Downloaded 13 times








![Practical Data Science
10 | P a g e
s3779142, s3755598
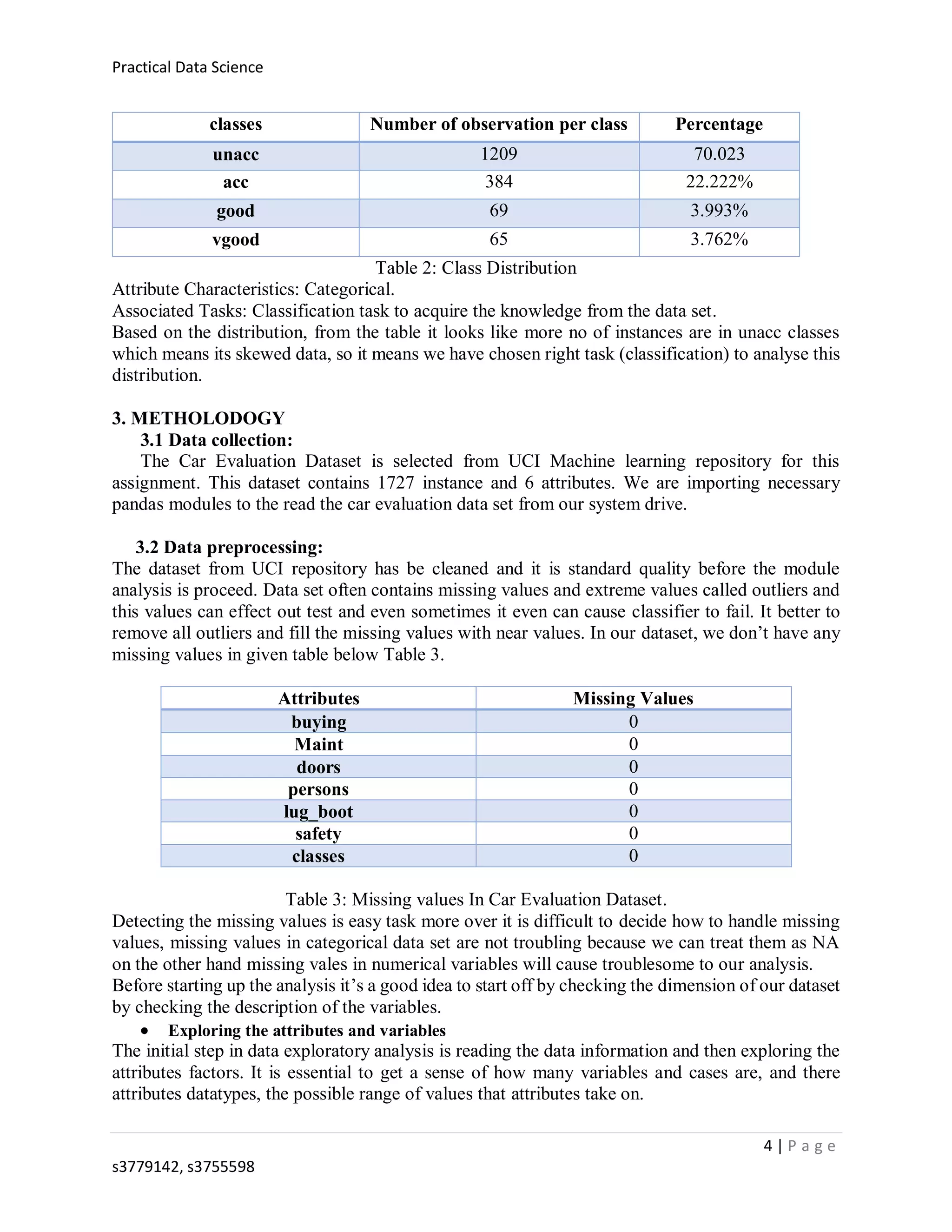
Classification error
rate
8.79% 7.38% 6.35%
Confusion Matrix [[577 6 3 0]
[ 46 167 3 3]
[ 4 3 21 1]
[ 1 2 4 23]]
[[459 4 2 0]
[ 28 148 3 0]
[ 3 5 15 0]
[ 1 5 0 18]]
[[231 2 1 0]
[ 14 73 0 0]
[ 1 1 10 0]
[ 0 2 1 10]]
precision 0.846 0.899 0.927
recall 0.809 0.804 0.857
f1 score: 0.824 0.845 0.887
Table 5: Accuracy test for K nearest neighbor
From the output for KNN classifier, we can say that the split 80% 20% train and test dataset
gives us the best accuracy when compared to other splitting ratio.
II. Decision trees
Decision tree is a module that uses a tree-like-graph or module of condition of decisions and their
possible consequences. It is one approach to display an algorithm that contains only conditional
control statements.
It follows a flowchart like structure in each internal node that is condition on each attribute, each
branch represents the outcome of the condition, and each leaf node represents a class table. The
top down approach from the root to the leaf represents classification rule.
Root Node: This Node represents the total population (instances) and furthers breakdown into
branches class sub-nodes based the conditions.
Decision node: When a sub node gets divided into further sub nodes then its called decision
node.
Leaf node:When node cannot spilt further into sub nodes.
i. For 50% training set and 50% testing set
The data set has been divided into 50% train and 50% test set with instances of 863 and 864
respectively.
i. For 60% training set and 40% testing set
The data set has been divided into 60% train and 40% test set with instances of 1036 and 691
respectively.
ii. For 80% training set and 20% testing set
The data set has been divided into 80% train and 20% test set with instances of 1381 and 346
respectively.
The accuracy achieved for different dataset spilt are presented in the table 6.](https://image.slidesharecdn.com/report-190805093646/75/CAR-EVALUATION-DATABASE-10-2048.jpg)
![Practical Data Science
11 | P a g e
s3779142, s3755598
Decision tree max_depth=6
Splitting Percentage
(Training % and
Testing %)
50% 50% 60% 40% 80% 20%
Testing accuracy 92.24% 93.19% 93.641%
Classification error
rate
7.75% 6.80% 6.35%
Confusion Matrix [[568 16 2 0]
[ 16 179 21 3]
[ 0 0 24 5]
[ 0 4 0 26]]
[[449 14 2 0]
[ 2 156 18 3]
[ 0 0 19 4]
[ 0 4 0 20]]
[[224 9 1 0]
[ 1 78 7 1]
[ 0 0 11 1]
[ 0 2 0 11]]
precision 0.786 0.780 0.824
recall 0.870 0.874 0.904
f1 score 0.817 0.815 0.854
Table 6: Accuracy test for decision tree
From the output for Decision tree classifier, we can say that the split 80% 20% train and test
dataset gives us the best accuracy when compared to other splitting ratio.
4. RESULTS
The presentation of the results is based on following model analysis. To get better understand of
the module we also used another measurement precision, recall, f1 score. In this analysis our
splitting ration of k nearest neighbor 80% 20% seems good enough at its performance.
For 80% 20%
n_neighbour= 7 , p= 2
Testing
accuracy
Classification
error rate
Confusion Matrix precision recall f1 score:
93.641% 6.35% [[231 2 1 0]
[ 14 73 0 0]
[ 1 1 10 0]
[ 0 2 1 10]]
0.927 0.857 0.887
Table 5.a: Accuracy results for K nearest neighbor
For 80% and 20%
Max_depth= 6
Testing
accuracy
Classification
error rate
Confusion Matrix precision recall f1 score:
93.641% 6.35% [[224 9 1 0]
[ 1 78 7 1]
[ 0 0 11 1]
[ 0 2 0 11]]
0.824 0.904 0.854
Table 6.a: Accuracy results for K nearest neighbor](https://image.slidesharecdn.com/report-190805093646/75/CAR-EVALUATION-DATABASE-11-2048.jpg)


The document discusses a car evaluation database used for data science analysis, focusing on car attributes affecting buyer decisions, such as price and safety. It details the methodology for data collection, preprocessing, exploration, and classification using models like k-nearest neighbors and decision trees. The results indicate that the best model accuracy is achieved with an 80% training and 20% testing split of the dataset.


















































![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Imai Jen-La Plante - The New Generation: AI and the Future of...](https://cdn.slidesharecdn.com/ss_thumbnails/kxi8t2l5rggivgcenyba-1-jenlaplante-dsc-251208152532-d1e076c2-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Debmalya Biswas - Agentification: the art of transforming man...](https://cdn.slidesharecdn.com/ss_thumbnails/r5azlggvtqiaiiusrqdr-4-251212103249-5a12c89b-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)