The document outlines Carvana's efforts to enhance their auction purchase predictions in the used car market, leveraging data analysis of 73,000 transactions. It highlights key factors influencing used car purchases and the methodology, including data preprocessing, feature engineering, and various machine learning models used for predictions. The analysis reveals challenges such as class imbalance and model tuning, ultimately presenting training and testing scores for multiple algorithms employed in the study.







![Dataset – Initial analysis
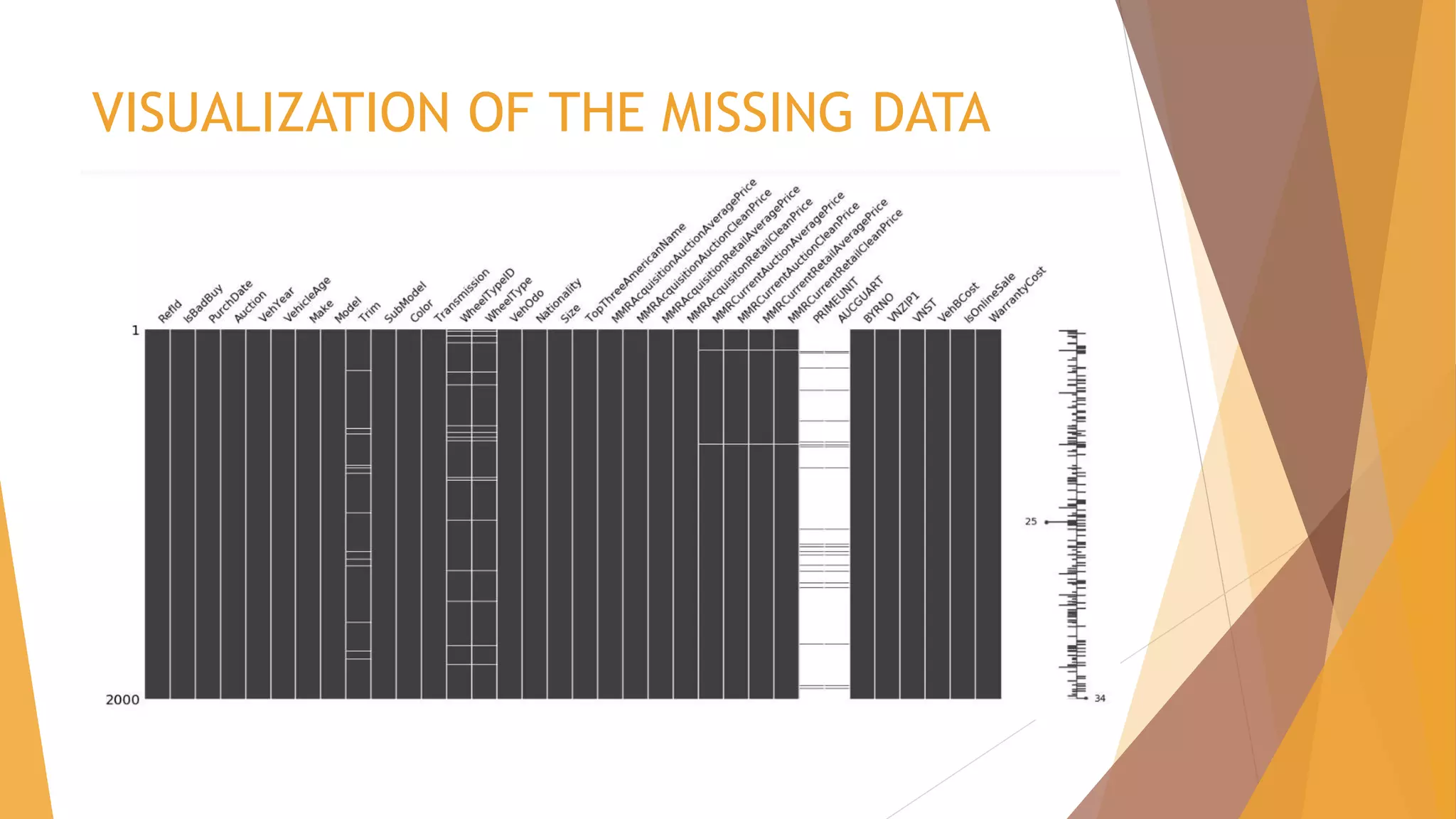
The dataset initially had 34 attributes with the target attribute being – IsBadBuy
The dataset had 19 numerical attributes and 15 categorical attributes and the
shape and column can be seen below.
CATEGORICAL:
((72983, 15),
Index(['PurchDate', 'Auction', 'Make', 'Model', 'Trim', 'SubModel', 'Color',
'Transmission', 'WheelType', 'Nationality', 'Size',
'TopThreeAmericanName', 'PRIMEUNIT', 'AUCGUART', 'VNST'],
dtype='object’))](https://image.slidesharecdn.com/carvanapredictingthepurchasequalityincar-190201182623/75/CARVANA-Predicting-the-purchase-quality-in-car-9-2048.jpg)
![CONTD…
NUMERIC:
((72983, 19),
Index(['RefId', 'IsBadBuy', 'VehYear', 'VehicleAge', 'WheelTypeID', 'VehOdo',
'MMRAcquisitionAuctionAveragePrice', 'MMRAcquisitionAuctionCleanPrice',
'MMRAcquisitionRetailAveragePrice', 'MMRAcquisitonRetailCleanPrice',
'MMRCurrentAuctionAveragePrice', 'MMRCurrentAuctionCleanPrice',
'MMRCurrentRetailAveragePrice', 'MMRCurrentRetailCleanPrice', 'BYRNO',
'VNZIP1', 'VehBCost', 'IsOnlineSale', 'WarrantyCost'],
dtype='object'))](https://image.slidesharecdn.com/carvanapredictingthepurchasequalityincar-190201182623/75/CARVANA-Predicting-the-purchase-quality-in-car-10-2048.jpg)







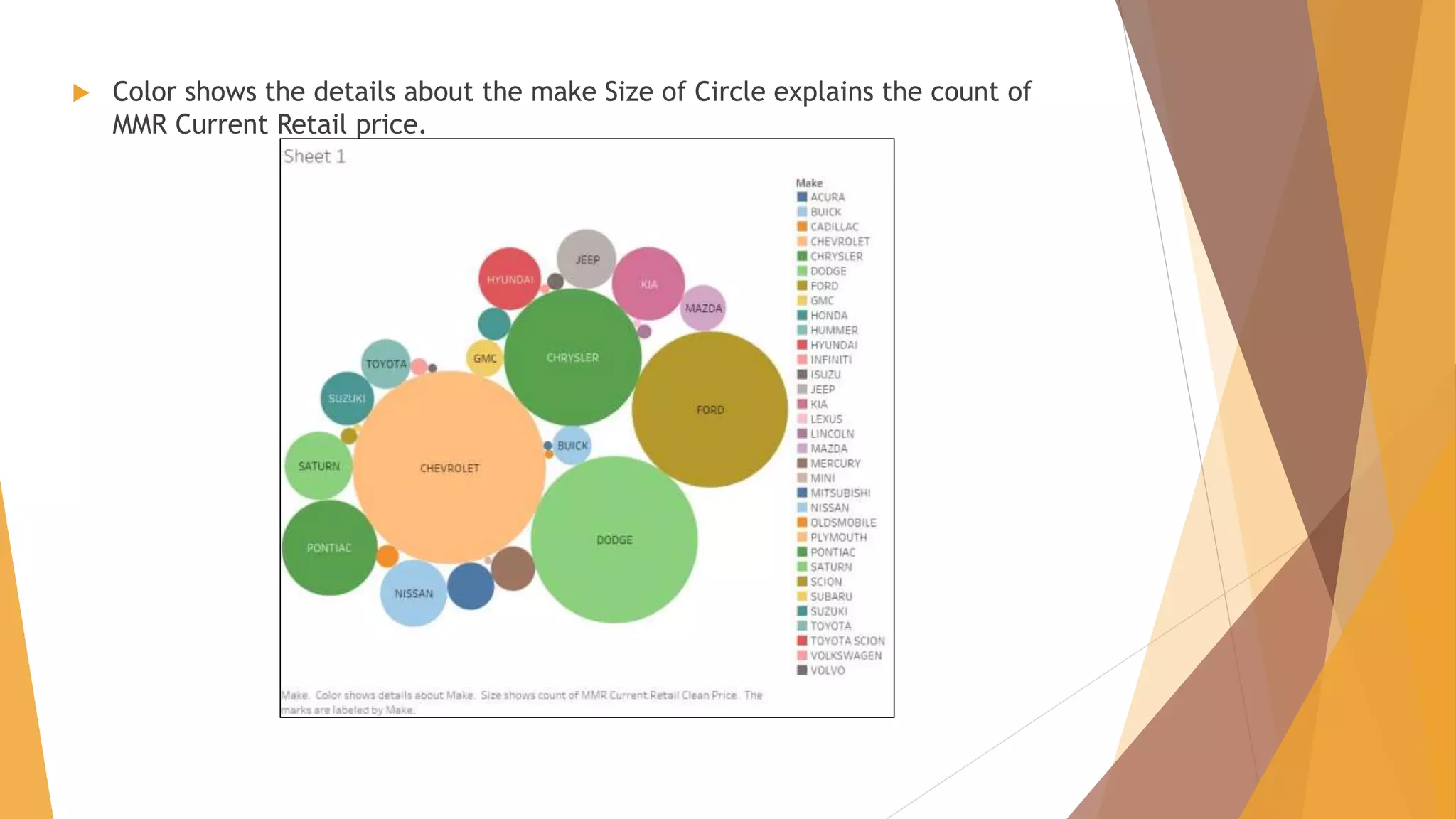

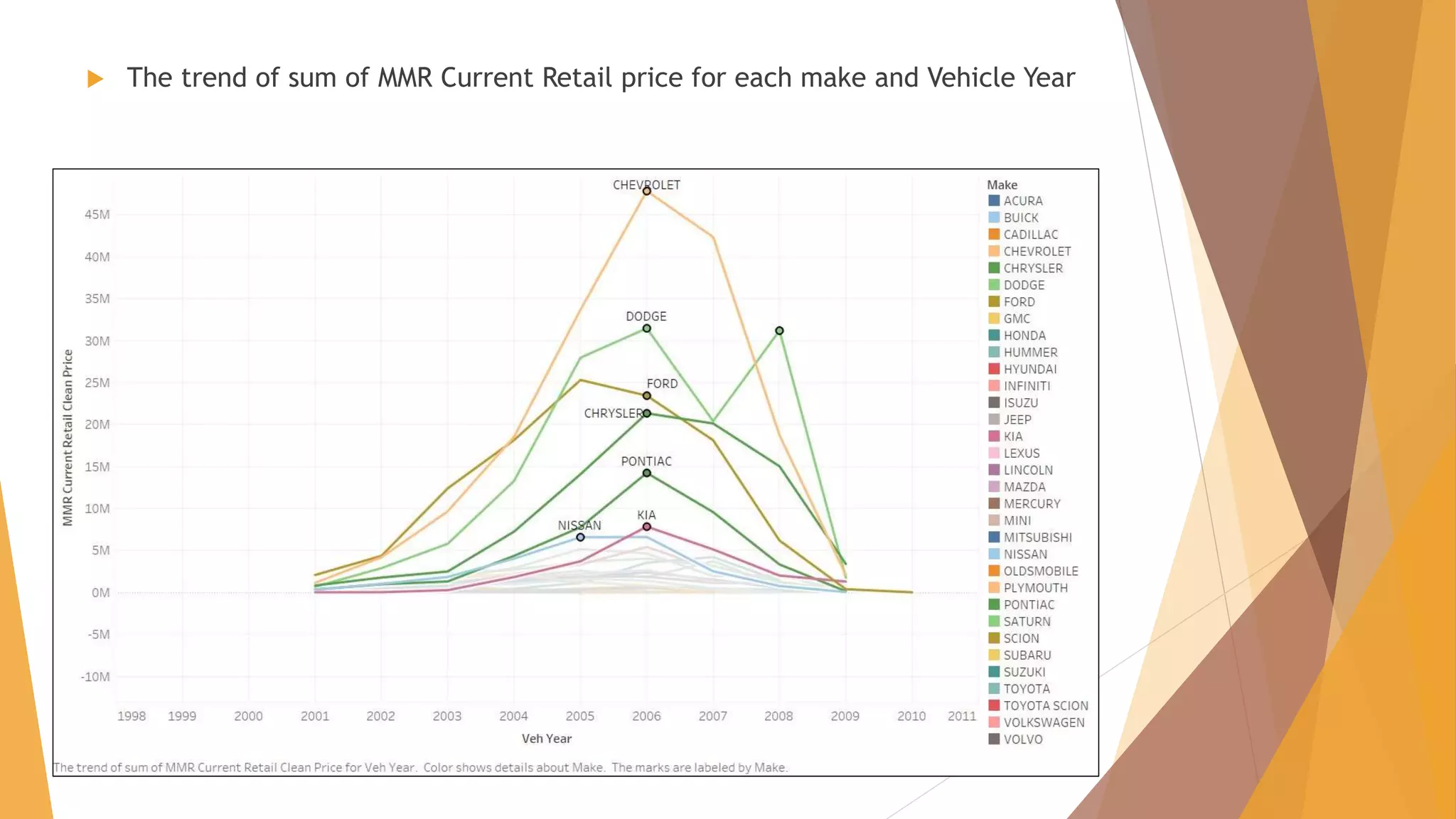



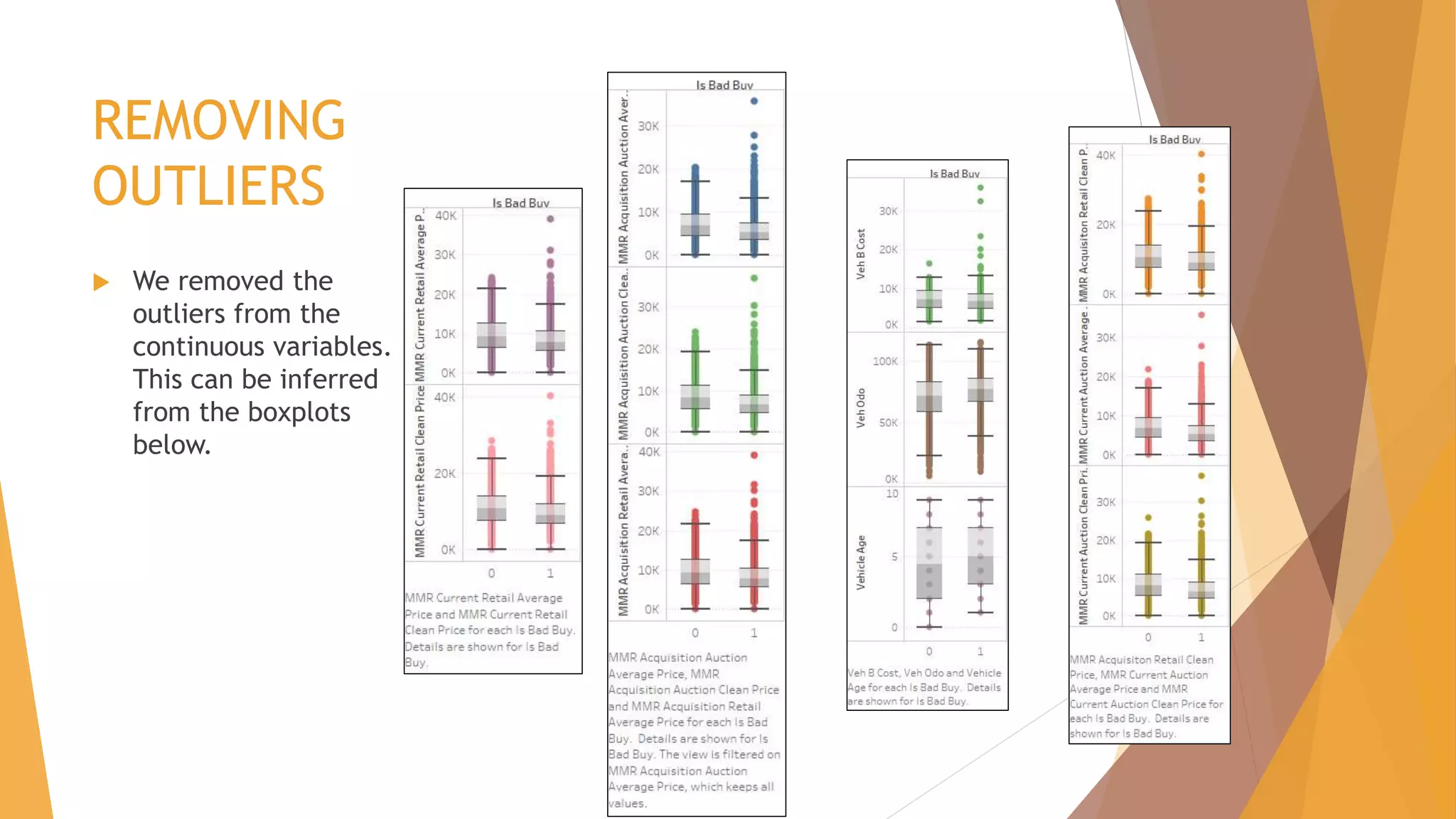



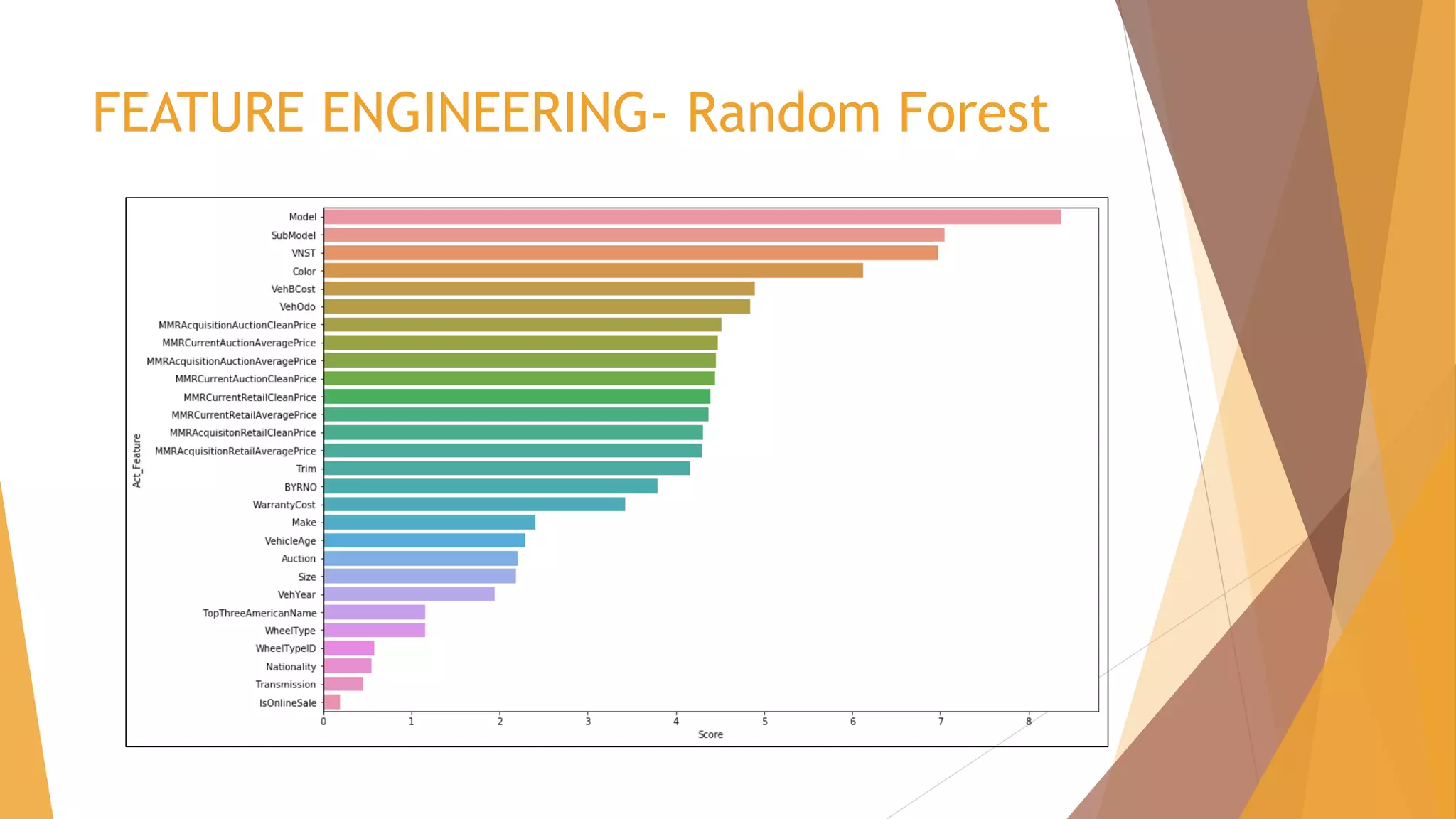


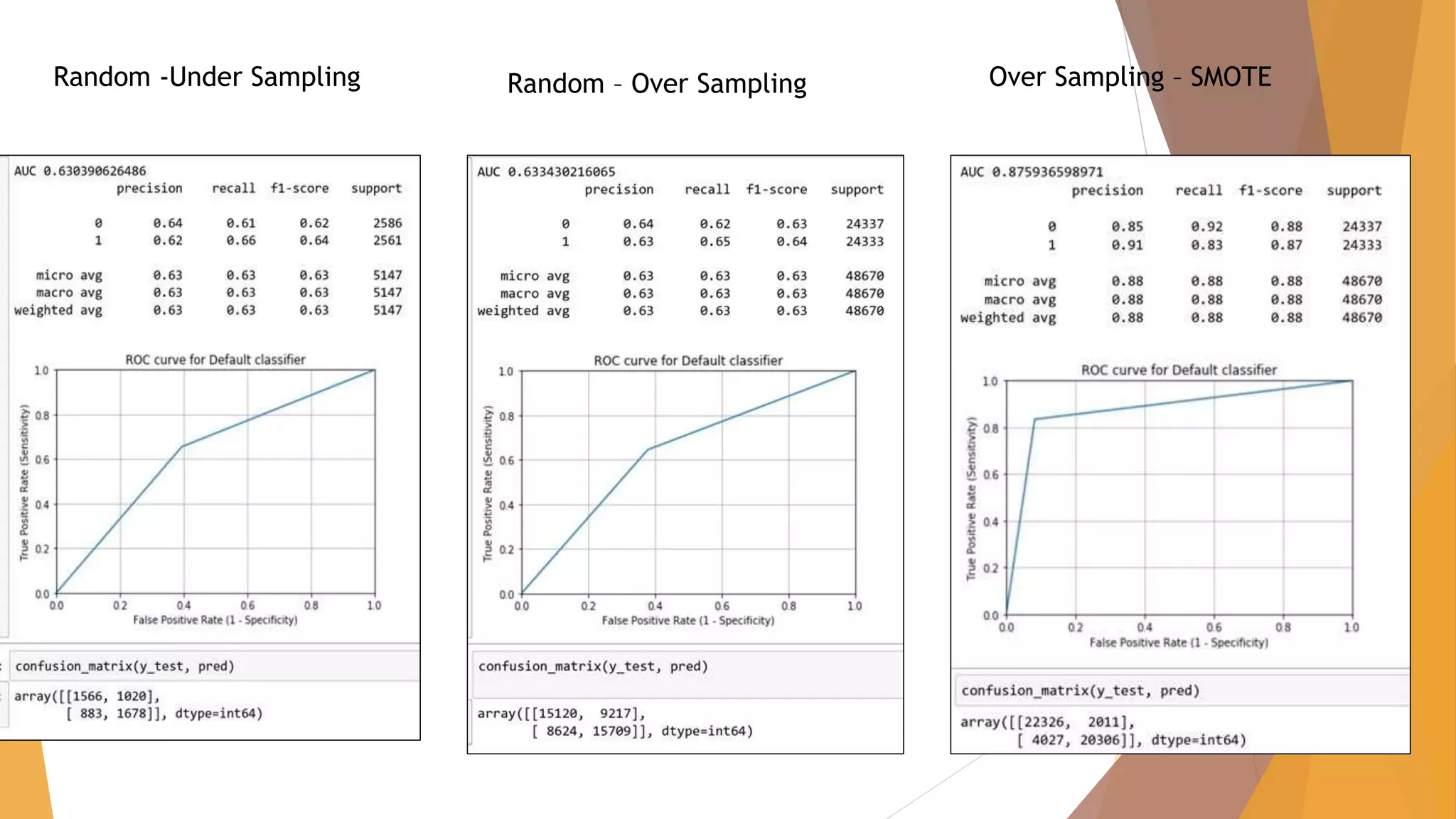
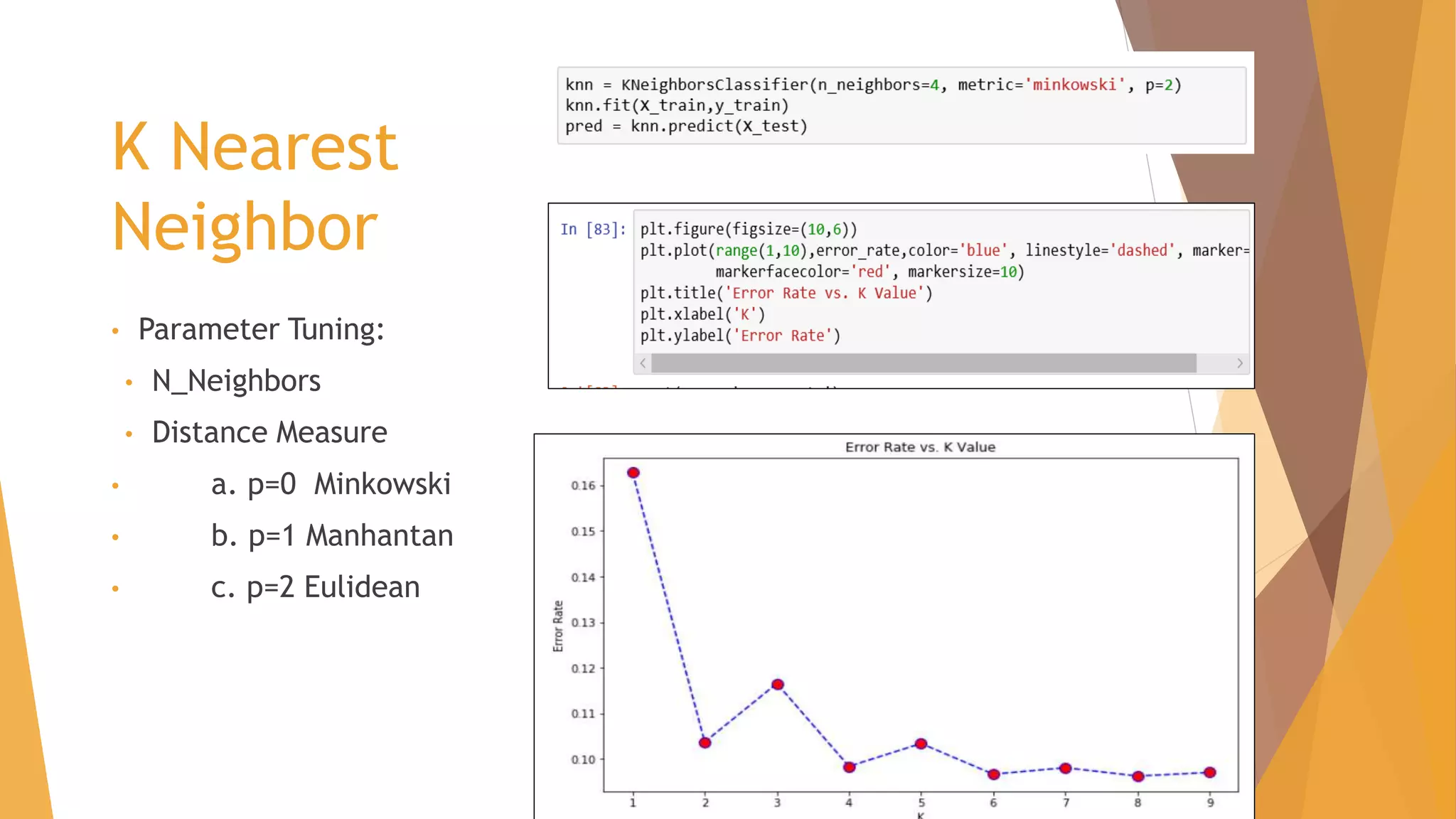






![CHALLENGES FACED – Algorithm
SVM
Parameter Tuning
C , gamma , Kernal.
Grid Search
C=[0.1,1,10,100]
Gamma=[1,0.1,0.01,0.0001]
Kernel- rbf.
Time Execution – More than 12
hours , for 25 fits out of 75 fits](https://image.slidesharecdn.com/carvanapredictingthepurchasequalityincar-190201182623/75/CARVANA-Predicting-the-purchase-quality-in-car-43-2048.jpg)



















































![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bassam Maharmeh - Artificial Intelligence: Opportunities and ...](https://cdn.slidesharecdn.com/ss_thumbnails/thhfmr2fqpawzj7hsjpg-5-251211083048-2c23204f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
