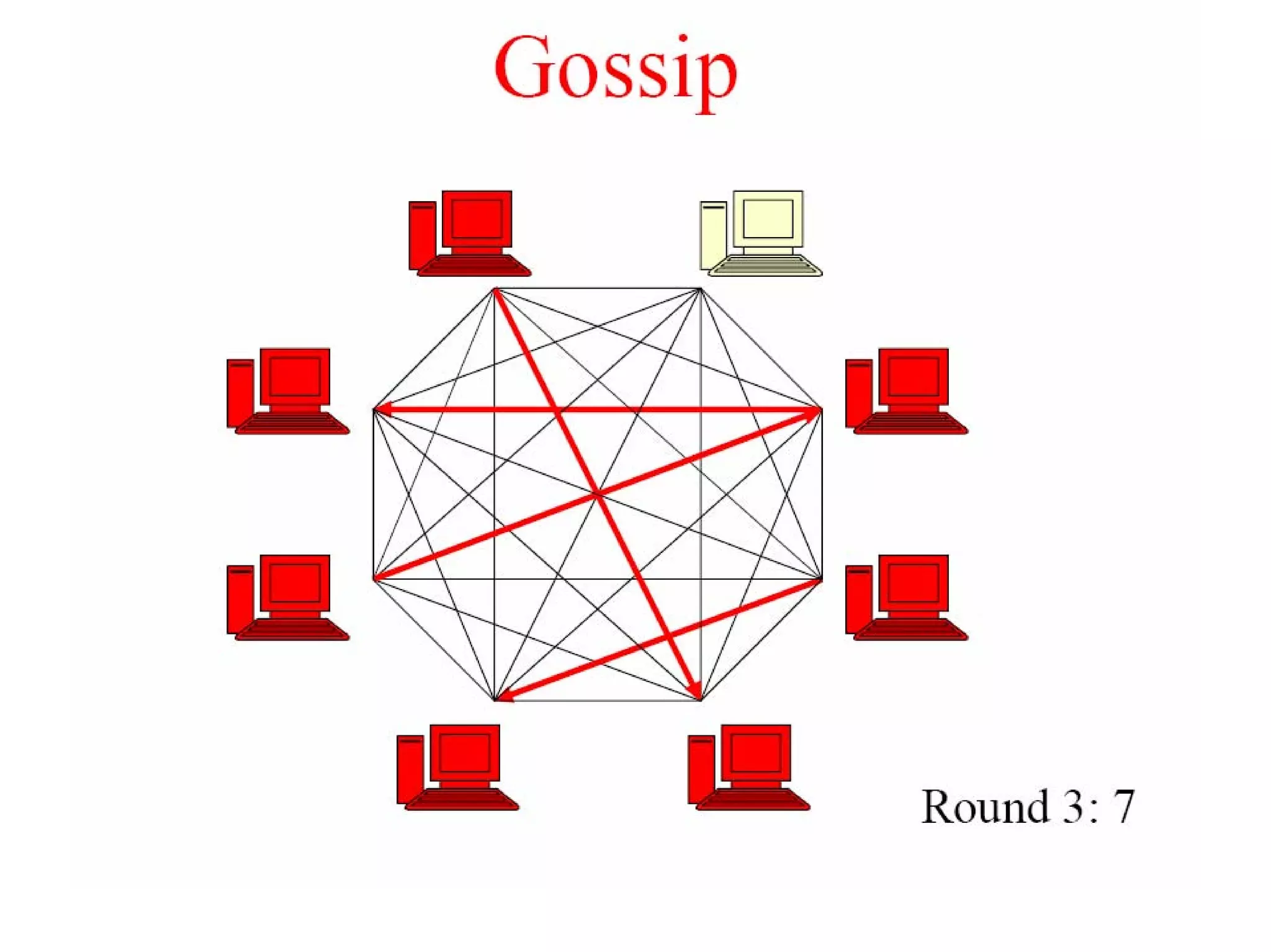



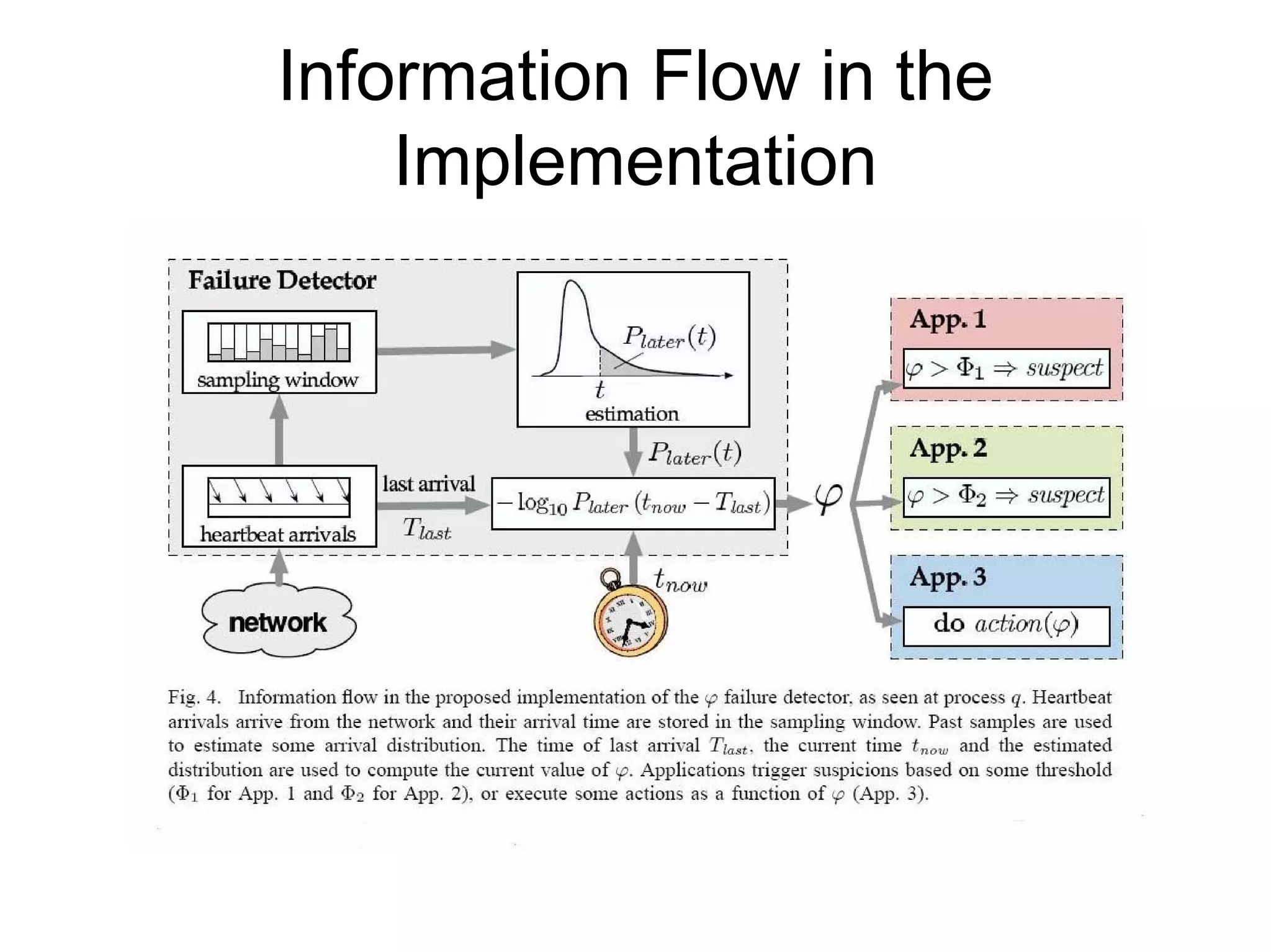





Cassandra is a structured storage system designed to run on a peer-to-peer network. It was created to handle large amounts of data and requests across many servers. Cassandra provides high availability with eventual consistency and incremental scalability. It uses a column-oriented data model and optimizes for writes over reads. Data is partitioned and replicated across nodes and gossip protocols are used for membership and failure detection.







































































![[Estácio - IESAM] Automatizando Tarefas com Gulp.js](https://cdn.slidesharecdn.com/ss_thumbnails/estcio-iesamautomatizandotarefascomgulp-151220144313-thumbnail.jpg?width=640&height=640&fit=bounds)














![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







