상호배타적 집합
- 교집합이없는 집합관계(집합은 꼭 2개가 아니라 N개일수도 있음)
1
2 3
4
5 6
집합 A 집합 B
상호배타적 집합이다.
집합 A의 원소는 {1,2,3}이고 집합 B의 원소는
{4,5,6} 이므로 교집합이 없음
1
2 3
2
4 6
집합 A 집합 B
상호배타적 집합이 아니다.
집합 A의 원소는 {1,2,3}이고 집합 B의 원소는
{2,4,6} 이므로 교집합 {2}가 존재함
5.
집합 표현하기
무엇을 고려해야할까요?
- 특정 집합 원소들이 하나의 집합의 원소라는 것을 알 수 있어야 함
* 집합 A = {1,2,3}일때 각 원소가 집합 A에 속한다는 걸 알아야 함
- 각 집합간 다른집합이라는 것을 알 수 있어야 함
* 집합 A = {1,2,3}, B = {4,5,6} 일때 두 집합이 다른 집합이란걸 알아야 함
- 특정 원소가 어느 집합에 속하는지 알수 있어야 함
* 집합 A = {1,2,3}, B = {4,5,6} 일때 원소 5가 집합 B에 속한다는 걸 확인 가능 해야함
- 두개의 집합을 하나로 합칠수 있어야 함
* 집합 A = {1,2,3}, B = {4,5,6} 일때 이를 합쳐서 {1,2,3,4,5,6}만들수 있어야 함
각 집합의 대표원소를 만들면 해결 된다.
6.
집합 표현하기
1
2 3
4
56
집합 A 집합 B
각 집합에서 가장 작은 원소를 대
표원소(루트노드)로 한다.
1 2 3 4 5 6
1 1 1 4 4 4
대표원소 : 1 대표원소 : 4
- 대표원소는 현재노드와 부모노드가 같음
- 배열을 활용해서 나타낼 수 있음(현재노드는 인덱스, 부모노드는 값)
- 부모노드가 없다면 -1로 나타낼수 있음
현재노드
부모노드
8
7
-1
8
3
7.
집합의 연산 find
특정노드의 루트 노드를 확인하는 연산
- 특정 노드로 부터, 루트노드가 나올때 까지 거슬러 올라가면 됨
- union 연산에서도 활용 됨
8.
집합의 연산 find의최악의 경우
1
2
3
4
5
1 2 3 4 5
1 1 2 4
현재노드
부모노드 3
- 루트노드를 찾는데 필요한 경로가 깊어질경우 연산횟수가 증가함 O(N)
- 어떻게 하면 경로의 깊이를 줄일수 있을까??
=> 경로 압축 알고리즘을 활용하자!
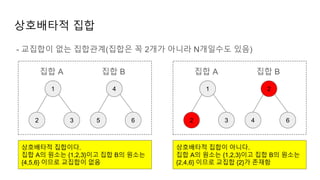
집합의 연산 find(경로압축의과정)
find연산을 하는 노드가 루트노드 일 경우, 루트노드를 반환
find연산을 하는 노드가 루트노드가 아닐 경우, 자신의 부모노드를 find(해당 노드의
부모노드)로 설정
1
2
3
4
5
실제 함수 호출 과정
find(5) , disjoint[5] = disjoint[4] 이후, disjoint[5] 반환
> find(4), disjoint[4] = disjoint[3] 이후, disjoint[4] 반환
> find(3), disjoint[3] = disjoint[2] 이후, disjoint[3] 반환
> find(2), disjoint[2] = disjoint[1] 이후, disjoint[2] 반환
> find(1), 루트노드 이므로 disjoint[1] 반환
11.
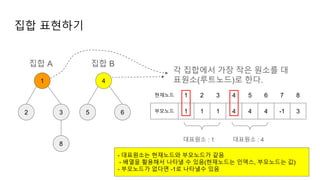
집합의 연산 find(경로압축의실제동작 1)
1
2
3
4
5
①
②
③
④
루트노드 확인
1
2
3
4
5
① disjoint[2] = disjoint[1]
1 2 3 4 5
1 1
2
1
4
1
현재노드
부모노드
3
1
② disjoint[3] = disjoint[2]
③ disjoint[4] = disjoint[3]
④ disjoint[5] = disjoint[4]
① ② ③ ④
disjoint
12.
집합의 연산 find(경로압축의실제동작 1, 결론적으로)
1
2
3
4
5
① disjoint[2] = disjoint[1]
1 2 3 4 5
1 1
2
1
4
1
현재노드
부모노드
3
1
② disjoint[3] = disjoint[2]
③ disjoint[4] = disjoint[3]
④ disjoint[5] = disjoint[4]
① ② ③ ④
disjoint
1
2 3 4 5
13.
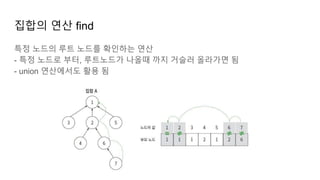
집합의 연산 find(경로압축의실제동작 2)
1
2
4
루트노드 확인
3 5
6
7
①
②
③
1
2
4
3 5
6
7
① disjoint[2] = disjoint[1]
② disjoint[6] = disjoint[2]
③ disjoint[7] = disjoint[6]
14.
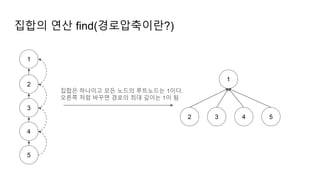
집합의 연산 find(경로압축의실제동작 2)
1
2
4
3 5
6
7
① disjoint[2] = disjoint[1]
② disjoint[6] = disjoint[2]
③ disjoint[7] = disjoint[6]
1
2
4
3 5 6 7
경로 압축을 했다고, 루트노드를 제외한 모든 노드의 깊이가 1이 되는건 아님.
find 연산을 할 때, 루트노드를 찾는 과정에서 거쳐간 노드들의 경로가 압축 됨
경로압축을 적용하면 find연산의 시간복잡도는 O(1)에 가까워짐
15.
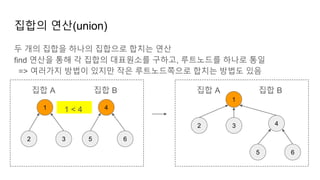
집합의 연산(union)
두 개의집합을 하나의 집합으로 합치는 연산
find 연산을 통해 각 집합의 대표원소를 구하고, 루트노드를 하나로 통일
=> 여러가지 방법이 있지만 작은 루트노드쪽으로 합치는 방법도 있음
1
2 3
4
5 6
집합 A 집합 B
1
2 3 4
5 6
집합 A 집합 B
1 < 4
16.
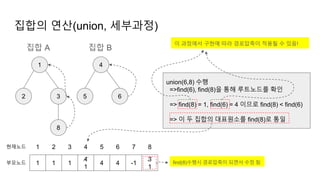
집합의 연산(union, 세부과정)
1
23
4
5 6
집합 A 집합 B
8
1
1
현재노드
부모노드
2
1
3
1
4
4
1
5
4
6
4
7
-1
8
3
1
union(6,8) 수행
=>find(6), find(8)을 통해 루트노드를 확인
=> find(8) = 1, find(6) = 4 이므로 find(8) < find(6)
=> 이 두 집합의 대표원소를 find(8)로 통일
이 과정에서 구현에 따라 경로압축이 적용될 수 있음!
find(8)수행시 경로압축이 되면서 수정 됨
17.
집합의 연산(union, 효율성에대한 고민)
union 연산이후 깊이를 최소화 할 수 있을까?
=> 집합에 랭크를 도입하자(특정노드 기준 최대 깊이)
=> 랭크가 더 큰쪽으로 합쳐서, 랭크의 증가를 최소화 하자(랭크 기반 알고리즘)
18.
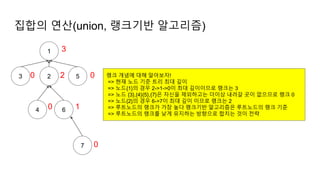
집합의 연산(union, 랭크기반알고리즘)
1
2
4
3 5
6
7 0
0 1
0
2
0
3
랭크 개념에 대해 알아보자!
=> 현재 노드 기준 트리 최대 깊이
=> 노드{1}의 경우 2->1->0이 최대 깊이이므로 랭크는 3
=> 노드 {3},{4}{5},{7}은 자신을 제외하고는 더이상 내려갈 곳이 없으므로 랭크 0
=> 노드{2}의 경우 6->7이 최대 깊이 이므로 랭크는 2
=> 루트노드의 랭크가 가장 높다 랭크기반 알고리즘은 루트노드의 랭크 기준
=> 루트노드의 랭크를 낮게 유지하는 방향으로 합치는 것이 전략
19.
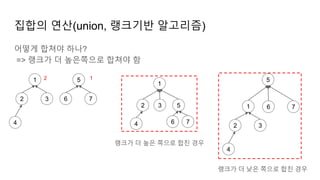
집합의 연산(union, 랭크기반알고리즘)
어떻게 합쳐야 하나?
=> 랭크가 더 높은쪽으로 합쳐야 함
1
2
4
3
5
6 7
2 1
1
2
4
3 5
6 7
1
2
4
3
5
6 7
랭크가 더 높은 쪽으로 합친 경우
랭크가 더 낮은 쪽으로 합친 경우
20.
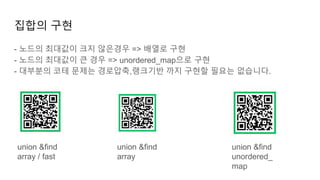
집합의 구현
- 노드의최대값이 크지 않은경우 => 배열로 구현
- 노드의 최대값이 큰 경우 => unordered_map으로 구현
- 대부분의 코테 문제는 경로압축,랭크기반 까지 구현할 필요는 없습니다.
union &find
array / fast
union &find
array
union &find
unordered_
map
21.
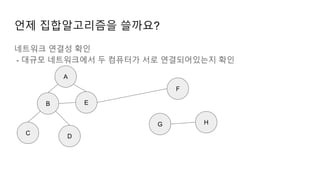
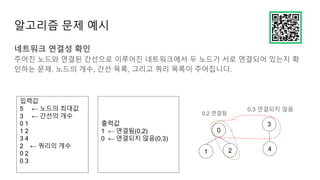
언제 집합알고리즘을 쓸까요?
이미지세그멘테이션
- 각 이미지를 의미있는 부분으로 분할
- 아래 이미지를 보면 이미지에서 각 객체마다 분할해서 다른색을 칠하고 있음






![집합의 연산 find(경로압축의 과정)
find연산을 하는 노드가 루트노드 일 경우, 루트노드를 반환
find연산을 하는 노드가 루트노드가 아닐 경우, 자신의 부모노드를 find(해당 노드의
부모노드)로 설정
1
2
3
4
5
실제 함수 호출 과정
find(5) , disjoint[5] = disjoint[4] 이후, disjoint[5] 반환
> find(4), disjoint[4] = disjoint[3] 이후, disjoint[4] 반환
> find(3), disjoint[3] = disjoint[2] 이후, disjoint[3] 반환
> find(2), disjoint[2] = disjoint[1] 이후, disjoint[2] 반환
> find(1), 루트노드 이므로 disjoint[1] 반환](https://image.slidesharecdn.com/c10-240616074604-d430b436/85/C-10-10-320.jpg)
![집합의 연산 find(경로압축의 실제동작 1)
1
2
3
4
5
①
②
③
④
루트노드 확인
1
2
3
4
5
① disjoint[2] = disjoint[1]
1 2 3 4 5
1 1
2
1
4
1
현재노드
부모노드
3
1
② disjoint[3] = disjoint[2]
③ disjoint[4] = disjoint[3]
④ disjoint[5] = disjoint[4]
① ② ③ ④
disjoint](https://image.slidesharecdn.com/c10-240616074604-d430b436/85/C-10-11-320.jpg)
![집합의 연산 find(경로압축의 실제동작 1, 결론적으로)
1
2
3
4
5
① disjoint[2] = disjoint[1]
1 2 3 4 5
1 1
2
1
4
1
현재노드
부모노드
3
1
② disjoint[3] = disjoint[2]
③ disjoint[4] = disjoint[3]
④ disjoint[5] = disjoint[4]
① ② ③ ④
disjoint
1
2 3 4 5](https://image.slidesharecdn.com/c10-240616074604-d430b436/85/C-10-12-320.jpg)
![집합의 연산 find(경로압축의 실제동작 2)
1
2
4
루트노드 확인
3 5
6
7
①
②
③
1
2
4
3 5
6
7
① disjoint[2] = disjoint[1]
② disjoint[6] = disjoint[2]
③ disjoint[7] = disjoint[6]](https://image.slidesharecdn.com/c10-240616074604-d430b436/85/C-10-13-320.jpg)
![집합의 연산 find(경로압축의 실제동작 2)
1
2
4
3 5
6
7
① disjoint[2] = disjoint[1]
② disjoint[6] = disjoint[2]
③ disjoint[7] = disjoint[6]
1
2
4
3 5 6 7
경로 압축을 했다고, 루트노드를 제외한 모든 노드의 깊이가 1이 되는건 아님.
find 연산을 할 때, 루트노드를 찾는 과정에서 거쳐간 노드들의 경로가 압축 됨
경로압축을 적용하면 find연산의 시간복잡도는 O(1)에 가까워짐](https://image.slidesharecdn.com/c10-240616074604-d430b436/85/C-10-14-320.jpg)
















![[211] 네이버 검색과 데이터마이닝](https://cdn.slidesharecdn.com/ss_thumbnails/211-150915001301-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[0326 석재호]상호배타적 집합의 처리](https://cdn.slidesharecdn.com/ss_thumbnails/0326-1301223278-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[0326 석재호]상호배타적 집합의 처리](https://cdn.slidesharecdn.com/ss_thumbnails/0326-110327100525-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)












![[D2 CAMPUS] 2016 한양대학교 프로그래밍 경시대회 문제풀이](https://cdn.slidesharecdn.com/ss_thumbnails/random-161228045003-thumbnail.jpg?width=640&height=640&fit=bounds)


![[연세대 모르고리즘] 프로그래밍 경진대회 문제 풀이](https://cdn.slidesharecdn.com/ss_thumbnails/2017-170615112359-thumbnail.jpg?width=640&height=640&fit=bounds)


![[HBM-PPT]코딩 테스트 제대로 공부해서 합격하는 방법 강의자료 공유 합니다.](https://cdn.slidesharecdn.com/ss_thumbnails/hbm-ppt-250108000809-ffe0ca62-thumbnail.jpg?width=640&height=640&fit=bounds)






