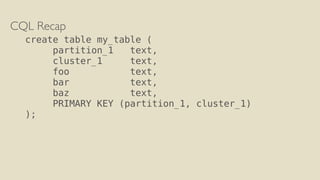
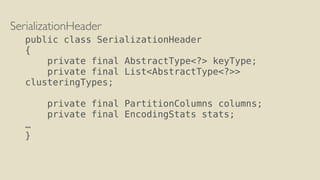
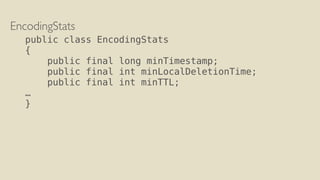
The document discusses performance improvements in Apache Cassandra 3.0's storage engine. Key improvements include delta encoding, variable integer encoding, clustering columns written only once, aggregated cell metadata, and cell presence bitmaps. This reduces storage size and improves read performance. The write path involves committing to the commit log and merging into the memtable. The read path can use clustering index filters to short-circuit searching based on deletion times, column names, or clustering ranges to avoid reading unnecessary SSTables.



















![CQL WithThrift Pre 3.0
[default@dev] list my_table;
-------------------
RowKey: part_a
=> (column=clust_a:, value=, timestamp=1357…739000)
=> (column=clust_a:foo, value=some foo, timestamp=1357…739000)
=> (column=clust_a:bar, value=and bar, timestamp=1357…739000)
=> (column=clust_a:baz, value=no baz, timestamp=1357…739000)
=> (column=clust_b:, value=, timestamp=1357…739000)
=> (column=clust_b:foo, value=no foo, timestamp=1357…739000)
=> (column=clust_b:bar, value=no bar, timestamp=1357…739000)
=> (column=clust_b:baz, value=lots baz, timestamp=1357…739000)](https://image.slidesharecdn.com/cassandrasfmeetup-cqlperformancecassandra3-160331204536/85/Cassandra-SF-Meetup-CQL-Performance-With-Apache-Cassandra-3-X-20-320.jpg)






![CQL WithThrift Pre 3.0
[default@dev] list my_table;
-------------------
RowKey: part_a
=> (column=clust_a:, value=, timestamp=1357…739000)
=> (column=clust_a:foo, value=some foo, timestamp=1357…739000)
=> (column=clust_a:bar, value=and bar, timestamp=1357…739000)
=> (column=clust_a:baz, value=no baz, timestamp=1357…739000)
=> (column=clust_b:, value=, timestamp=1357…739000)
=> (column=clust_b:foo, value=no foo, timestamp=1357…739000)
=> (column=clust_b:bar, value=no bar, timestamp=1357…739000)
=> (column=clust_b:baz, value=lots baz, timestamp=1357…739000)](https://image.slidesharecdn.com/cassandrasfmeetup-cqlperformancecassandra3-160331204536/85/Cassandra-SF-Meetup-CQL-Performance-With-Apache-Cassandra-3-X-30-320.jpg)








![CQL WithThrift Pre 3.0
[default@dev] list my_table;
-------------------
RowKey: part_a
=> (column=clust_a:, value=, timestamp=1357…739000)
=> (column=clust_a:foo, value=some foo, timestamp=1357…739000)
=> (column=clust_a:bar, value=and bar, timestamp=1357…739000)
=> (column=clust_a:baz, value=no baz, timestamp=1357…739000)
=> (column=clust_b:, value=, timestamp=1357…739000)
=> (column=clust_b:foo, value=no foo, timestamp=1357…739000)
=> (column=clust_b:bar, value=no bar, timestamp=1357…739000)
=> (column=clust_b:baz, value=lots baz, timestamp=1357…739000)](https://image.slidesharecdn.com/cassandrasfmeetup-cqlperformancecassandra3-160331204536/85/Cassandra-SF-Meetup-CQL-Performance-With-Apache-Cassandra-3-X-39-320.jpg)





![Remember Where We Came From
[default@dev] list my_table;
-------------------
RowKey: part_a
=> (column=clust_a:, value=, timestamp=1357…739000)
=> (column=clust_a:foo, value=some foo, timestamp=1357…739000)
=> (column=clust_a:bar, value=and bar, timestamp=1357…739000)
=> (column=clust_a:baz, value=no baz, timestamp=1357…739000)
=> (column=clust_b:, value=, timestamp=1357…739000)
=> (column=clust_b:foo, value=no foo, timestamp=1357…739000)
=> (column=clust_b:bar, value=no bar, timestamp=1357…739000)
=> (column=clust_b:baz, value=lots baz, timestamp=1357…739000)](https://image.slidesharecdn.com/cassandrasfmeetup-cqlperformancecassandra3-160331204536/85/Cassandra-SF-Meetup-CQL-Performance-With-Apache-Cassandra-3-X-45-320.jpg)






























































![[Cassandra summit Tokyo, 2015] Cassandra 2015 最新情報 by ジョナサン・エリス(Jonathan Ellis)](https://cdn.slidesharecdn.com/ss_thumbnails/tokyocassandrasummit2015withnotes-150624051836-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)











































